






 本报告详细记录了Java面向对象程序设计实验的过程、内容、步骤与体会,包括掌握单元测试、理解面向对象三要素、初步掌握UML建模、熟悉S.O.L.I.D原则与了解设计模式等内容。实验通过编写代码、进行测试、分析问题和解决方法,旨在提升学生在Java编程方面的实践能力和理论理解。
本报告详细记录了Java面向对象程序设计实验的过程、内容、步骤与体会,包括掌握单元测试、理解面向对象三要素、初步掌握UML建模、熟悉S.O.L.I.D原则与了解设计模式等内容。实验通过编写代码、进行测试、分析问题和解决方法,旨在提升学生在Java编程方面的实践能力和理论理解。
北京电子科技学院(BESTI)
实 验 报 告
课程:Java 班级:1351班 姓名:臧文君 学号:20135115
成绩: 指导教师:娄嘉鹏 实验日期:2015.5.8
实验密级:无 预习程度: 实验时间:15:30-18:00
仪器组次: 必修/选修:选修 实验序号:二
实验名称: Java面向对象程序设计
实验目的与要求: 1.没有Linux基础的同学建议先学习《Linux基础入门(新版)》《Vim编辑器》 课程。
2.完成实验、撰写实验报告,实验报告以博客方式发表在博客园,注意实验报告重点是运行结果,遇到的问题(工具查找,安装,使用,程序的编辑,调试,运行等)、解决办法(空洞的方法如“查网络”、“问同学”、“看书”等一律得0分)以及分析(从中可以得到什么启示,有什么收获,教训等)。报告可以参考范飞龙老师的指导。
3. 严禁抄袭,有该行为者实验成绩归零,并附加其他惩罚措施。
4. 请大家先在实验楼中的~/Code目录中用自己的学号建立一个目录,代码和UML图要放到这个目录中,截图中没有学号的会要求重做,然后跟着下面的步骤练习。
实验仪器:
| 名称 | 型号 | 数量 |
| 笔记本电脑 | Lenovo Z485 | 1台 |
|
