






前篇文章写了使用puppet管理500多台服务器,当然只是一部分,最主要的还是puppet脚本的编写,这个我会在以后的文章中一点一点写出来。
今天要写的是puppet的一个bug,版本是puppet 3.1.1
在使用puppet的过程中,发现一处bug,希望大家了解一下,以免出现这种情况。
刚在看一台服务器的crontab的时候,本身crontab配置如下
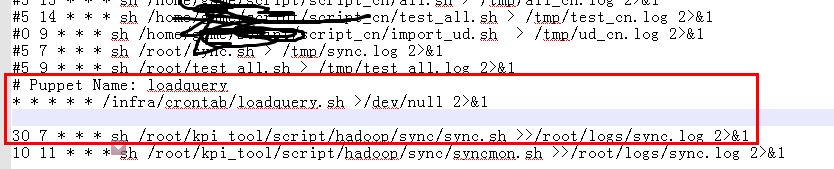
关键问题出现在红框中,
我做了个操作,先/etc/init.d/puppet stop
然后注释掉 * * * * * /infra/crontab/loadquery.sh >/dev/null 2>&1 这一行。
再/etc/init.d/puppet start
结果配置文件变成了

本来7点半执行的是sync.sh,结果现在变成了loadquery.sh,而注释的那行被移动到上面去了。造成sync.sh的crontab消失了。
也就是说puppet的对于crontab的判断机制有问题,它没有新增一条crontab配置,而是修改了紧跟在#puppet Name后面的别的crontab配置。
我猜想puppet的逻辑是这样的:
首先它会根据#Puppet Name这一条注释行去判断,紧跟着这个注释的有效的crontab语句会被修改成puppet server上定义的crontab内容。
而后我做了个测试,在注释* * * * * /infra/crontab/loadquery.sh >/dev/null 2>&1 这一行 之后,再将#puppet Name:loadquery移动到crontab文件的最下面,发现现在其他的配置都不会被修改,而* * * * * /infra/crontab/loadquery.sh >/dev/null 2>&1这一句出现在了#puppet Name:loadquery下面。这样证实了我的猜想。
puppet这样的处理方式肯定是有问题的,不应该使用注释行来作为判断标准,至少有的SA会认为注释行无影响,可能会做修改,造成意想不到的问题。
所以以后调整crontab的时候不要修改任何puppet自动配置的crontab内容,包括#puppet name这些注释行。

















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









