




 本文介绍了Apriori算法在关联规则分析中的应用,详细讲解了支持度、置信度和提升度的概念,并通过R语言的arules和arulesViz包展示了如何进行关联规则挖掘及可视化。文中以"啤酒与尿布"的经典案例解释关联分析,并提供了R代码实例。
本文介绍了Apriori算法在关联规则分析中的应用,详细讲解了支持度、置信度和提升度的概念,并通过R语言的arules和arulesViz包展示了如何进行关联规则挖掘及可视化。文中以"啤酒与尿布"的经典案例解释关联分析,并提供了R代码实例。
经典段子——“啤酒与尿布”,即很多年轻父亲在购买孩子尿布的时候,顺便为自己购买啤酒。关联分析中,最经典的算法Apriori算法在关联规则分析领域具有很大的影响力。
项集
这是一个集合的概念,每个事件即一个项,如啤酒是一个项,尿布是一个项,若干项的集合称为项集,如{尿布,啤酒}是一个二元项集。
关联规则
关联规则一般记为 \(X\rightarrow Y\) 的形式,X称为先决条件,右侧为相应的关联结果,用于表示出数据内隐含的关联性。如:关联规则 尿布 \(\rightarrow\) 啤酒成立,则表示购买尿布的消费者往往会购买啤酒,即两个商品的购买之间具有一定的关联性。
关联性的强度,由关联分析中的三个核心概念——支持度、置信度和提升度来控制和评价。
以例子说明:假设有10000个消费者,购买尿布的有1000人,购买啤酒的有2000人,购买面包的有500人,其中同时购买了尿布和啤酒的有800人,同时购买了尿布和面包的有100人。
支持度
支持度(Support)指在所有项集中{X,Y}出现的可能性,即项集中同时包含X和Y的概率,。
我们通过设定一个最小阈值来判断关联是否有意义,当概率大于或等于该最小阈值时有意义(有关联)。
在上面例子中P{尿布,啤酒} = 800/10000=8%,P{尿布,面包} = 100/10000=1%。我们设定最小阈值5%,即大于5%说明有关联。则尿布和啤酒有关联,而尿布和面包无关联。
置信度
置信度(Confidence)表示,在关联规则的先决条件X发生的条件下,关联结果Y发生的概率 \(P(Y|X)=\frac{P(XY)}{P(X)}\) 。
相似的我们也需要设定一个最小阈值,来判断概率关联是否有意义
上述例子中,即在购买尿布后,购买啤酒的概率。P(啤酒|尿布) = (800/10000)/(1000/10000) = 800/1000=80%。而在购买啤酒后再去购买尿布的概率为P(尿布|啤酒)=(800/10000)/(2000/10000)=800/2000=40%。假设我们以70%作为最小阈值,即强相关规则:尿布 \(\rightarrow\) 啤酒
提升度
提升度(lift),表示在含有X的条件下同时含有Y的可能性与没有X的条件下项集中含有Y的可能性之比 \(\frac{P(Y|X)}{P(Y)}\) 。提升度可以看作是置信度的一种互补指标。