|
|
|
实验内容、步骤与体会(附纸):
一、实验内容
1. 初步掌握单元测试和TDD
2. 理解并掌握面向对象三要素:封装、继承、多态
3. 初步掌握UML建模
4. 熟悉S.O.L.I.D原则
5. 了解设计模式
二、实验步骤
(一)单元测试
1、三种代码
当我们想用程序解决问题时,要会写三种码:伪代码,产品代码和测试代码。
示例需求:我们要在一个MyUtil类中解决一个百分制成绩转成“优、良、中、及格、不及格”五级制成绩的功能。
(1)伪代码
可以用汉语写,但最好用英语写。
不要写与具体编程语言语法相关的语句(如用malloc分配内存,这样只能用C语言编程了)。
例:百分制转五分制:
如果成绩小于60,转成“不及格”
如果成绩在60与70之间,转成“及格”
如果成绩在70与80之间,转成“中等”
如果成绩在80与90之间,转成“良好”
如果成绩在90与100之间,转成“优秀”
其他,转成“错误”
(2)产品代码
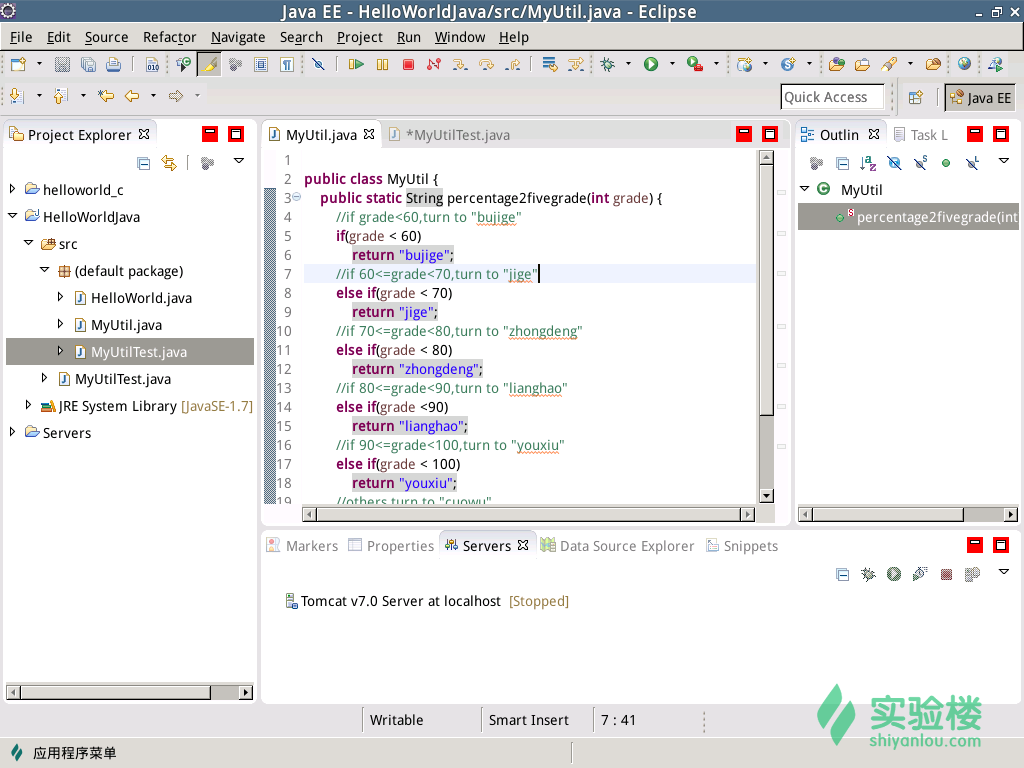
(3)测试代码
Java编程时,程序员对类实现的测试叫单元测试。
类XXXX的单元测试,我们一般写建一个XXXXTest的类
测试用例是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求。
测试时,要全面测试正常情况、异常情况和边界情况。
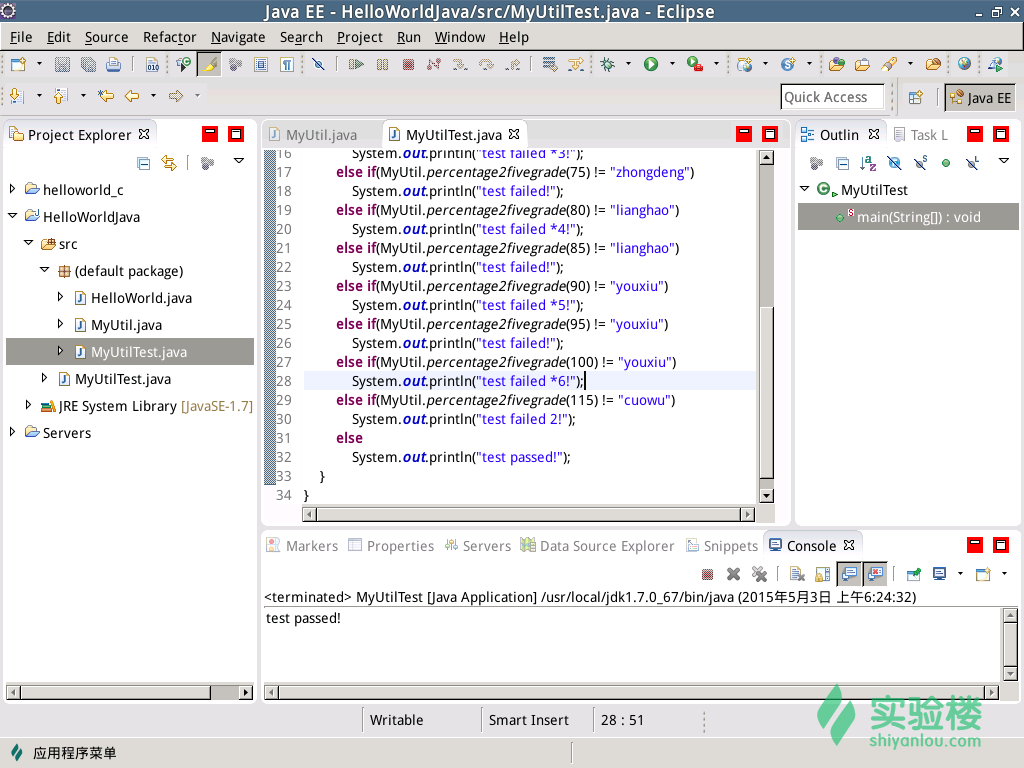
根据测试中发现的bug,修改代码如下:
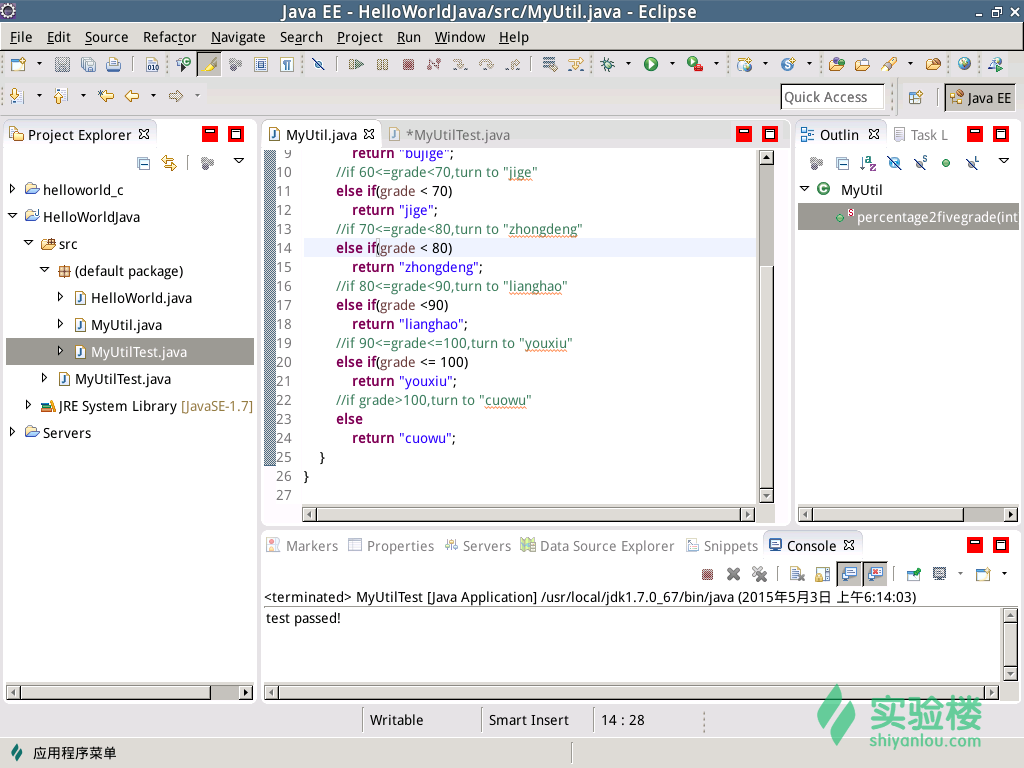
2、 TDD(Test Driven Devlopment, 测试驱动开发)
(1)TDD指先写测试代码,再写产品代码的开发方法。
(2)TDD的一般步骤如下:
a.明确当前要完成的功能,记录成一个测试列表
