






 本文介绍使用Python爬虫技术抓取中国天气网的城市最低气温及古诗文网的古诗词信息,包括BeautifulSoup4和正则表达式的应用,并实现数据可视化。
本文介绍使用Python爬虫技术抓取中国天气网的城市最低气温及古诗文网的古诗词信息,包括BeautifulSoup4和正则表达式的应用,并实现数据可视化。
4.1.中国天气网
网址:http://www.weather.com.cn/textFC/hb.shtml
解析:BeautifulSoup4
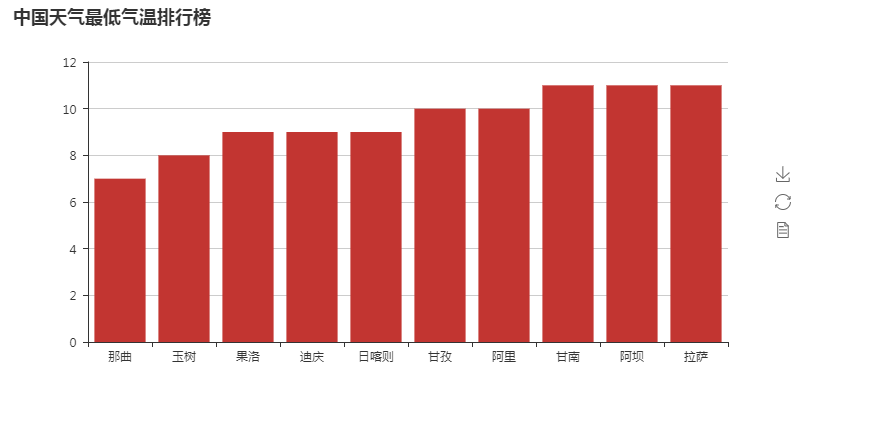
爬取所有城市的最低天气
import requests from bs4 import BeautifulSoup import html5lib def parse_page(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36', } response = requests.get(url) text = response.content.decode('utf-8') # 需要用到html5lib解析器,去补全html标签 soup = BeautifulSoup(text,'html5lib') conMidtab = soup.find('div',class_='conMidtab') tables = conMidtab.find_all('table') for table in tables: trs = table.find_all('tr')[2:] for index,tr in enumerate(trs): tds = tr.find_all('td') city_td = tds[0] if index == 0: city_td = tds[1] city = list(city_td.stripped_strings)[0] temp_td = tds[-2] temp = list(temp_td.stripped_strings)[0] print({'city':city,'temp':temp}) def main(): url_list = [ 'http://www.weather.com.cn/textFC/hb.shtml', 'http://www.weather.com.cn/textFC/db.shtml', 'http://www.weather.com.cn/textFC/hd.shtml', 'http://www.weather.com.cn/textFC/hz.shtml', 'http://www.weather.com.cn/textFC/hn.shtml', 'http://www.weather.com.cn/textFC/xb.shtml', 'http://www.weather.com.cn/textFC/xn.shtml', 'http://www.weather.com.cn/textFC/gat.shtml', ] for url in url_list: parse_page(url) if __name__ == '__main__': main()
对爬取的数据进行可视化处理
- 按温度对城市进行排名
- 取前10个
- 生成直方图
代码:
import requests from bs4 import BeautifulSoup import html5lib from pyecharts import Bar ALL_DATA = [] def parse_page(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36', } response = requests.get(url) text = response.content.decode('utf-8') # 需要用到html5lib解析器,去补全html标签 soup = BeautifulSoup(text,'html5lib') conMidtab = soup.find('div',class_='conMidtab') tables = conMidtab.find_all('table') for table in tables: trs = table.find_all('tr')[2:] for index,tr in enumerate(trs): tds = tr.find_all('td') city_td = tds[0] if index == 0: city_td = tds[1] city = list(city_td.stripped_strings)[0] temp_td = tds[-2] temp = list(temp_td.stripped_strings)[0] # print({'city':city,'temp':int(temp)}) ALL_DATA.append({'city':city,'temp':int(temp)}) def main(): url_list = [ 'http://www.weather.com.cn/textFC/hb.shtml', 'http://www.weather.com.cn/textFC/db.shtml', 'http://www.weather.com.cn/textFC/hd.shtml', 'http://www.weather.com.cn/textFC/hz.shtml', 'http://www.weather.com.cn/textFC/hn.shtml', 'http://www.weather.com.cn/textFC/xb.shtml', 'http://www.weather.com.cn/textFC/xn.shtml', 'http://www.weather.com.cn/textFC/gat.shtml', ] for url in url_list: parse_page(url) #按天气最低进行排序,并只取10个 ALL_DATA.sort(key=lambda data:data['temp']) data = ALL_DATA[0:10] #分别取出所有城市和温度 cities = list(map(lambda x:x['city'],data)) temps = list(map(lambda x:x['temp'],data)) chart = Bar("中国天气最低气温排行榜") chart.add('',cities,temps) chart.render('temperature.html') if __name__ == '__main__': main()
结果:
4.2.古诗文网
网址:https://www.gushiwen.org/default_1.aspx
解析:正则表达式
代码
import requests import re def parse_page(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36', } response = requests.get(url,headers) text = response.text titles = re.findall(r'<div\sclass="cont">.*?<b>(.*?)</b>',text,re.DOTALL) dynasties = re.findall(r'<p class="source">.*?<a.*?>(.*?)</a>',text,re.DOTALL) authors = re.findall(r'<p class="source">.*?<a.*?>.*?<a.*?>(.*?)</a>',text,re.DOTALL) contents_tags = re.findall(r'<div class="contson" .*?>(.*?)</div>',text,re.DOTALL) contents = [] for content in contents_tags: content = re.sub(r'<.*?>','',content) contents.append(content.strip()) poems = [] for value in zip(titles,dynasties,authors,contents): title,dynasty,author,content = value poem = [ { 'title':title, 'dynasties':dynasty, 'authors':author, 'contents':content } ] poems.append(poem) for poem in poems: print(poem) print('---'*80) def main(): url = 'https://www.gushiwen.org/default_1.aspx' for page in range(1,101): url = url = 'https://www.gushiwen.org/default_%s.aspx'%page parse_page(url) if __name__ == '__main__': main()

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









