



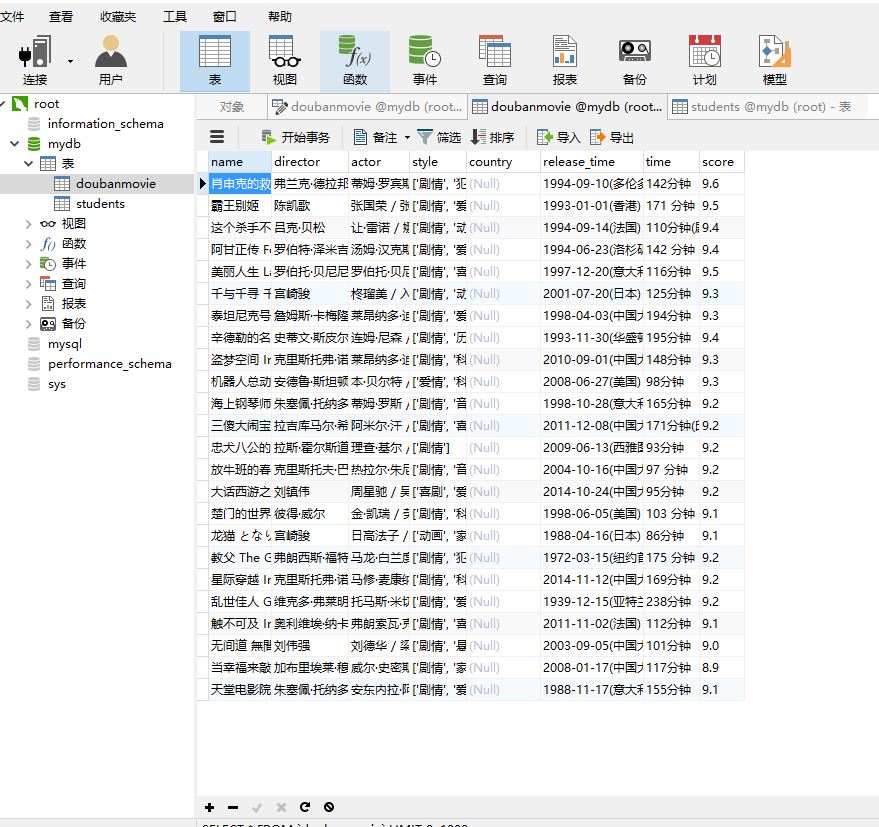
 本文介绍了一个使用Python实现的豆瓣电影Top250数据爬取项目。通过requests和lxml库获取网页信息,并利用正则表达式解析数据,最后将抓取到的数据如电影名称、导演、演员等信息存入MySQL数据库。
本文介绍了一个使用Python实现的豆瓣电影Top250数据爬取项目。通过requests和lxml库获取网页信息,并利用正则表达式解析数据,最后将抓取到的数据如电影名称、导演、演员等信息存入MySQL数据库。
import requests from lxml import etree import re import pymysql import time conn= pymysql.connect(host='localhost',user='root',passwd='root',db='mydb',port=3306,charset='utf8') cursor=conn.cursor() headers={ #'User-Agent':'Nokia6600/1.0 (3.42.1) SymbianOS/7.0s Series60/2.0 Profile/MIDP-2.0 Configuration/CLDC-1.0' 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } def get_movie_url(url): html=requests.get(url,headers=headers) selector=etree.HTML(html.text) movie_hrefs=selector.xpath('//div[@class="hd"]/a/@href') for movie_href in movie_hrefs: get_movie_info(movie_href) time.sleep(2) def get_movie_info(url): html=requests.get(url,headers=headers) print("开始") selector=etree.HTML(html.text) try: name=selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0] director=selector.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')[0] actors=selector.xpath('//*[@id="info"]/span[3]/span[2]')[0] actor=actors.xpath('string(.)') #style=selector.xpath('//*[@id="info"]/span[5]/text()')[0] style=re.findall('<span property="v:genre">(.*?)</span>',html.text,re.S) #爬取制片国家不成功 #country=re.findall('<span class="pl">制片国家/地区:</span>(.*?)<b',selector.text,re.S)[0] #country=re.findall('<span property="v:genre">.*?地区:</span>(.*?)<b',selector.text,re.S)[0] #countrys=selector.xpath('//*[@id="info"]/br[4]')[0] #country=selector.xpath('//*[@id="info"]/text()[2]')[0] release_time=re.findall('上映日期:</span>.*?>(.*?)</span>',html.text,re.S)[0] time=re.findall('片长:</span>.*?>(.*?)</span>',html.text,re.S)[0] score=selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0] cursor.execute("insert into doubanmovie (name,director,actor,style,release_time,time,score)values(%s,%s,%s,%s,%s,%s,%s)",(str(name),str(director),str(actor),str(style),str(release_time),str(time),str(score))) except IndexError: pass if __name__=='__main__': urls=['https://movie.douban.com/top250?start={}'.format(str(i)) for i in range(0,25,25)] for url in urls: get_movie_url(url) time.sleep(2) conn.commit() print("结束")

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