b.快速完成编写针对此功能的测试用例
c.测试代码编译不通过(没产品代码呢)
d.编写产品代码
e.测试通过
f.对代码进行重构,并保证测试通过(重构下次实验练习)
g.循环完成所有功能的开发
(3)示例:Java中有单元测试工具JUnit来辅助进行TDD,我们用TDD的方式把前面百分制转五分制的例子重写一次。
1.打开Eclipse,单击File->New->Java Project新建一个TDDDemo的Java项目。
2.在TDDDemo项目中,把鼠标放到项目名TDDDemo上,单击右键,在弹出的菜单中选定New->Source Folder新建一个测试目录test。
3.把鼠标放到test目录上,单击右键,在弹出的菜单中选定New->JUnit Test Case新建一个测试用例类MyUtilTest。
4.增加第一个测试用例testNormal,注意测试用例前一定要有注解@Test,测试用例方法名任意,输入测试代码。
5.输入完毕,Eclipse中出现红叉,说明代码存在语法错误,因为MyUtil类还不存在,类中的percentage2fivegrade方法也不存在。
解决:我们在TDDDemo的src目录中新建一个MyUtil的类,并实现percentage2fivegrade方法。
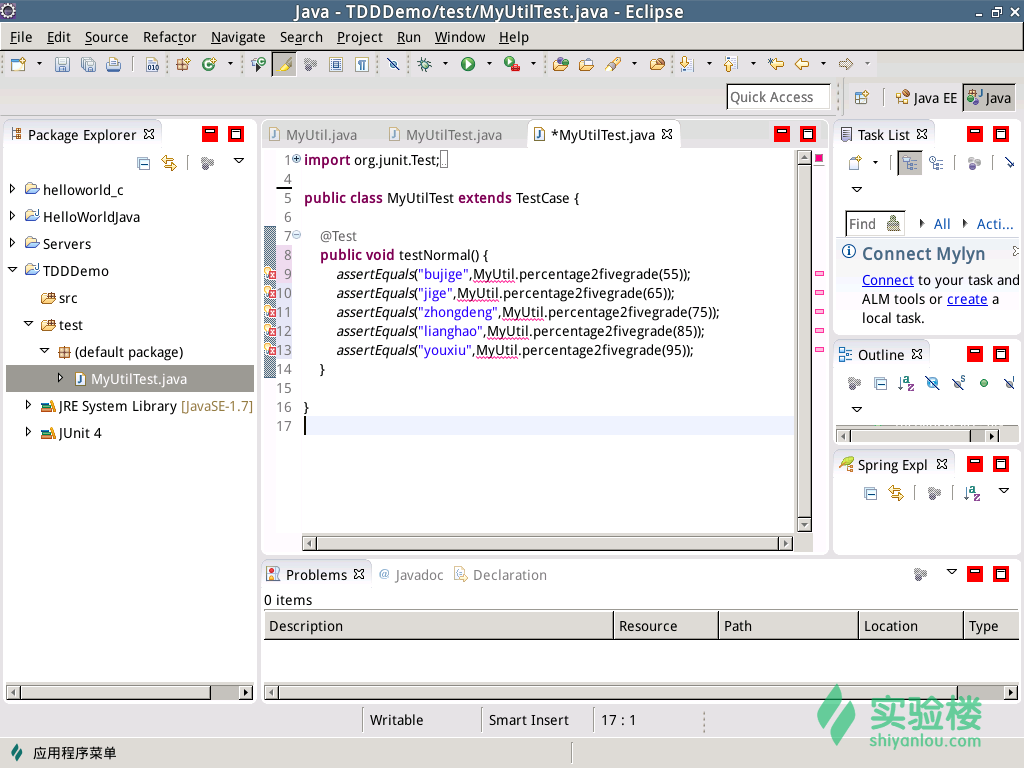
6.改正语法错误后,把鼠标放到MyUtilTest.java上,单击右键,选择Run as->JUnit Test。
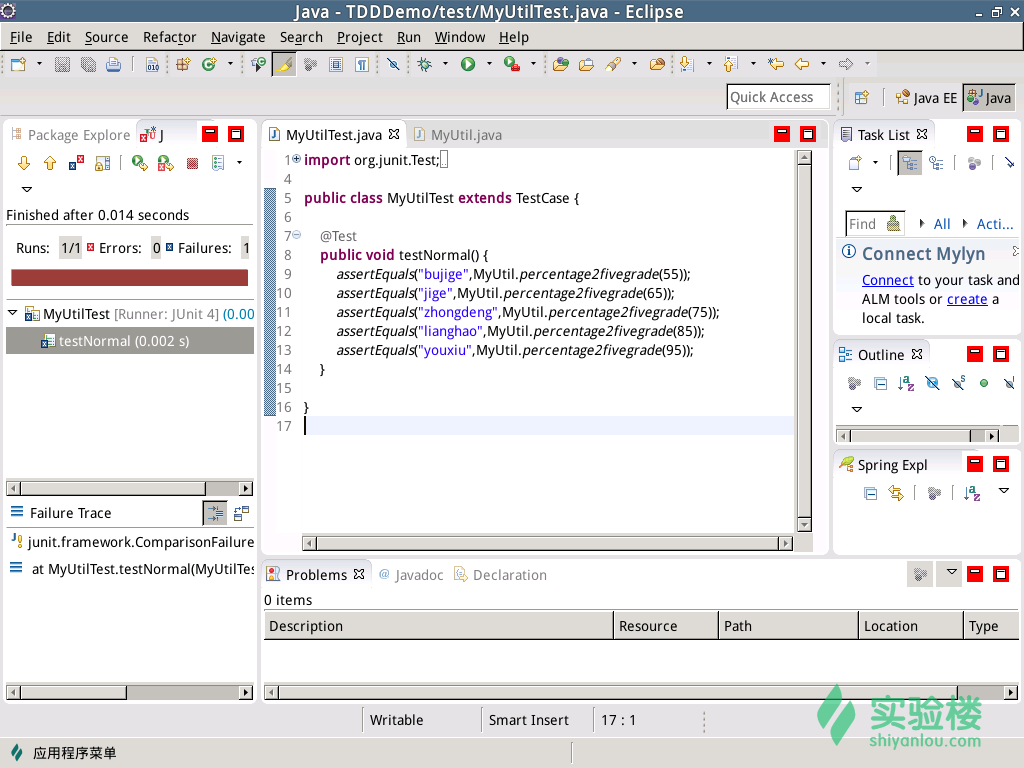
7.测试结果出现了一个红条(red bar),说明测试没通过,红条上面汇总了测试情况,运行了一个测试,没有错误,一个测试没通过。原因:测试代码第十行传入55时,期望结果是“不及格”,代码返回了“错误”。因此,修改MyUtil.Java代码,再次运行测试。测试结果出现了一个绿条(green bar),说明测试通过了。
