






 本文详细介绍了数组与链表的基本概念、定义方式、操作方法及其优缺点,并对比了两者的时间复杂度,帮助读者理解这两种常见数据结构的特点。
本文详细介绍了数组与链表的基本概念、定义方式、操作方法及其优缺点,并对比了两者的时间复杂度,帮助读者理解这两种常见数据结构的特点。
一、数组
数组的定义
格式一:
元素类型[] 数组名 = new 元素类型[元素的个数或数组长度]
示例:
int[] array1 = new int[2];
array1[0]=1;
array1[1]=2;
array1[2]=3;格式二:
元素类型[] 数组名 = new 元素类型[]{元素,元素,……};
示例:
int[] arr = new int[]{3,5,1,7};
int[] arr = {3,5,1,7};注意:给数组分配空间时,必须指定数组能够存储的元素个数来确定数组大小。创建数组之后不能修改数组的大小。可以使用length属性获取数组的大小
数组的优缺点
优点
- 随机访问性强(通过下标进行快速定位)
查找速度快
缺点
- 插入和删除效率低(插入和删除需要移动数据)
- 可能浪费内存(因为是连续的,所以每次申请数组之前必须规定数组的大小,如果大小不合理,则可能会浪费内存)
- 内存空间要求高,必须有足够的连续内存空间。
数组大小固定,不能动态拓展
二、链表
普及一下
线性表分为顺序存储(顺序表)和链式存储(单链表、双链表、循环链表、静态链表,前面三种指针实现,后面是借助数组实现)
1、单链表
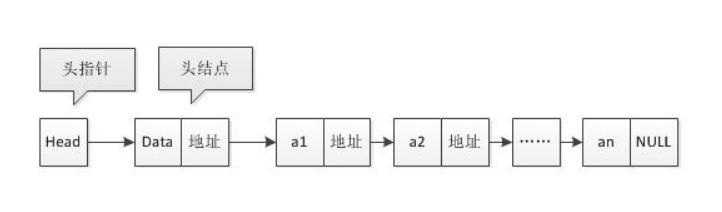
单链表只有一个指向下一节点的指针,也就是只能next
定义单链表
首先定义一个Node类
public class Node {
protected Node next; //指针域
public int data;//数据域
public Node( int data) {
this. data = data;
}
//显示此节点
public void display() {
System. out.print( data + " ");
}
}接下来定义一个单链表
public class LinkList {
public Node first; // 定义一个头结点
private int pos = 0;// 节点的位置
public LinkList() {
this.first = null;
}
// 插入一个头节点
public void addFirstNode(int data) {
Node node = new Node(data);
node.next = first;
first = node;
}
// 删除一个头结点,并返回头结点
public Node deleteFirstNode() {
Node tempNode = first;
first = tempNode.next;
return tempNode;
}
// 在任意位置插入节点 在index的后面插入
public void add(int index, int data) {
Node node = new Node(data);
Node current = first;
Node previous = first;
while (pos != index) {
previous = current;
current = current.next;
pos++;
}
node.next = current;
previous.next = node;
pos = 0;
}
// 删除任意位置的节点
public Node deleteByPos(int index) {
Node current = first;
Node previous = first;
while (pos != index) {
pos++;
previous = current;
current = current.next;
}
if (current == first) {
first = first.next;
} else {
pos = 0;
previous.next = current.next;
}
return current;
}
// 根据节点的data删除节点(仅仅删除第一个)
public Node deleteByData(int data) {
Node current = first;
Node previous = first; // 记住上一个节点
while (current.data != data) {
if (current.next == null) {
return null;
}
previous = current;
current = current.next;
}
if (current == first) {
first = first.next;
} else {
previous.next = current.next;
}
return current;
}
// 显示出所有的节点信息
public void displayAllNodes() {
Node current = first;
while (current != null) {
current.display();
current = current.next;
}
System.out.println();
}
// 根据位置查找节点信息
public Node findByPos(int index) {
Node current = first;
if (pos != index) {
current = current.next;
pos++;
}
return current;
}
// 根据数据查找节点信息
public Node findByData(int data) {
Node current = first;
while (current.data != data) {
if (current.next == null)
return null;
current = current.next;
}
return current;
}
}测试类
public class TestLinkList {
public static void main(String[] args) {
LinkList linkList = new LinkList();
linkList.addFirstNode(20);
linkList.addFirstNode(21);
linkList.addFirstNode(19);
//print19,21,20
linkList.add(1, 22); //print19,22,21,20
linkList.add(2, 23); //print19,22,23,21,20
linkList.add(3, 99); //print19,22,23,99,21,20
//调用此方法会print 19,22,23,99,21,20
linkList.displayAllNodes();
}
}2、双链表
