






 本文探讨了通过策略模式实现排序算法的灵活性,并介绍了如何利用依赖注入来降低代码间的耦合度,以适应需求变化。
本文探讨了通过策略模式实现排序算法的灵活性,并介绍了如何利用依赖注入来降低代码间的耦合度,以适应需求变化。
设想这样一个需求,我们需要为自己的框架提供一个负责排序的组件。目前需要实现的是冒泡排序算法和快速排序算法,根据“面向接口编程”的思想,我们可以为这些排序算法提供一个统一的接口ISort,在这个接口中有一个方法Sort(),它能接受一个object数组参数。对数组进行排序后,返回该数组。接口的定义如下:
public interface ISort
{
void Sort(ref object[] beSorted);
}
其类图如下:
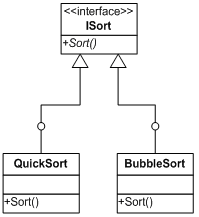
然而一般对于排序而言,排列是有顺序之分的,例如升序,或者降序,返回的结果也不相同。最简单的方法我们可以利用if语句来实现这一目的,例如在QuickSort类中:
public class QuickSort:ISort
{
private string m_SortType;
public QuickSort(string sortType)
{
m_SortType = sortType;
}
public void Sort(ref object[] beSorted)
{
if (m_SortType.ToUpper().Trim() == “ASCENDING”)
{
//执行升序的快速排序;
}
else
{
//执行降序的快速排序;
}
}
}
当然,我们也可以将string类型的SortType定义为枚举类型,减少出现错误的可能性。然而仔细阅读代码,我们可以发现这样的代码是非常僵化的,一旦需要扩展,如果要求我们增加新的排序顺序,例如字典顺序,那么我们面临的工作会非常繁重。也就是说,变化产生了。通过分析,我们发现所谓排序的顺序,恰恰是排序算法中最关键的一环,它决定了谁排列在前,谁排列在后。然而它并不属于排序算法,而是一种比较的策略,后者说是比较的行为。
如果仔细分析实现ISort接口的类,例如QuickSort类,它在实现排序算法的时候,需要对两个对象作比较。按照重构的做法,实质上我们可以在Sort方法中抽取出一个私有方法Compare(),通过返回的布尔值,决定哪个对象在前,哪个对象在后。显然,可能发生变化的是这个比较行为,利用“封装抽象”的原理,就应该为该行为建立一个专有的接口ICompare,然而分别定义实现升序、降序或者字典排序的类对象。
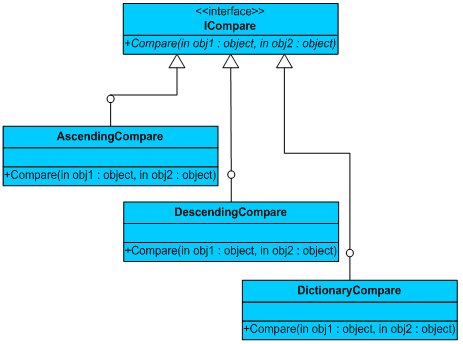
我们在每一个实现了ISort接口的类构造函数中,引入ICompare接口对象,从而建立起排序算法与比较算法的弱耦合关系(因为这个关系与抽象的ICompare接口相关),例如QuickSort类:
public class QuickSort:ISort
{
private ICompare m_Compare;
public QuickSort(ICompare compare)
{
m_Compare= compare;
}
public void Sort(ref object[] beSorted)
{
//实现略
for (int i = 0; i < beSorted.Length - 1; i++)
{
if (m_Compare.Compare(beSorted[i],beSorted[i+1))
{
//略;
}
}
//实现略
}
}
最后的类图如下:
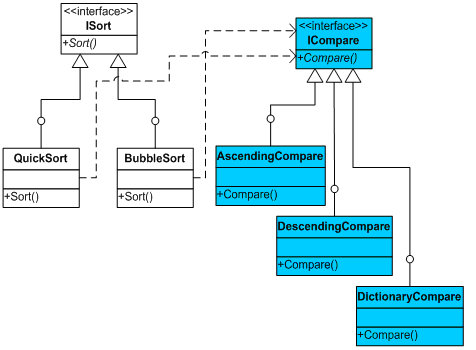
通过对比较策略的封装,以应对它的变化,显然是Stategy模式的设计。事实上,这里的排序算法也可能是变化的,例如实现二叉树排序。由于我们已经引入了“面向接口编程”的思想,我们完全可以轻易的添加一个新的类BinaryTreeSort,来实现ISort接口。对于调用方而言,ISort接口的实现,同样是一个Strategy模式。此时的类结构,完全是一个对扩展开发的状态,它完全能够适应类库调用者新需求的变化。