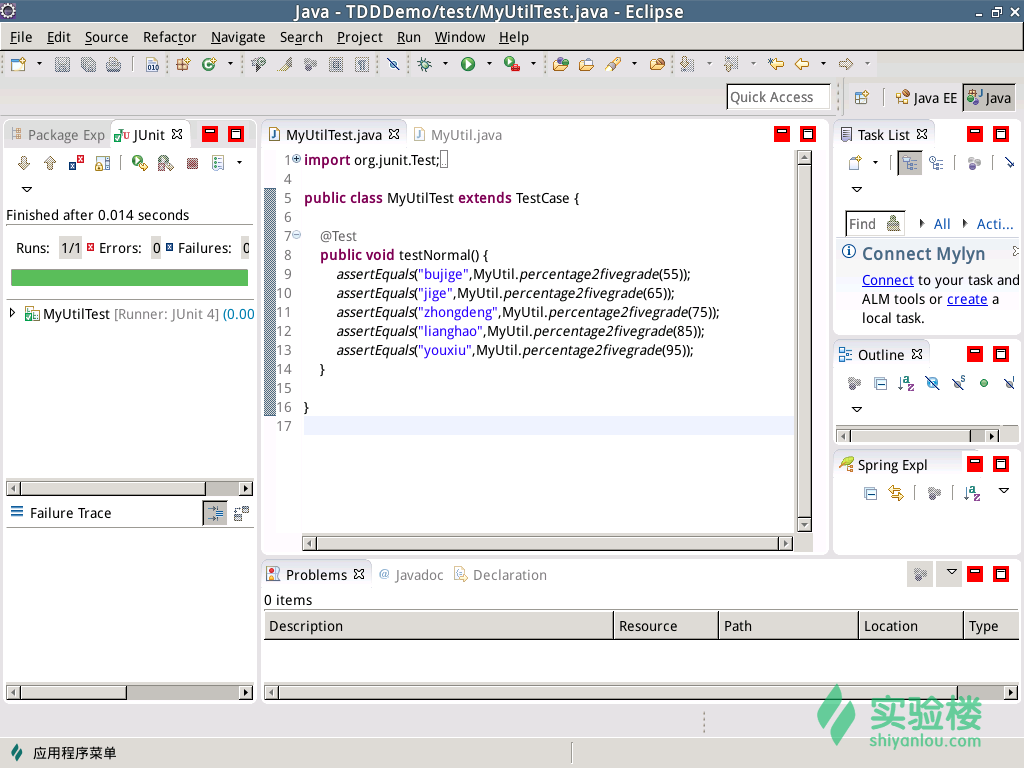
8.增加一个测试异常情况的用例testException和测试边界情况的用例testBoundary。
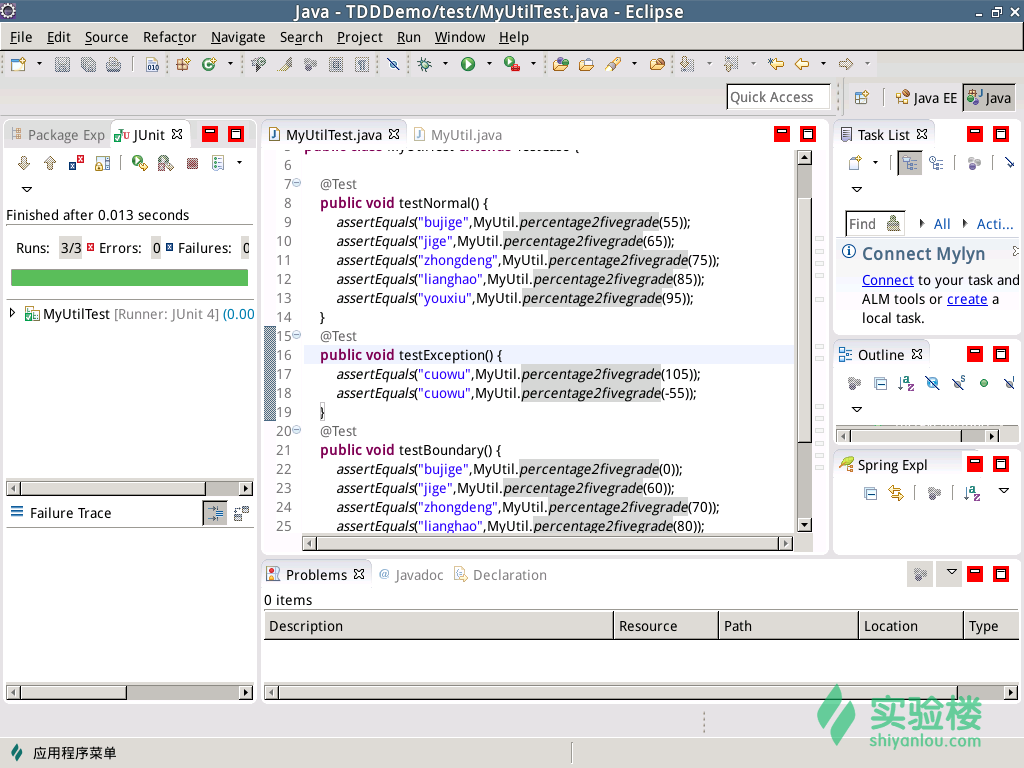
(4)TDD的目标是"Clean Code That Works",
TDD的slogan是"Keep the bar green, to Keep the code clean"。
TDD的编码节奏是:
a.增加测试代码,JUnit出现红条
b.修改产品代码
c.JUnit出现绿条,任务完成
(二)面向对象三要素
1、抽象
程序设计中,抽象包括两个方面,一是过程抽象,二是数据抽象。
2、封装、继承与多态
(1)面向对象(Object-Oriented)的三要素包括:封装、继承、多态。
(2)面向对象的思想涉及到软件开发的各个方面,如面向对象分析(OOA)、面向对象设计(OOD)、面向对象编程实现(OOP)。
OOA根据抽象关键的问题域来分解系统,关注是什么(what)。
OOD是一种提供符号设计系统的面向对象的实现过程,用非常接近问题域术语的方法把系统构造成“现实世界”的对象,关注怎么做(how),通过模型来实现功能规范。
OOP则在设计的基础上用编程语言(如Java)编码。贯穿OOA、OOD和OOP的主线正是抽象。
(3) OO三要素的第一个要素是封装,封装就是将数据与相关行为包装在一起以实现信息就隐藏。Java中用类进行封装。
封装实际上使用方法(method)将类的数据隐藏起来,控制用户对类的修改和访问数据的程度,从而带来模块化(Modularity)和信息隐藏(Information hiding)的好处;接口(interface)是封装的准确描述手段。
