






 本文分享了一次软件工程结对项目的实践经验,包括需求分析、软件设计与核心功能实现等环节,特别展示了文本行数和字符数统计的具体代码,以及项目过程中遇到的问题与解决策略。
本文分享了一次软件工程结对项目的实践经验,包括需求分析、软件设计与核心功能实现等环节,特别展示了文本行数和字符数统计的具体代码,以及项目过程中遇到的问题与解决策略。
| 项 目 | 内 容 |
|---|---|
| 这个作业属于哪个课程 | 软件工程 |
| 这个作业的要求在哪里 | 实验四软件工程结对项目 |
| 课程学习目标 | 熟悉软件开发整体流程,提升自身能力。 |
| 本次作业在哪个具体方面帮助我们实现目标 | 第一次体验一个完整的工程 |
| 项目源码 | 源码链接 |
一、任务一:
| 项 目 | 内 容 |
|---|---|
| 点评博客链接 | 201671030124 词频统计软件项目报告 |
| GitHub链接 | 源码地址 |
| 点评内容 | 在读完你的博文后,我的建议和意见如下: 1.博文结构清晰明了,采用简化的软件工程流程,让读者一目了然; 博文内容充实,实现了老师提的要求,尤其是指定单词词频统计功能, 实现了单词词频的柱状图显示,没有投机取巧,值得我学习,但在设 计实现部分,只有文字描述,没有流程图,不能让读者直观的明白你的 设计实现,需要改进;博文排版美观大方,值得我学习。 2.你的博文结构与PSP中“任务内容”列联系比较紧密,大体流程按照PSP 中“任务内容”完成博文,但有些任务内容在博文中没有体现。 3.你的PSP中“计划共完成需要的时间”与“实际完成需要的时间”相差较大, 每一项实际完成需要的时间都比计划共完成需要的时间要长,说明你对时 间的掌握还有自身能力的认识有一定的不足。在认真比对两列数据后,我发 现你在具体设计和具体编码部分超时严重,由此可以看出,你的编程能力 还有待提高,需要一定的时间去练习。 |
| 点评心得 | 通过点评同学的博文,我认识到自己与同学的代码风格有很大的相似之处, 这对后续的结对编程有一定的帮助; 通过这次点评,我也认识到自己的不足,排版不够美观大方,需要向同学学习; 通过这次点评,我也发现了同学的不足之处,编程能力不是很好, 我俩在编程方面都需要多加练习; 通过这次点评,我也认识到我俩在功能实现方面仍存在很大的不同, 在后续的结对编程中,仍需要一定的时间去磨合。 |
二、任务二:
1.需求分析:
通过对项目要求的分析,本次结对项目的需求为:
(1)实验2要求的功能;
(2)绘制单词频数可视化柱状图;
(3)统计该文本行数及字符数;
