import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import Normalize
import matplotlib.cm as cm
import random
import os
class AntColonyOptimizer:
"""蚁群优化算法实现,用于解决旅行商问题(TSP)或路径规划问题"""
def __init__(self, distance_matrix, num_ants=50, max_iterations=100,
alpha=1.0, beta=2.0, rho=0.5, q=100,
min_length=42000, max_length=43000,
start_node=None, route_type='circular'):
"""
初始化蚁群优化器
参数:
distance_matrix: 距离矩阵,n×n的numpy数组
num_ants: 蚂蚁数量
max_iterations: 最大迭代次数
alpha: 信息素重要程度参数
beta: 启发式因子重要程度参数
rho: 信息素蒸发系数
q: 信息素增加强度系数
min_length: 路径最小长度约束(米)
max_length: 路径最大长度约束(米)
start_node: 起点节点(默认为随机)
route_type: 路径类型,'circular'为环形路线,'linear'为线性路线
"""
self.distance_matrix = distance_matrix
self.num_cities = distance_matrix.shape[0]
self.num_ants = num_ants
self.max_iterations = max_iterations
self.alpha = alpha
self.beta = beta
self.rho = rho
self.q = q
self.min_length = min_length
self.max_length = max_length
self.start_node = start_node
self.route_type = route_type
# 初始化信息素矩阵
self.pheromone_matrix = np.ones((self.num_cities, self.num_cities))
np.fill_diagonal(self.pheromone_matrix, 0) # 对角线为0,避免自环
# 启发式信息矩阵(距离的倒数)
self.eta_matrix = 1.0 / (self.distance_matrix + 1e-10) # 避免除零
# 记录最佳路径和长度
self.best_route = None
self.best_length = float('inf')
self.best_route_history = []
self.average_length_history = []
def run(self):
"""运行蚁群优化算法"""
for iteration in range(self.max_iterations):
# 生成所有蚂蚁的路径
all_routes = self._generate_ant_routes()
# 计算所有路径的长度并检查约束条件
valid_routes = []
valid_lengths = []
for route in all_routes:
length = self._calculate_route_length(route)
# 检查路径长度约束
if self.min_length <= length <= self.max_length:
valid_routes.append(route)
valid_lengths.append(length)
# 如果没有有效路径,放宽约束
if not valid_routes:
valid_routes = all_routes
valid_lengths = [self._calculate_route_length(r) for r in all_routes]
# 更新最佳路径
if valid_lengths:
current_best_idx = np.argmin(valid_lengths)
current_best_length = valid_lengths[current_best_idx]
current_best_route = valid_routes[current_best_idx]
if current_best_length < self.best_length:
self.best_length = current_best_length
self.best_route = current_best_route
# 记录本次迭代的最佳路径长度和平均长度
self.best_route_history.append(self.best_length)
self.average_length_history.append(np.mean(valid_lengths))
# 更新信息素矩阵
self._update_pheromone_matrix(valid_routes, valid_lengths)
# 打印进度
if (iteration + 1) % 10 == 0:
print(f"迭代 {iteration+1}/{self.max_iterations}, 最佳路径长度: {self.best_length:.2f} 米")
return self.best_route, self.best_length
def _generate_ant_routes(self):
"""生成所有蚂蚁的路径"""
all_routes = []
for ant in range(self.num_ants):
# 选择起点
if self.start_node is not None:
current_node = self.start_node
else:
current_node = random.randint(0, self.num_cities - 1)
# 初始化路径
route = [current_node]
unvisited = set(range(self.num_cities)) - {current_node}
# 构建路径
while unvisited:
# 计算选择概率
probabilities = []
for city in unvisited:
pheromone = self.pheromone_matrix[current_node, city] ** self.alpha
heuristic = self.eta_matrix[current_node, city] ** self.beta
probabilities.append(pheromone * heuristic)
# 归一化概率
if sum(probabilities) == 0:
# 如果所有概率为0,随机选择
next_node = random.choice(list(unvisited))
else:
probabilities = [p / sum(probabilities) for p in probabilities]
# 按概率选择下一个城市
next_node = random.choices(list(unvisited), weights=probabilities)[0]
route.append(next_node)
unvisited.remove(next_node)
current_node = next_node
# 如果是环形路线,回到起点
if self.route_type == 'circular':
route.append(route[0])
all_routes.append(route)
return all_routes
def _calculate_route_length(self, route):
"""计算路径总长度"""
length = 0
for i in range(len(route) - 1):
length += self.distance_matrix[route[i], route[i+1]]