例:
(4) 用UML中的类图来描述类
在UML 里,一个类的属性能显示它的名字,类型,初始化值,属性也可以显示private,public,protected。 类的方法能显示它们的方法名,参数,返回类型,以及方法的private,public,protected属性。
其中:+ 表示public,# 表示 protected,- 表示 private。
UML类图中继承的表示法,是用一个带三角的直线指向父类。
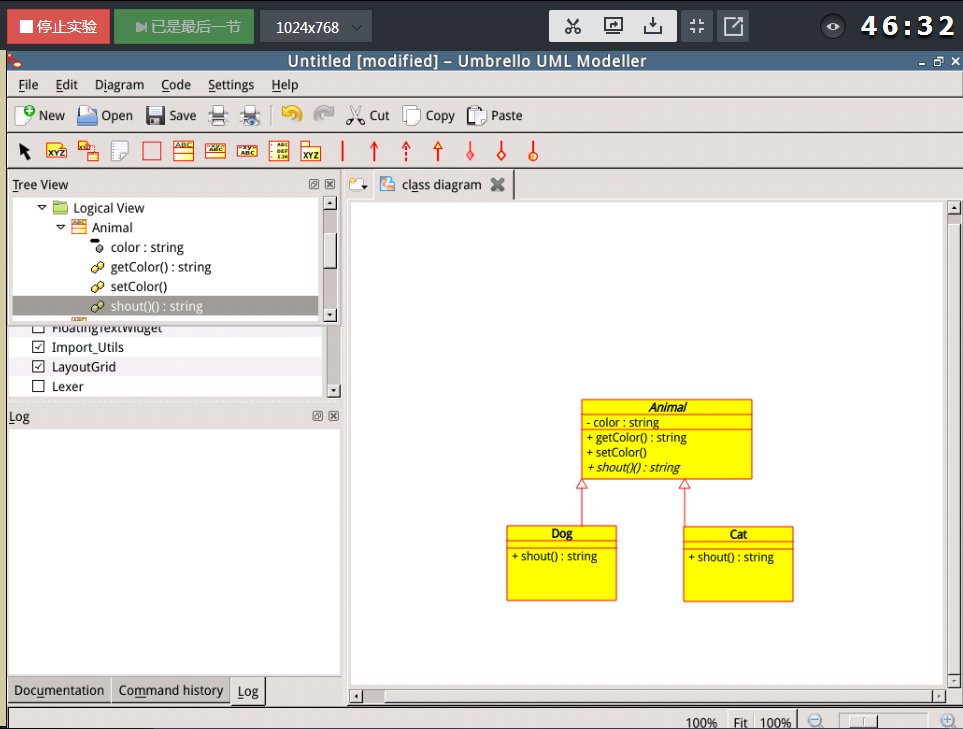
继承指一个类的定义可以基于另外一个已经存在的类,即子类基于父类,从而实现父类代码的重用。
既存类称作基类、超类、父类(base class、super class、parent class),新类称作派生类、继承类、子类(derived class、inherited class、child class)。
在Java中,当我们用父类声明引用,用子类生成对象时,多态就出现了。
(5) 另外,在Umbrello中UML图是可以转化成Java代码的,有Java代码也可以生成UML图的。
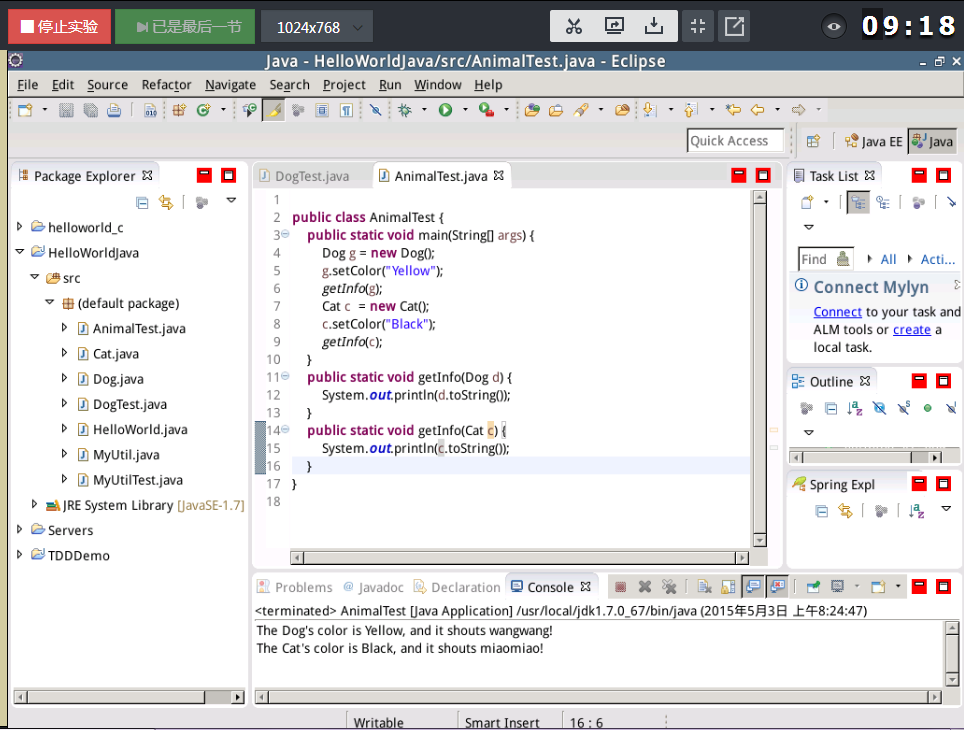
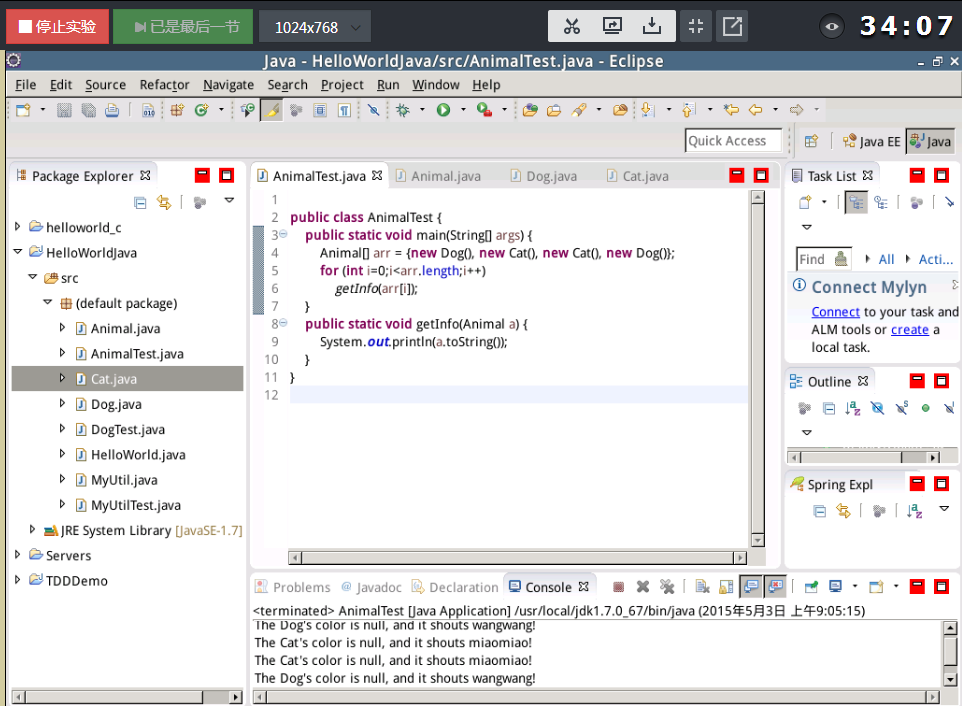
(三)设计模式初步
1、S.O.L.I.D原则
SRP(Single Responsibility Principle,单一职责原则)
OCP(Open-Closed Principle,开放-封闭原则)
LSP(Liskov Substitusion Principle,Liskov替换原则)
ISP(Interface Segregation Principle,接口分离原则)
DIP(Dependency Inversion Principle,依赖倒置原则)
(1)OCP是OOD中最重要的一个原则,OCP的内容是:
software entities (class, modules, function, etc.) should open for extension,but closed for modification.
软件实体(类,模块,函数等)应该对扩充开放,对修改封闭。
基于OCP,利用面向对象中的多态性(Polymorphic),更灵活地处理变更拥抱变化,OCP可以用以下手段实现:(1)抽象和继承,(2)面向接口编程。
(2)SRP的内容是:
There should never be more than one reason for a class to change.
决不要有一个以上的理由修改一个类。
(3)LSP的内容是:
Subtypes must be substitutable for their base types.
Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.
子类必须可以被其基类所代
使用指向基类的指针或引用的函数,必须能够在不知道具体派生类对象类型的情况下使用它
(4)ISP的内容是:
Clients should not be forced to depend upon interfaces that they do not use.
客户不应该依赖他们并未使用的接口
(5)DIP的内容是:
High level modules should not depend upon low level modules. Both should depend upon abstractions.
Abstractions should not depend upon details. Details should depend upon abstractions.