(4)各种统计功能均提供计时功能,显示程序统计所消耗时间(单位:ms);
(5)可处理任意用户导入的任意英文文本;
(6)人机交互界面要求GUI界面(WEB页面、APP页面都可);
(7)附加分功能:统计文本中除冠词、代词、介词之外的高频词。
2.软件设计:
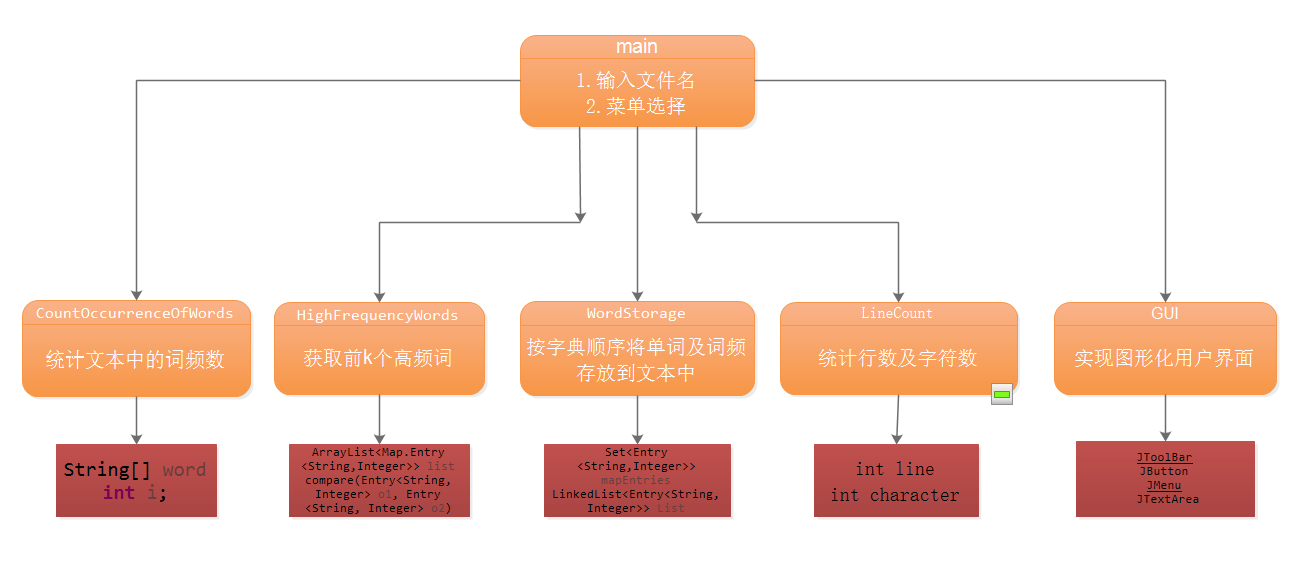
3.核心功能代码展示:
统计文本行数和字符数
try {//try代码块,当发生异常时会转到catch代码块中
//读取指定的文件
Scanner s = new Scanner(System.in);//创建scanner,控制台会一直等待输入,直到敲回车结束
System.out.println("请输入想要统计的文件名:");//输入提示信息
String a = s.nextLine();//定义字符串变量,并赋值为用户输入的信息
//创建类进行文件的读取,并指定编码格式为utf-8
InputStreamReader read = new InputStreamReader(new FileInputStream(a),"utf-8");
BufferedReader in = new BufferedReader(read);//可用于读取指定文件
String str=null;//定义一个字符串类型变量str
int line = 0;//定义一个整型变量,用于统计行数
int character = 0;//定义一个整型变量,用于统计字符数
while ((str = in.readLine())!= null) {//readLine()方法, 用于读取一行,只要读取内容不为空就一直执行
line++;//每循环一次就进行一次自增,用于统计文本行数
character += str.length();//用于统计总字符数
}
in.close(); //关闭流
System.out.println("该文本共有"+line+"行");
System.out.println("该文本共有"+character+"个字符");
}4.程序运行:
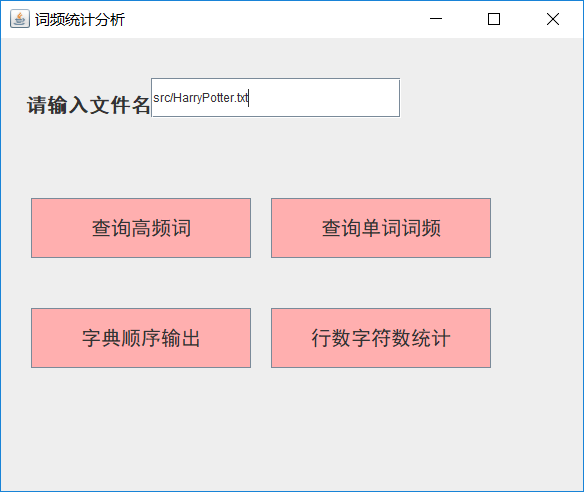
- (1)主界面:
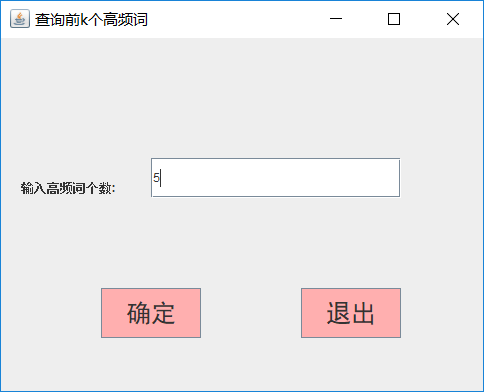
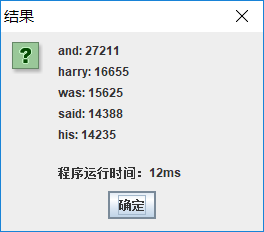
- (2)查询高频词:
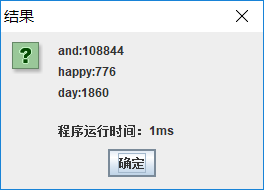
- (3)查询单词词频:
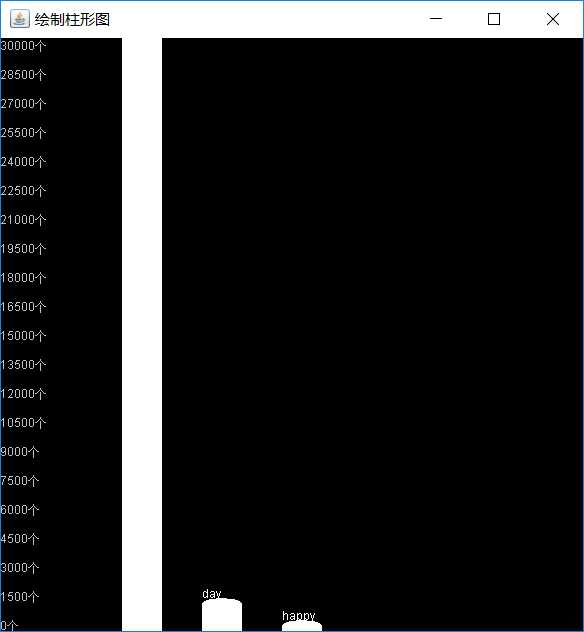
