



 本文探讨了字节与字符串之间的转换方法,通过实例演示了不同编码下字符的字节表示,并介绍了如何通过编码规范实现正确转换,避免乱码。
本文探讨了字节与字符串之间的转换方法,通过实例演示了不同编码下字符的字节表示,并介绍了如何通过编码规范实现正确转换,避免乱码。
思考下面两个问题,想问下pByte的长度是多少,以及sStr的值是多少?
string s = "刘宇";
byte[] pByte = System.Text.Encoding.Default.GetBytes(s);
string sStr = System.Text.Encoding.Default.GetString(pByte, 2 ,2);
string s = "Hello!";
byte[] pByte = System.Text.Encoding.Default.GetBytes(s);
string sStr = System.Text.Encoding.Default.GetString(pByte, 2 ,2);
这两个问题其实不难,都知道一个汉字占用两个字节,而一个英文字母占用1个字节,所以第一个的答案是4和“宇”,第二个的答案是6和"ll",可以进一步将pByte打印出来:
foreach (var sElement in pByte)
{
Console.WriteLine(sElement.ToString());
}
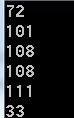
这次都看清楚了,每一个字节都是一个10进制表示的数字,其实在计算机中所有的东西都是都是0和1这两个的组合,当然这里不包括计算机中的硬件,好吧我承认,我在这里乱说。
字节并不是最小单位,一个字节等于8bit,也即是说一个字节占了8位,而每一个位上不是0就是1,我们可以每个字节用8位的二进制表示:
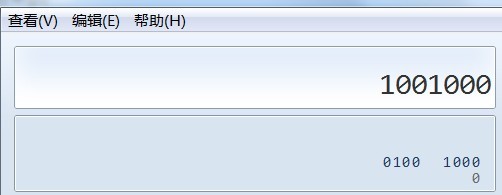
8位二进制的转成10进制就是72,也就是英文字母的H。
对于我这样的懒人,可以用下面的代码:
foreach (var sElement in pByte)
{
Console.WriteLine(String.Format("十进制{0},二进制{1}", sElement, System.Convert.ToString(pByte[0],2)));
}

既然我们看到的这些字符(英文字母或者汉字,或者火星文)在计算机都是这种0,1,1,0的玩意,这些东西也只有计算机能识别吧,如何转成我们自己能识别的?这就需要编码了吧,在System.Text.Encoding下面有很多中编码规范,我个人猜测,计算机就是根据这种编码规范,去某一个地方去查找这些对应的东西,然后将结果呈现给我们,当然这个仅仅是猜测而已。
我们一般读写文本什么的,看到的已经是编码过后的东西了,我们称之为字符,一旦编码选择的不当就可能出现乱码,可以看下面的代码:
string s = "Hello!"; byte[] pByte = System.Text.Encoding.Default.GetBytes(s); string sStr = System.Text.Encoding.Default.GetString(pByte, 2 ,2); foreach (var sElement in pByte) { Console.WriteLine(String.Format("十进制{0},二进制{1}", sElement, System.Convert.ToString(pByte[0],2))); } String sUTF=System.Text.Encoding.UTF32.GetString(pByte); Console.WriteLine(sUTF);
这个打印出来的就是乱码,我就不在这里截图了,可以亲自去测试。
#region 转换指定字节数组为字符串
/// <summary>
/// 转换指定字节数组为字符串 /// </summary>
/// <param name="ByteGet">字节数组Byte[]</param>
/// <param name="myEncoding">编码方式</param>
/// <returns></returns>
private static string getStringFromByteArray(Byte[] ByteGet,Encoding myEncoding)
{
int i,lngCount;
StringBuilder aTemp = new StringBuilder(10000);
lngCount = ByteGet.Length;
for(i = 0;i<lngCount;i+= 10000)
{
aTemp.Append(myEncoding.GetString(ByteGet,i,(lngCount>=i+10000?10000:lngCount - i)));
}
if(i<=lngCount)
{
aTemp.Append(myEncoding.GetString(ByteGet,i,(lngCount - i)));
}
return aTemp.ToString();
}
#endregion
通常情况下,我们很少跟字节打交道,但是有的时候使用字节,我们会得到意向不到的效果,在socket编程的时候,如果我们传输的数据比较大,那么我们就可以采用字节的方式,将内容分段传输,这样就会有好的体验,还有当我们在解析某一个协议的时候也会用到字节。
得到了字节,那么我们就可以对字节进行修改或者随即操作,这也是我们在使用socket的字节流的时候碰到的,如果使用NetworkStream流,我们只能按照顺序去读取,这也是这两者的一个区别。
暂时就写这么多吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