高层模块不应该依赖于低层模块。二者都应该依赖于抽象。
抽象不应该依赖于细节。细节应该依赖于抽象。
2、模式与设计模式
(1) 模式是某外在环境(Context) 下﹐对特定问题(Problem)的惯用解决之道(Solution)。
(2) 计算机科学中有很多模式:
GRASP模式;分析模式;软件体系结构模式;设计模式:创建型,结构型,行为型;管理模式: The Manager Pool 实现模式;界面设计交互模式…
3、设计模式实示例
(1)设计模式(design pattern)提供一个用于细化软件系统的子系统或组件,或它们之间的关系图,它描述通信组件的公共再现结构,通信组件可以解决特定语境中的一个设计问题。
(2)设计模式背后是抽象和SOLID原则。
(3)设计模式有四个基本要素:
Pattern name:描述模式,便于交流,存档
Problem:描述何处应用该模式
Solution:描述一个设计的组成元素,不针对特例
Consequence:应用该模式的结果和权衡(trade-offs)
(4)示例:
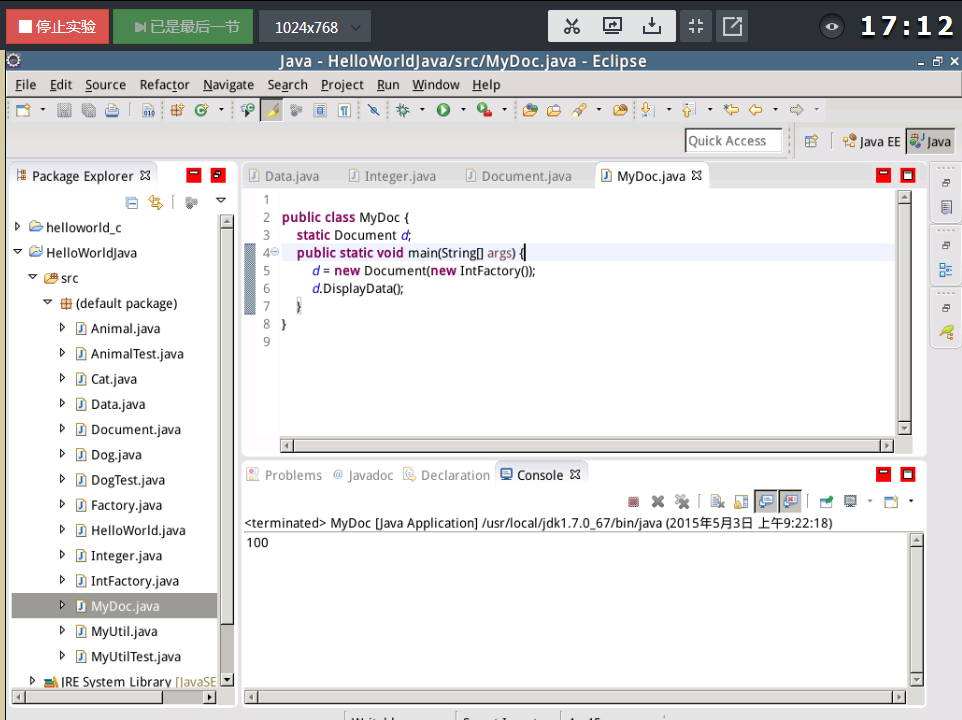
(四)使用TDD的方式设计关实现复数类Complex
步骤:
1、编写计算复数类Complex,分为加减乘除四种情况。
public class Complex {
private double m;
private double n;
public Complex(double m,double n) {
this.m = m;
this.n = n;
}
public String add(Complex b) {
Complex x = new Complex(m + b.m, n + b.n);
System.out.println("a" + "+" + "b" + "=" + x);
return "true";
}
public String minus(Complex b) {
Complex x = new Complex(m - b.m, n - b.n);
System.out.println("a" + "-" + "b" + "=" + x);
return "true";
}
public String multiply(Complex b) {
Complex x = new Complex(m * b.m - n * b.n, m*b.n + n * b.m);
System.out.println("a" + "*" + "b" + "=" + x);