如1000个消费者,购买茶叶的500人,这500人中有450人同时购买了咖啡,则 P(咖啡|茶叶) = (450/1000)/(500/1000)=450/500=90%,很高的置信度。而另外500个没有购买茶叶的人中,也有450人购买了咖啡,即1000人中有900人购买了咖啡。则P(咖啡|未购买茶叶)=(450/1000)/(500/1000)=450/500=90%。同样也是90%的置信度,所以购买咖啡和与购买茶叶之间,无关联相互独立。其提升度 \(\frac{P(咖啡|茶叶)}{P(咖啡)} = \frac{90\%}{900/1000} = 1\) 。同样的,上面例子中,\(\frac{P(啤酒|尿布)}{P(啤酒)} = \frac{80\%}{2000/10000} = 4\) 。
当提升度的值为1时表示X和Y相互独立,X对Y的发生没有提升作用。提升度的值>1时,且提升度值越大,表示X对Y的发生的提升作用越大,即关联性越大。
关联分析的基本算法步骤
- 筛选出满足支持度最小阈值的项集——频繁项集。
- 从频繁项集中筛选出满足最小置信度的所有规则。
Apriori算法
Apriori算法采用迭代的方法,目标是找到最大K项频繁项集,如{A,B}即K = 2,{A,B,C}即K = 3。
以下面例子作为说明: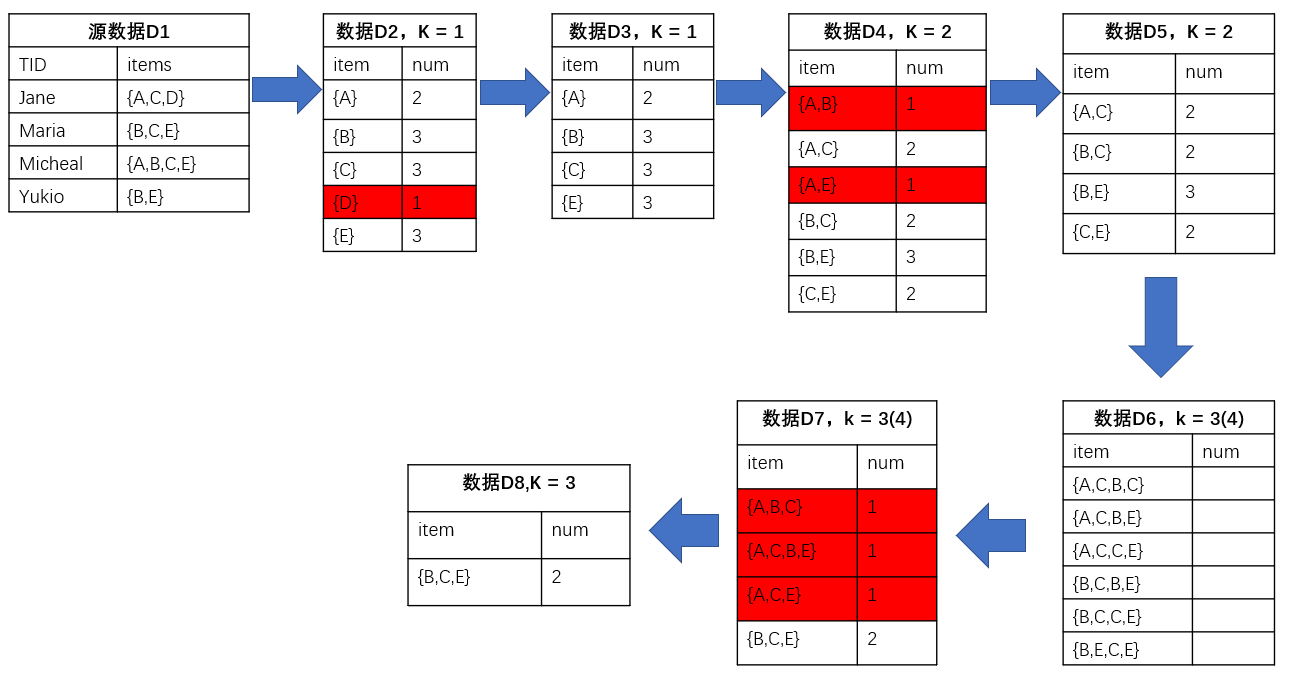
Apriori算法第一步,首先K=1的项集为D2,然后扫描D1,得到D2中的num(频数),最后得到了满足K = 1,最小阈值2的频繁项集D3。将D3中的item自由组合,得到K=2的项集D4中的item,然后扫描D1,得到D4中的num,然后根据阈值2,去掉不满足阈值的item,最后得到了满足K=2,最小阈值2的频繁项集D5。如此迭代,直到无法找到K+1的频繁项集,如本例子中,K最大时K = 3,即无法找到K+1 = 4的项集,因为K = 4的项集{A,B,C,E}的频数为1,小于最小阈值,不满足条件,即不是频繁项集。
所以Apriori算法,迭代找到最大K项频繁项集,每一次迭代都扫描一次源数据集。
R的实现
R中有两个专用于关联分析的包—— arules 和 arulesViz
- arules:用于关联规则的数字化生成,提供了Apriori和Eclat这两种挖掘关联规则和频繁项集算法的实现函数
- arulesViz:arules包的扩展包,提供了关联规则和频繁项集可视化技术,使得关联分析从算法运行到结果呈现一体化
Apriori算法之apriori函数
apriori(data, parameter = NULL, appearance = NULL, control = NULL)参数:
- data:事务型数据或可以强制转化为事务型数据(如,二进制矩阵或数据框)的对象
- parameter:APparameter类(该类包含使用挖掘算法的挖掘参数,如最小支持度)或命名列表对象。
- appearance:对先决条件X(lhs)和关联结果Y(rhs)中具体包含哪些项进行限制。如,设置lhs=beer,将仅输出lhs中含有啤酒这一项
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