- (4)字典顺序输出:

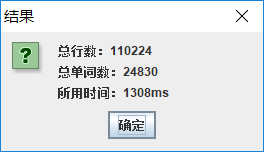
- (5)行数字符数统计:
5.结对过程:
我们在实验二的基础上,分析了还需实现的功能。
我们分开实现了文本行数和字符数和计时功能,我负责统计文本行数和字符数。
最后的GUI界面由我们两人共同编写。

6.PSP流程:
| PSP2.1 | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 8 | 12 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 8 | 10 |
| Development | 开发 | 82 | 250 |
| Analysis | 需求分析 (包括学习新技术) | 6 | 4 |
| Design Spec | 生成设计文档 | 10 | 30 |
| Design Review | 设计复审 (和同事审核设计文档) | 4 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 3 | 7 |
| Design | 具体设计 | 10 | 60 |
| Coding | 具体编码 | 50 | 200 |
| Code Review | 代码复审 | 20 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 30 | 50 |
| Test Report | 测试报告 | 10 | 15 |
| Size Measurement | 计算工作量 | 5 | 10 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 15 | 30 |
7.总结:
通过这次项目,我觉得在结对编程前期,可能两人合作并不能够带来1+1>2的效果,前期由于两人代码风格不同、解决问题的思路不同、不能有效沟通等原因,导致分歧较多,开发效率低下,但在渡过磨合期后,我觉得两人合作能够带来1+1>2的效果。在渡过了磨合期后,两人统一了代码风格,两个人在一起解决问题的速度也比一个人快,还可以在编程的同时进行代码复审,节约了时间也提高了效率。结对编程确实是一种比较好的开发方法,以后有机会我也会和队友再次尝试这种开发方法。

















 7017
7017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