return "true";
}
public String divide(Complex b) {
double d = Math.sqrt(b.m * b.m) + Math.sqrt(b.n * b.n);
Complex x = new Complex((m * b.m + n * b.n) / d,Math.round((m * b.n - n * b.m)/d));
System.out.println("a" + "/" + "b" + "=" + x);
return "true";
}
public String toString() {
String str = "";
if(n>0)
str = "(" + m + "+" + n + "i" + ")";
if(n==0)
str = "(" + m + ")";
if(n<0)
str = "(" + m + n + "i" +")";
return str;
}
}
2、编写ComplexDemo类,传入a、b两个复数的实部和虚部,调用Complex类进行计算。
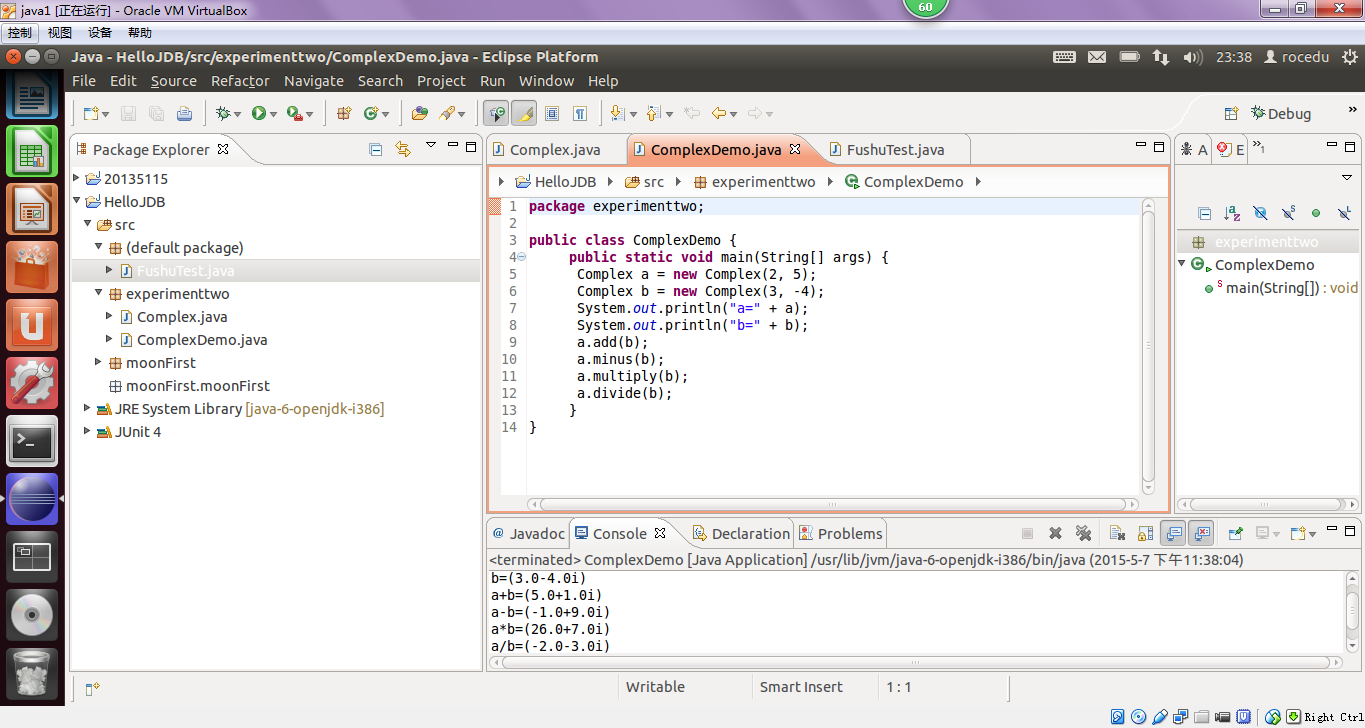
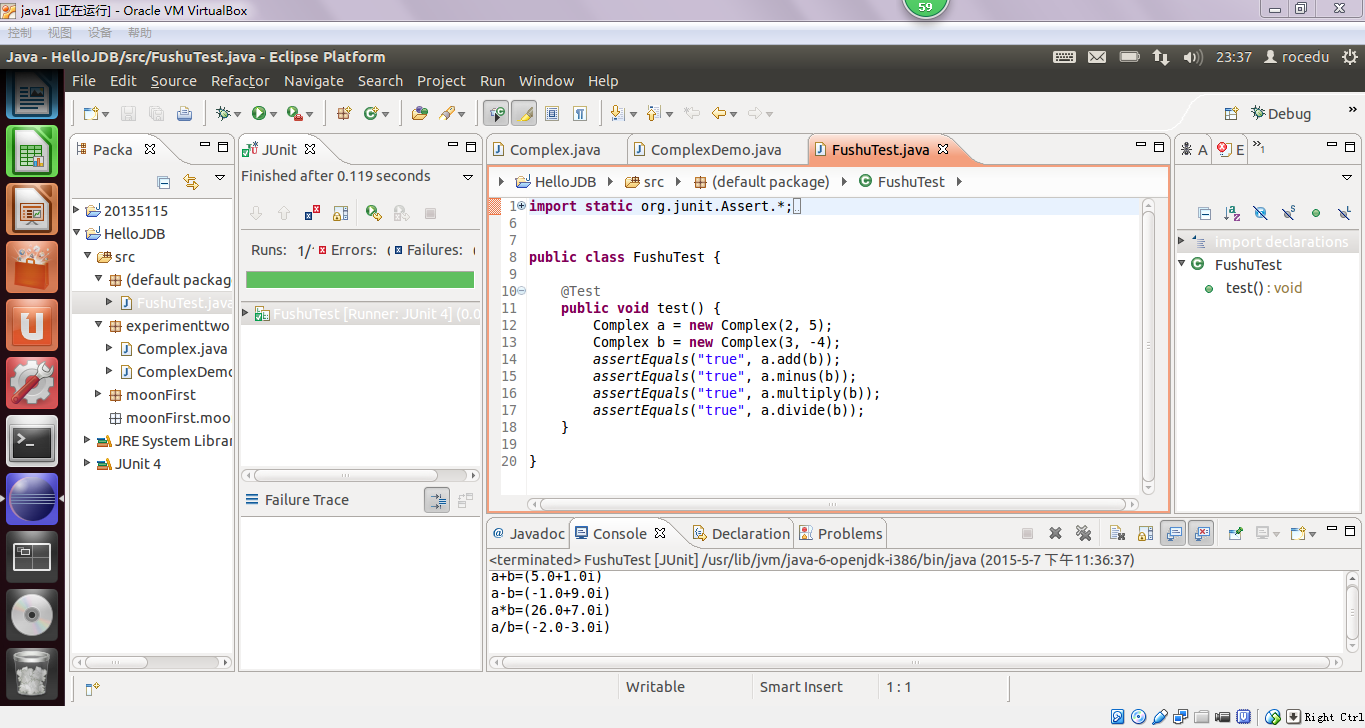
3、再编写测试代码,调试过后显示绿条和正确结果,说明代码编写正确。
三、实验体会
这次实验内容比较多,做起来花了较长的时间。
首先,通过这次实验,我学会了如何合理的编写程序,使用TDD测试驱动开发的方法,可以高效的编写程序。其次,对于任何程序,都需要编写测试代码进行检测是否存在bug,并且在检测时要全面考虑。另外,我还进一步理解了面向对象的思想,学会用UML中的类图来描述类。最后,我还了解了设计模式的S.O.L.I.D原则。
在这次实验中,也遇到了一些问题。首先,新知识比较多,学习起来比较琐碎。其次,在练习中用TDD方法编写复数类的测试代码时,自己还比较生疏,对于测试代码中的编写格式、语法掌握还有欠缺,需要在课下多练习提高。
附:
| 步骤 | 耗时 | 百分比 |
| 需求分析 | 20min | 8% |
| 设计 | 30min | 13% |
| 代码实现 | 130min | 55% |
| 测试 | 20min | 8% |
| 分析总结 | 40min | 16% |

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









