






 本文通过Python实现了一个基于生产者和消费者模型的豆瓣图片爬虫。该爬虫能够抓取推荐相册中的图片,并通过多线程提高下载效率。
本文通过Python实现了一个基于生产者和消费者模型的豆瓣图片爬虫。该爬虫能够抓取推荐相册中的图片,并通过多线程提高下载效率。
豆瓣图片的抓取:在python中实现生产者和消费者模型的实现,大家可以参考这篇文章 http://www.bkjia.com/Pythonjc/978391.html
个人认为是讲的比较易懂的,只要看看仿写几个例子,感觉这一块就差不多了。下面的代码并没有抓取豆瓣相册的全部,这是找了一个推荐较多的抓取来玩玩,也只抓取前面20页,每页有30张图片,所以可以根据这个去跟新url。维护了一个list来保存图片的url,一个消费者函数来下载图片,一个生产者函数来取图片的url , 下面看代码:
# _*_coding:utf-8_*_ import urllib2 import cookielib from bs4 import BeautifulSoup import re import time import threading start = start_time = time.ctime() s = [] max_length = 30 condition = threading.Condition() class Producer(threading.Thread): def run(self): for i in xrange(20): condition.acquire() if len(s) == max_length: print 's is full' condition.wait() request_url = 'https://site.douban.com/widget/public_album/86320/?start=%s' % (i*30) #推荐相册的url headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36', } opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookielib.CookieJar())) response = urllib2.Request(request_url, headers=headers) html = opener.open(response) soup = BeautifulSoup(html) img_urls = soup.find_all('a', {'class': 'album_photo'}) for item in img_urls: p = re.compile(r'src="(.*?)"') img_url = p.search(str(item.find('img'))).group(1) #图片的url s.append(img_url) print 'producer somthing' condition.notify() class Consumer(threading.Thread): def run(self): count = 0 while True: if condition.acquire(): if not s: print 's is empty wait' condition.wait() img_url = s.pop(0) print 'consumer something' with open('E:\\douban\\%s.jpg' %count, 'wb') as fp: try: response_img = urllib2.urlopen(img_url).read() #下载图片 fp.write(response_img) except Exception: print 'error' count += 1 condition.notify() condition.release() t1 = Producer() c1 = Consumer() t1.start() c1.start()
嗯, 差不多就这样,大家还可以多开几个线程,使得下载速度更快点,毕竟如果抓取大量的图片的话,io操作会比较耗时。
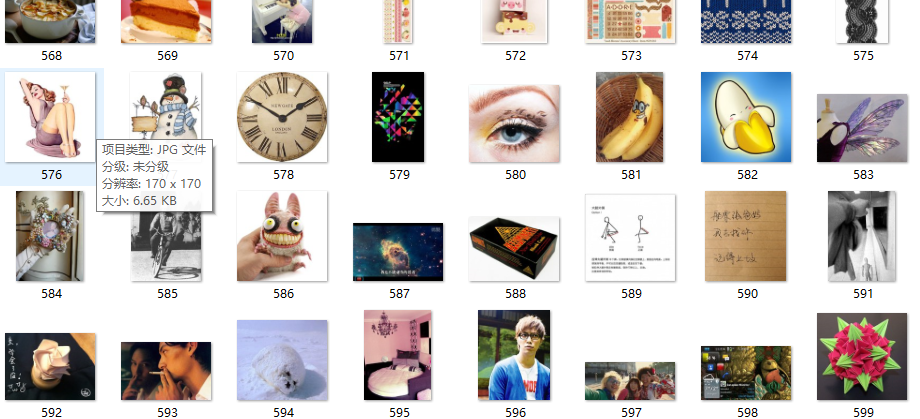
这是图片的部分截图:


















 1788
1788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