return length
def _update_pheromone_matrix(self, routes, lengths):
"""更新信息素矩阵"""
# 信息素挥发
self.pheromone_matrix *= (1 - self.rho)
# 添加新的信息素
for route, length in zip(routes, lengths):
for i in range(len(route) - 1):
city_i = route[i]
city_j = route[i+1]
self.pheromone_matrix[city_i, city_j] += self.q / length
def main():
"""主函数,演示如何使用蚁群算法进行马拉松路线规划"""
# 示例:生成随机节点坐标并运行算法
print("=== 马拉松路线规划蚁群算法演示 ===")
# 模拟西安市节点数据(实际应用中应从文件读取)
n = 50 # 节点数量
np.random.seed(42) # 设置随机种子以获得可重复结果
# 生成西安市范围内的随机节点坐标(近似经纬度)
lats = np.random.uniform(34.1, 34.5, n)
lons = np.random.uniform(108.7, 109.2, n)
# 创建节点DataFrame
nodes = pd.DataFrame({
'NodeID': range(n),
'Latitude': lats,
'Longitude': lons
})
# 计算距离矩阵(使用Haversine公式计算球面距离)
distance_matrix = np.zeros((n, n))
for i in range(n):
for j in range(n):
if i != j:
# Haversine公式计算球面距离(单位:米)
lat1, lon1 = lats[i], lons[i]
lat2, lon2 = lats[j], lons[j]
R = 6371000 # 地球半径(米)
dlat = np.radians(lat2 - lat1)
dlon = np.radians(lon2 - lon1)
a = np.sin(dlat/2) * np.sin(dlat/2) + np.cos(np.radians(lat1)) * np.cos(np.radians(lat2)) * np.sin(dlon/2) * np.sin(dlon/2)
c = 2 * np.arctan2(np.sqrt(a), np.sqrt(1-a))
distance_matrix[i, j] = R * c
# 配置蚁群算法参数
aco = AntColonyOptimizer(
distance_matrix=distance_matrix,
num_ants=30,
max_iterations=100,
alpha=1.0,
beta=2.0,
rho=0.5,
q=100,
min_length=42000, # 马拉松标准长度(米)
max_length=43000, # 允许的最大偏差
start_node=0, # 指定起点
route_type='circular' # 环形路线
)
# 运行算法
print("开始运行蚁群算法...")
best_route, best_length = aco.run()
print(f"\n优化完成!")
print(f"最佳路线长度: {best_length:.2f} 米")
print(f"最佳路线节点序列: {best_route}")
# 可视化结果
plt.figure(figsize=(12, 10))
# 绘制所有节点
plt.scatter(nodes['Longitude'], nodes['Latitude'], c='gray', s=30, alpha=0.7)
# 绘制最佳路径
route_lons = [nodes.iloc[i]['Longitude'] for i in best_route]
route_lats = [nodes.iloc[i]['Latitude'] for i in best_route]
plt.plot(route_lons, route_lats, 'r-', linewidth=2, alpha=0.8)
# 标记起点和终点
plt.scatter(route_lons[0], route_lats[0], c='blue', s=150, marker='*', label='起点/终点')
plt.title('优化后的马拉松路线规划')
plt.xlabel('经度')
plt.ylabel('纬度')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
# 显示迭代过程
plt.figure(figsize=(10, 6))
plt.plot(range(1, aco.max_iterations + 1), aco.best_route_history, 'b-', label='最佳路径长度')
plt.plot(range(1, aco.max_iterations + 1), aco.average_length_history, 'g-', label='平均路径长度')
plt.xlabel('迭代次数')
plt.ylabel('路径长度 (米)')
plt.title('蚁群算法迭代过程')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
main()
请你修改一下以上代码,希望你使用蚁群算法解决第二题---以西安市为例,基于西安市基础数据中的景点、住宿设施坐标集。
(1) 建立评价函数(考虑容量权重与邻近路网密度),并绘制图形划分服
务范围。要求建立目标优化模型筛选出最优的起点-终点组合(路线不
唯一)赛跑线路,该线路需满足: ①两地路线距离≥42km;
②起点 3000 米内住宿容量≥3000 人;
③起、终点毗邻轨道交通站点。
(2) 将景点抽象为必经节点集,餐饮设施视为增益节点(每经过 1 个增益
+0.2)。要求设计符合国际马拉松(全马、半马、健康跑)公里数要
求的闭合回路,赛跑线路需满足: ①坡度≤5%;
②每 5km 设置补给站(需邻近餐饮设施)的条件下,提供最大增益
值的赛跑线路。
改写之前的代码,最终直接输出代码方便我粘贴直接使用。新增要求XiAn_Intersection_Coordinates_and_IDs_Data的权重为0.236,XiAn_Accommodation_Data的权重为0.417,XiAn_Intersection_Coordinates_and_IDs_Data的权重0.247.并将代码中的随机数据生成部分替换为从 CSV 或其他格式文件读取数据的代码。以下是我收集的真实数据路径也是你要用的数据。
C:\Users\Administrator\Desktop\ant\XiAn_Accommodation_Data.csv
C:\Users\Administrator\Desktop\ant\XiAn_Intersection_Coordinates_and_IDs_Data.csv
C:\Users\Administrator\Desktop\ant\XiAn_Meteorological_Data.csv
C:\Users\Administrator\Desktop\ant\XiAn_Restaurant_Data.csv
C:\Users\Administrator\Desktop\ant\XiAn_Road_Auxiliary_Facilities_Data.csv
C:\Users\Administrator\Desktop\ant\XiAn_Scenic_Spots_Data.csv





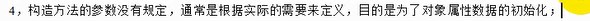



 本文主要介绍了...(由于未提供具体博客内容,无法生成精确摘要)。
本文主要介绍了...(由于未提供具体博客内容,无法生成精确摘要)。
 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























