






 本文提供了几个简单的编程示例,包括恺撒密码的实现、格式化打印国家GDP数据、以及99乘法表的生成。通过这些例子,读者可以了解基本的编程技巧。
本文提供了几个简单的编程示例,包括恺撒密码的实现、格式化打印国家GDP数据、以及99乘法表的生成。通过这些例子,读者可以了解基本的编程技巧。
1、恺撒密码的编码
s=input('请输入明文:')
print('输出密码:',end='')
for i in s:
print(chr(ord(i)+3),end='')

2、国家名称 GDP总量(人民币亿元)
中国 ¥765873.4375
澳大利亚 ¥ 78312.4375
(国家名称左对齐,数字右对齐,千分位,2位小数)
print('国家名称 GDP总量(人民币亿元')
print('{0:' '<10}${1:,.2f}'.format('中国',765873.4375))
print('{0:' '<10}${1:,.2f}'.format('澳大利亚',78312.4375))

.format
print('输出:{0:-^20}'.format('python'))
print('输出:{0:,.3f}'.format(31415.92678))
print('十进制:{0:d}' '十六进制:{0:x}'.format(1314))

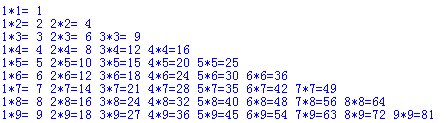
3、打出99乘法表
for x in range(1,10):
for y in range(1,x+1):
print('{}*{}={:2}'.format(y,x,x*y),end=' ')
print(' ')

















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









