



 本文深入探讨了二分查找算法、二叉查找树及B+树的原理与应用,解析了它们在数据库索引中的角色,强调了索引在提升查询效率的同时,也增加了DML操作的资源开销。
本文深入探讨了二分查找算法、二叉查找树及B+树的原理与应用,解析了它们在数据库索引中的角色,强调了索引在提升查询效率的同时,也增加了DML操作的资源开销。
1.二分查找算法
二分查找法的时间复杂度为Ο(log2n)。大家如果有兴趣可以去验证一下这个结果,这里我就不做解释了。
我们具体来感受一下二分查找法有多强大,假设:集合里面有40亿个元素,排序方式为从左往右,依次递增,我们最多需要查找log2 4000000000 = 32次,就可以在40亿个元素里面找到我们需要的元素 。说点题外话:虽然二分查找法很强大,但这并不意味着二分查找法适用于任何场景,因为我们在为业务场景选择算法时,除了算法的时间复杂度,还要考虑空间复杂度,而且越复杂的程序越是容易发生异常。最主要的是二分查找法只能用于依次递增或依次递减的有序集合。
2.二叉查找树
二叉查找树是采用二分查找法的思维把数据按规则组装成一个树形结构。所以平衡二叉树的深度为Ο(log2n),即从根节点到离它最远的叶子节点的距离为Ο(log2n),二叉查找树的数据结构如下图所示(注:本文所有图片来自其它文章):
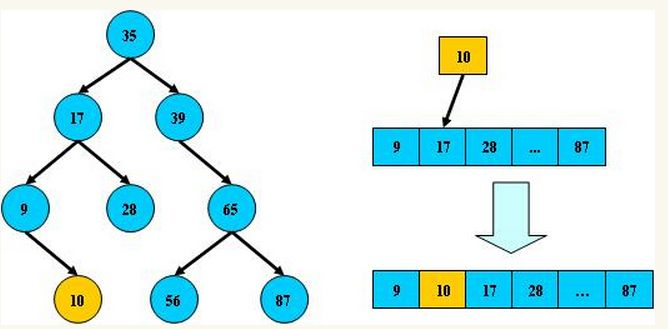
总结平衡二叉树特点:
(1)非叶子节点最多拥有两个子节点;
(2)非叶子节值大于左边子节点、小于右边子节点;
(3)树的左右两边的层级数相差不会大于1;
(4)没有值相等重复的节点;
3.索引的数据结构——B+树
数据库的索引结构采用的是B+树。B+树是一种二叉查找树,而二叉查找树又是根据二分查找法的思维组装的一种数据结构。所以,这就是为什么先要介绍二分查找法和二叉查找树的原因。之前我们已经知道了二分查找法的查找效率很高,为什么不用二叉查找树作为索引的数据结构呢?难道B+树的查找速度要比二叉查找树还要快吗?当然不是,我们先来了解一下B+树,
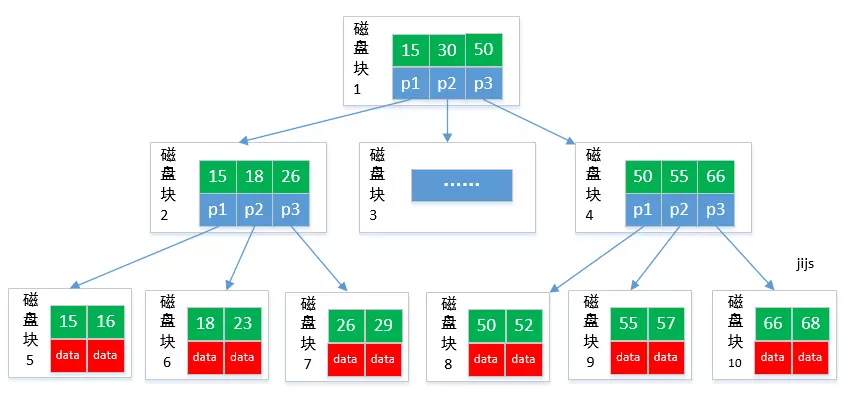
从上图可知,一个磁盘块即为一个节点,并且数据只存放在叶子结点,非叶子节点存放的是磁盘块的地址,通过磁盘块的地址找到存放数据的磁盘块,这样大大的减少了磁盘的IO操作次数,所以就节省了大量的查找时间。因为程序是在内存里面运行,而数据是放在磁盘块里面的,寻找磁盘块的时间远远大于程序的运行时间,所以B+树的主要功能实际是减少磁盘的IO操作次数。
4.总结
1.索引可以提高查询效率,但是因为索引的数据结构是一种二叉查找树,这就要求这棵树的结构必须是有规律的,所以,每次进行DML操作的时候,数据库都要重新去维护这棵树的结构,这就导致了DML操作时会产生大量的资源开销。所以,请根据实际业务场景来决定是否使用索引。
2.事物型数据库的索引原理除了B+树数据结构,还有其它数据结构,但那些数据结构我就没了解过了。大家如果有兴趣可以了解一下。
3.除了事物型数据库,还有一种分析型数据库,比如数据仓库,数据集市,这些就涉及到大数据的技术了。
4.本来我以为我可以写好这篇文章,但最后才发现好多地方都解释得不清楚,请多多包涵!

















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