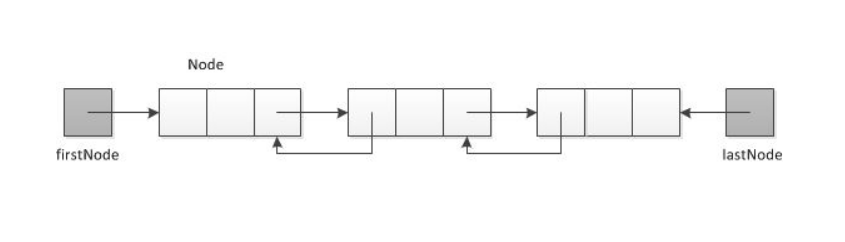
双链表除了有一个指向下一节点的指针外,还有一个指向前一结点的指针,可以通过prev快速找到前一结点
定义双链表
首先定义一个Node类
public class Node{
public Node data; //数据区
public Node next; //指针区
public Node (Node data,Node next){
this.data = data ;
this.next = next;
}
public Node(){
}
public void setData(Node data){
this.data = data;
}
public Node getData(){
return data;
}
public void setNext(Node next){
this.next=next;
}
public Node getNext(){
return next;
}
}定义一个双链表
public class LinkList{
public Node head; //头节点
public int count; //记录节点的长度
public LinkList(){ //构造函数用来初始化
head = null;
count = 0;
}
//节点的添加
public void addNode(Node data){
Node node = new Node(data,null);
Node temp = null;
If(head!= null){
temp = head;
while(temp.getNext()!=null){
Temp = temp.getNext();
}
temp.setNext(node);
}else{
head = node;
temp = node;
}
count++;
}
//节点的删除
public void delNode(Node data){
Node front = null; //定义一个空节点,用于接收和判断被删除节点的前面还有没有节点
while(head!= null){
If(head.equals(data)){
break;
}
front=head;
head = head.getNext();
}
If(head!=null){
If(front==null){
head = head.getNext();
}else{
front.setNext(head.getNext());
}
count--;
}else{
Count--;
}
}
//给定下标删除节点
public void delNode_count(int index){
if(index<0||index>count-1){
System.out.println("链表索引越界");
}
Node temp = head; //作用同上
//找到要删除节点的前一个节点
for(int i=0;i<index-1;i++){
temp=temp.getNext();
}
//找到之后 此节点的前节点和此节点的后节点进行连接
//让要删除节点的前一个节点,指向被删除节点的后一个节点,也就是指向要删除节点的后后一个节点
temp.setNext(temp.getNext().getNext()); //把要删除的节点隔过去进行连接,也就是实现了删除节点的操作
//删除之后链表的长度变短了1位
count--;
}
//以给出的index 查找节点
public Node findNode(int index){
if(index<0||index>count-1){
System.out.println("链表索引越界");
}
Node temp = head;
for(int i=0;i<index-1;i++){
temp=temp.getNext(); //找到之后获取index在链表中的位置,表示链表中第index个节点的值是temp.getData;
}
return temp; //根据需要可返回找到的数据对象,也可不返回,此处建议返回,这样可以把链表封装起来
}
//以对象查找节点
public Node findNode(NodeData data){
Node temp = head;
while(temp!=null){
if(temp.equals(data)){
return temp;
}
temp.setNext(temp.getNext());
}
return null;
}
//修改
public void updateNode(NodeData data){
Node temp = findNode(data);
if(temp!=null){
temp.setData(data);
}
}
//打印
public void print(){
Node temp=head;
while(temp!=null){
temp.print();
//temp.print(temp.getData().toString());
temp=temp.getNext();
}
}
}3、链表相对于数组的优缺点
时间复杂度对比
| 操作 | 数组 | 链表 |
|---|---|---|
| 读取 | O(1) | O(n) |
| 插入 | O(n) | O(1) |
| 删除 | O(n) | O(1) |
优点
- 插入删除速度快(因为有next指针指向其下一个节点,通过改变指针的指向可以方便的增加删除元素)
- 内存利用率高,不会浪费内存(可以使用内存中细小的不连续空间(大于node节点的大小),并且在需要空间的时候才创建空间)
大小没有固定,拓展很灵活。
缺点
不能随机查找,必须从第一个开始遍历,查找效率低
4、单链表与双链表的区别
单链表只有一个指向下一结点的指针,也就是只能next
双链表除了有一个指向下一结点的指针外,还有一个指向前一结点的指针,可以通过prev()快速找到前一结点,顾名思义,单链表只能单向读取
双链表的优点
- 删除单链表中的某个结点时,一定要得到待删除结点的前驱,得到该前驱有两种方法,第一种方法是在定位待删除结点的同时一路保存当前结点的前驱。第二种方法是在定位到待删除结点之后,重新从单链表表头开始来定位前驱。尽管通常会采用方法一。但其实这两种方法的效率是一样的,指针的总的移动操作都会有2*i次。而如果用双向链表,则不需要定位前驱结点。因此指针总的移动操作为i次。
- 查找时也一样,我们可以借用二分法的思路,从中间节点开始前后同时查找,这样双链表的效率可以提高一倍。
单链表的优点
- 从存储结构来看,每个双链表的节点要比单链表的节点多一个指针,而长度为n就需要 n*length(这个指针的length在32位系统中是4字节,在64位系统中是8个字节) 的空间,这在一些追求时间效率不高应用下并不适应,因为它占用空间大于单链表所占用的空间;这时设计者就会采用以时间换空间的做法,这时一种工程总体上的衡量。

















 10
10

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