再以PetShop为例,在这个项目中涉及到订单的管理,例如插入订单。考虑到访问量的关系,PetShop为订单管理提供了同步和异步的方式。显然,在实际应用中只能使用这两种方式的其中一种,并由具体的应用环境所决定。那么为了应对这样一种可能会很频繁的变化,我们仍然需要利用“封装变化”的原理,建立抽象级别的对象,也就是IOrderStrategy接口:
public interface IOrderStrategy
{
void Insert(PetShop.Model.OrderInfo order);
}
然后定义两个类OrderSynchronous和OrderAsynchronous。类结构如下:
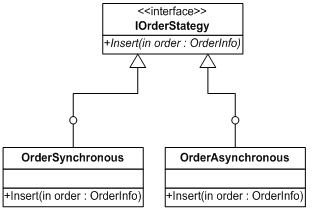
在PetShop中,由于用户随时都可能会改变插入订单的策略,因此对于业务层的订单领域对象而言,不能与具体的订单策略对象产生耦合关系。也就是说,在领域对象Order类中,不能new一个具体的订单策略对象,如下面的代码:
IOrderStrategy orderInsertStrategy = new OrderSynchronous();
在Martin Fowler的文章《IoC容器和Dependency Injection模式》中,提出了解决这类问题的办法,他称之为依赖注入。不过由于PetShop并没有使用诸如Sping.Net等IoC容器,因此解决依赖问题,通常是利用配置文件结合反射来完成的。在领域对象Order类中,是这样实现的:
public class Order
{
private static readonly IOrderStategy orderInsertStrategy = LoadInsertStrategy();
private static IOrderStrategy LoadInsertStrategy()
{
// Look up which strategy to use from config file
string path = ConfigurationManager.AppSettings[”OrderStrategyAssembly”];
string className = ConfigurationManager.AppSettings[”OrderStrategyClass”];
// Load the appropriate assembly and class
return (IOrderStrategy)Assembly.Load(path).CreateInstance(className);
}
}
在配置文件web.config中,配置如下的Section:
<add key=”OrderStrategyAssembly” value=”PetShop.BLL”/>
<add key=”OrderStrategyClass” value=”PetShop.BLL.OrderSynchronous”/>
这其实是一种折中的Service Locator模式。将定位并创建依赖对象的逻辑直接放到对象中,在PetShop的例子中,不失为一种好方法。毕竟在这个例子中,需要依赖注入的对象并不太多。但我们也可以认为是一种无奈的妥协的办法,一旦这种依赖注入的逻辑增多,为给程序者带来一定的麻烦,这时就需要一个专门的轻量级IoC容器了。
写到这里,似乎已经脱离了“封装变化”的主题。但事实上我们需要明白,利用抽象的方式封装变化,固然是应对需求变化的王道,但它也仅仅能解除调用者与被调用者相对的耦合关系,只要还涉及到具体对象的创建,即使引入了工厂模式,但具体的工厂对象的创建仍然是必不可少的。那么,对于这样一些业已被封装变化的对象,我们还应该充分利用“依赖注入”的方式来彻底解除两者之间的耦合。

















 9569
9569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









