



一、SELECT查询

查询的执行顺序:
1、FROM and JOIN
首先执行FROM子句和后续连接,以确定正在查询的数据的总工作集。
left (outer) join
是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.
换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录。
right(outer) join与left (outer)join相反。
full (outer)join 全外连接
全外连接返回参与连接的两个数据集合中的全部数据,无论它们是否具有与之相匹配的行。在功能上,它等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的并操作将上述两个结果集合并为一个结果集。
cross join 交叉连接
交叉连接用于对两个源表进行纯关系代数的乘运算。它不使用连接条件来限制结果集合,而是将分别来自两个数据源中的行以所有可能的方式进行组合。数据集合中一的每个行都要与数据集合二中的每一个行分别组成一个新的行。例如,如果第一个数据源中有5个行,而第二个数据源中有4个行,那么在它们之间进行交叉连接就会产生20个行。人们将这种类型的结果集称为笛卡尔乘积。在交叉连接中没有on条件子句
inner join(inner可以省略)并不以谁为基础,它只显示符合条件的记录
2、WHERE
一旦我们有了总的工作数据集,第一次遍历时,约束被应用到各个行,并且不满足约束的行被丢弃。每个约束只能直接从from子句中请求的表访问列。查询的SELECT部分中的别名在大多数数据库中是不可访问的,因为它们可能包含依赖于尚未执行的查询部分的表达式.
3、GROUP BY
应用WHERE约束之后的其余行将根据GROUP BY子句中指定的列中的公共值分组。分组的结果是,该列中唯一值的行数最多。隐式地,这意味着您应该只在查询中包含聚合函数时才需要使用它。
4、HAVING
如果查询具有GROUP BY子句,则HAVING子句中的约束将应用于分组行,丢弃不满足约束的分组行。与WHERE子句类似,别名在大多数数据库中也不能从这一步访问。
5、SELECT
常见聚合函数 计数:COUNT()、最大值:MAX()、最小值:MIN()、平均值:AVG()、求和:SUM()
6、DISTINCT
去除重复值
7、ORDER BY
如果order by子句指定了一个顺序,那么这些行将按照指定的数据升序或降序排序。由于查询的SELECT部分中的所有表达式都已计算完毕,因此可以在此子句中引用别名。
DESC 降序 ASC 升序
8、LIMIT /OFFSET
丢弃超出限制和偏移量指定范围的行
二、操作表
1、创建表 creating tables
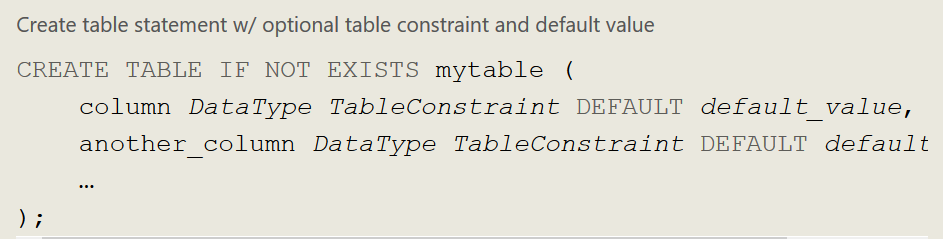
2、行操作
2.1、插入行 inserting rows

2.2、更新行 updating rows

2.3、删除行 deleting rows

3、表操作 Altering tables
3.1、增加列

如: ALTER TABLE Movies
ADD COLUMN Aspect_ratio FLOAT DEFAULT 2.39;
3.2、删除列

3.3、重命名表

3.4、删除表 dropping tables

如: DROP TABLE Movies;
参见:https://sqlbolt.com/

















 3218
3218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









