






 本文介绍了一种使用Python的requests和json库抓取在线作业信息的方法,通过爬虫技术从特定网站抓取学生的作业详情,包括学号、姓名、作业标题、提交时间和作业链接,然后将这些信息保存为CSV文件。此外,还详细说明了如何为每个学生创建单独的文件夹,并下载其作业网页。
本文介绍了一种使用Python的requests和json库抓取在线作业信息的方法,通过爬虫技术从特定网站抓取学生的作业详情,包括学号、姓名、作业标题、提交时间和作业链接,然后将这些信息保存为CSV文件。此外,还详细说明了如何为每个学生创建单独的文件夹,并下载其作业网页。
第一部分:
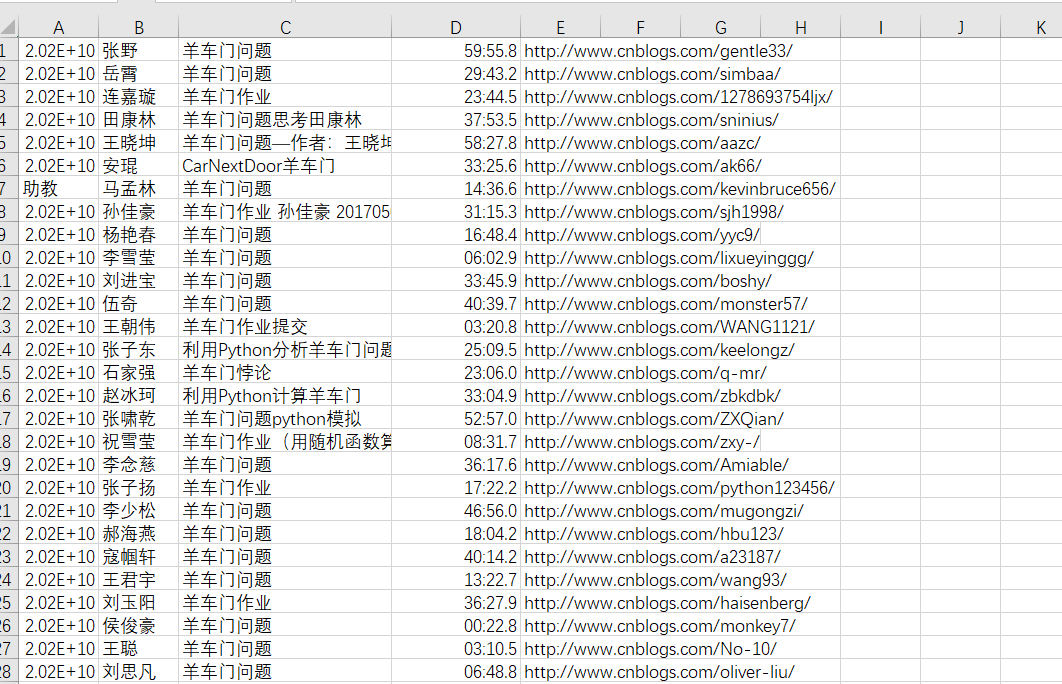
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,
http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,
http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
第二部分:
在生成的 hwlist.csv 文件的同文件夹下,创建一个名为 hwFolder 文件夹,为每一个已提交作业的同学,新建一个以该生学号命名的文件夹,将其作业网页爬去下来,并将该网页文件存以学生学号为名,“.html”为扩展名放在该生学号文件夹中。
大致明白这个网络爬虫的目的是为了将网站上的信息的进行一部分的爬取,对信息分类便于查看,相当于Excel中进行分类,便于查找
代码
import requests as r import json import time try: a = r.get('https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543758681318') except: print('Error') def cd(): b = json.loads(a.text)['data'] e = '' for i in b: c = (str(i['StudentNo']) + ',' + str(i['RealName']) + ',' + str(i['Title']) + ',' + str(i['DateAdded'].replace('T',' ')) + ',' + str(i['BlogUrl'])).replace('None','助教') e = e + c + '\n' print(e) with open('E:\\hwlist.csv','w') as f: f.write(e) while True: cd() time.sleep(2500)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









