






 本文介绍了一种在Spark中实现按key分目录输出的方法,并详细解释了如何通过自定义MultipleTextOutputFormat类来达到这一目的。同时,文章还提供了具体的代码示例,展示了如何设置输出格式为NullWritable以排除不需要的key值。
本文介绍了一种在Spark中实现按key分目录输出的方法,并详细解释了如何通过自定义MultipleTextOutputFormat类来达到这一目的。同时,文章还提供了具体的代码示例,展示了如何设置输出格式为NullWritable以排除不需要的key值。
最近接到一个需求,需要对spark的结果分目录输出,百度之后找到了解决方案,大多都是spark 按照key分目录输出,
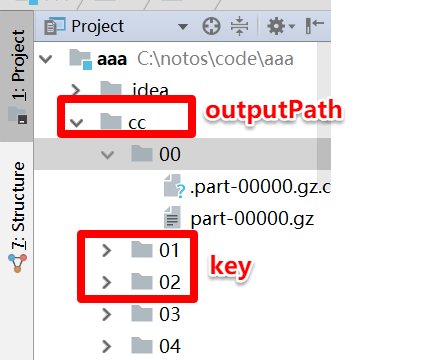
但是在文件当中,会把key也输出出来,在这里以key作为目录是想建hive表时把 01,02当做分区的,结果文件中不需要保存key值。其实在mr中也有类似需求,我的输出只要key-value对中的value,不要key,在mr中是怎么解决的呢,将输出设置为NullWritable,spark里也是这样的,上代码
多目录输出,首先要创建一个继承MultipleTextOutputFormat的新类,重写其generateFileNameForKeyValue 方法,方法的返回值就是动态生成的目录的名称,这里的返回值是用value计算的,
class RDDMultipleTextOutputFormat[K, V]() extends MultipleTextOutputFormat[K, V]() { //private val output:TextOutputFormat[String, String] = null override def generateFileNameForKeyValue(key: K, value: V, name: String) : String = { val dt = Utils.getDt(value.toString.split("\t",-1)(2)) s"$dt/$name" } }
定义好RDDMultipleTextOutputFormat后,就可以保存rdd结果了
lines.saveAsHadoopFile(
outPath,
classOf[NullWritable], //这里定义的是NullWritable,那么pairRdd 就应该是RDD[NullWritable,String]类型的
classOf[String],
classOf[RDDMultipleTextOutputFormat[_, _]],classOf[GzipCodec])
这样输出结果就会按照自己的要求分目录输出了,classOf[GzipCodec] 指定输出结果的压缩方式

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









