






 本文介绍如何使用hierarchyviewer工具优化安卓应用布局性能,包括设备刷成开发版、root操作、运行hierarchyviewer工具等步骤,并通过工具显示的布局结构、控件加载速度等信息找到并优化慢点。
本文介绍如何使用hierarchyviewer工具优化安卓应用布局性能,包括设备刷成开发版、root操作、运行hierarchyviewer工具等步骤,并通过工具显示的布局结构、控件加载速度等信息找到并优化慢点。
初学安卓,优化一个布局的性能是我接到的一个任务,网上略查了一下hierarchyviewer可以做到这个事,于是开始搞起。
hierarchyviewer使用过程:
1.手机需要刷成开发版(稳定版里面的响应hierarchyviewer的某服务没有开启)
2.手机root(不是必须)
以上两步可以root精灵来完成,我这的设备是小米三,一些新出的机型root不了
3.安卓sdk目录下的tools/hierarchyviewer即为我们要使用的工具
4.打开手机app
5.运行hierarchyviewer,截图如下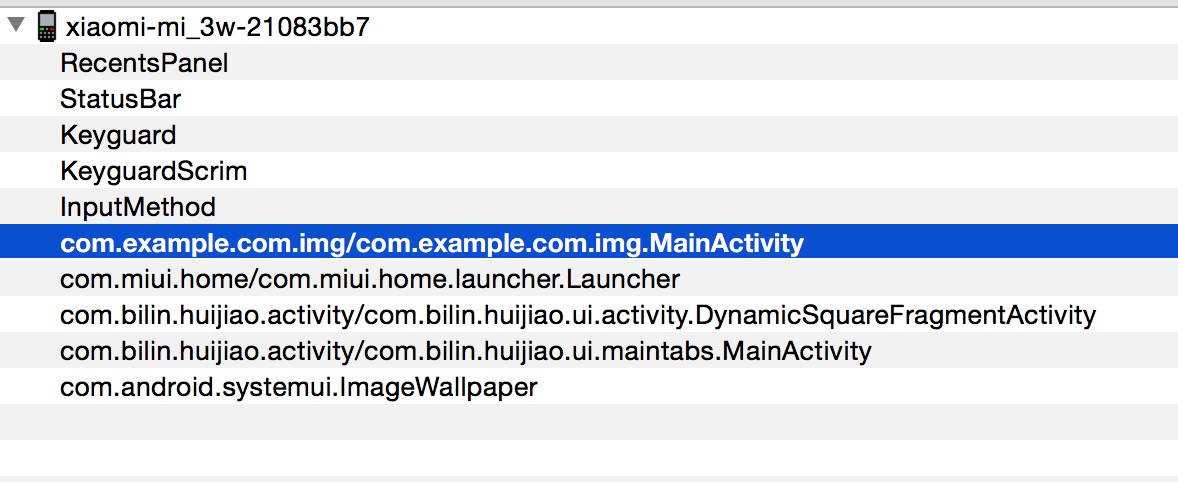
6.选中上图蓝色表示自己要查看布局的activity,截图如下:
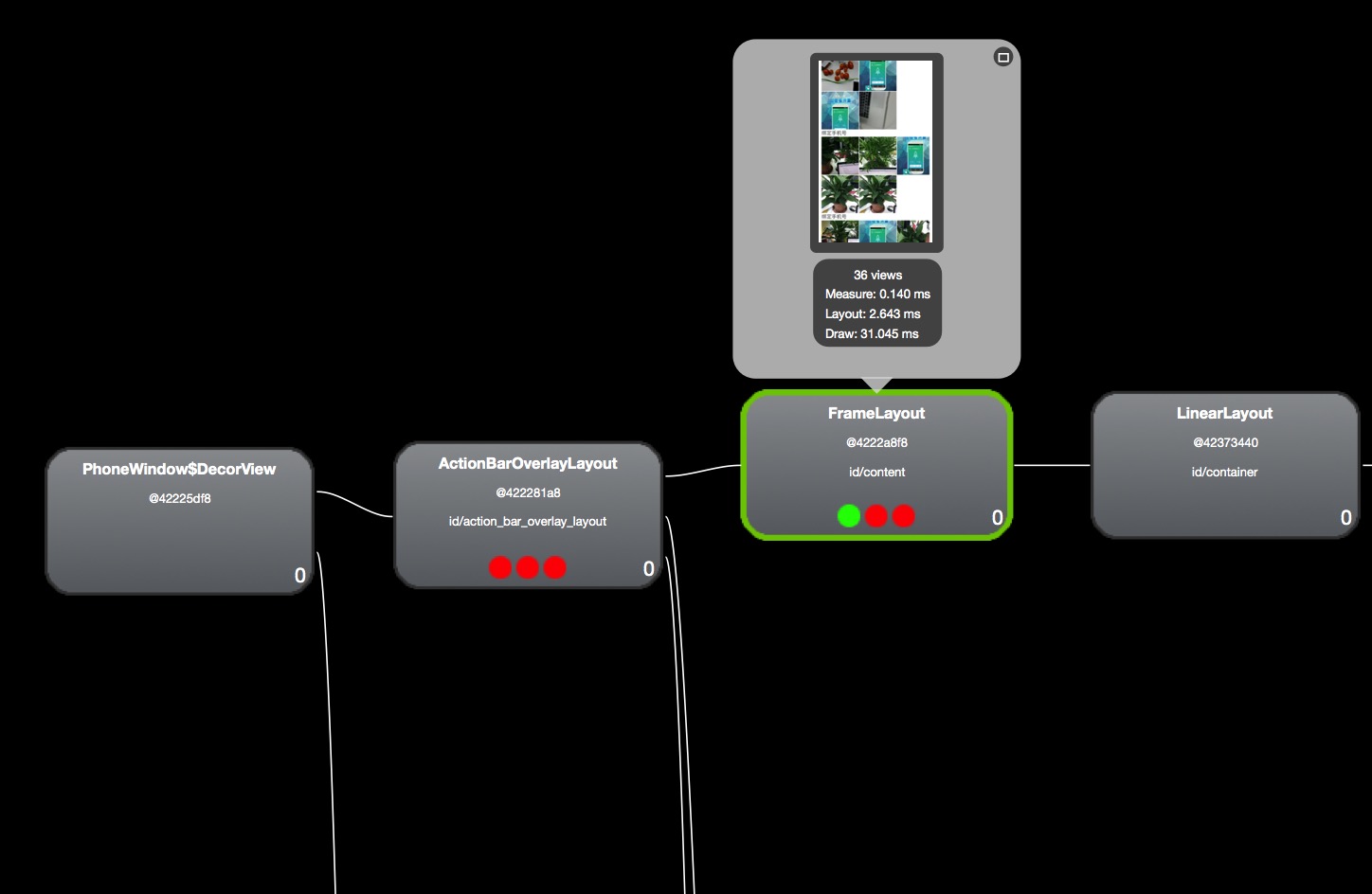
7.上图表示自己的布局结构,会显示id,层次结构,同时还可以显示控件的加载速度,截图如下:
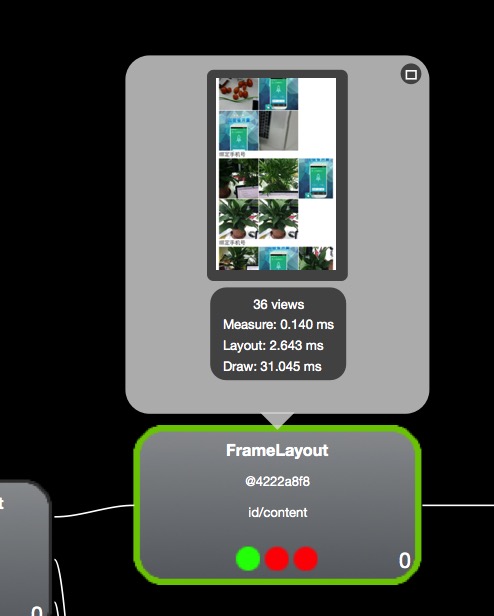
8.上图中分别显示了,元素测量,布局,和展示需要的时间(过程中可能会被调用多次),三个圆形的图标,分别对应
上面的三个步骤所耗时间的长短比例,绿色表示正常,红色表示极慢,黄色表示一般(小于50%控件的同一属性)
接下来准备去找到具体慢的点,接下来做相应地优化,初学安卓,记录一下。

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









