




 本文探讨了线性回归模型性能评估的三个方面:残差图、均方误差(MSE)和决定系数(R2)。残差图用于直观检查模型的线性性和异常值;MSE衡量模型误差的平均值;R2是MSE的标准化版本,反映模型解释数据变异性的能力。综合这三个指标,可以全面评估线性回归模型的性能。
本文探讨了线性回归模型性能评估的三个方面:残差图、均方误差(MSE)和决定系数(R2)。残差图用于直观检查模型的线性性和异常值;MSE衡量模型误差的平均值;R2是MSE的标准化版本,反映模型解释数据变异性的能力。综合这三个指标,可以全面评估线性回归模型的性能。
为了获得对模型性能的无偏估计,在训练过程中使用未知数据对测试进行评估是至关重要的。所以,需要将数据集划分为训练数据集和测试数据集,前者用于模型的训练,后者用户模型在未知数据上泛化性能的评估。
对于线性模型
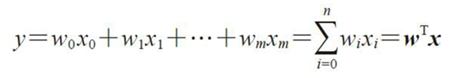
一、残差图
当m>1时,模型使用了多个解释变量,无法在二维坐标上绘制线性回归曲线。那么如何对回归模型的性能有一个直观的评估呢?可以通过绘制预测值的残差图,即真实值和预测值之间的差异或者垂直距离。
残差图作为常用的图形分析方法,可对回归模型进行评估,获取模型的异常值,同时还可以检查模型是否是线性的,以及误差是否随机分布。
通过将预测结果减去对应的目标变量的真实值,便可获得残差值。如下残差图像,其中X轴表示预测结果,Y轴表示残差。其中一条直线 Y=0,表示残差为0的位置。
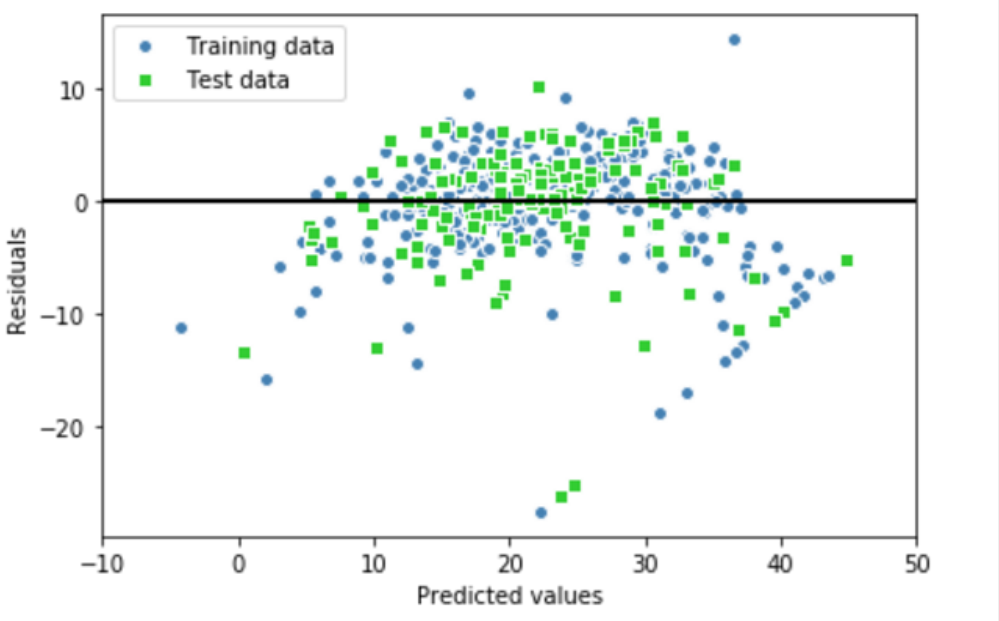
如果拟合结果准确,残差应该为0。但实际应用中,这种情况通常是不会发生的。但是,对于一个好的回归模型,期望误差是随机分布的,同时残差也随机分布于中心线附近。
如果我们从残差图中找出规律,就意味着模型遗漏了某些能够影响残差的解释信息,就如同看到的残差图那样,其中有这些许规律。此外,还可以通过残差图来发现异常值,这些异常值看上去距离中心线有较大的偏差。
二、均方误差(Mean Squared Error, MSE)
另外一种对模型性能进行定量估计的方法称为均方误差(Mean Squared Error, MSE), 它是线性回归模型拟合过程中,最小化误差平方和(SSE)代价函数的平均值。
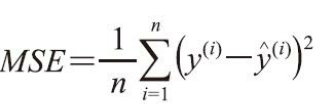
三、决定系数(R2)
但是MSE不甚全面,某些情况下决定系数(coefficient of determination)(R2)显得尤为有用,它可以看作是MSE的标准化版本,用于更好地解释模型的性能。R2值的定义如下:
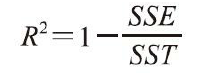
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8756
8756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









