






 本文深入解析了Android应用开发中的Activity生命周期,包括三种状态、七个关键方法、四种启动模式及实例启动方法,帮助开发者更好地理解并运用Activity生命周期。
本文深入解析了Android应用开发中的Activity生命周期,包括三种状态、七个关键方法、四种启动模式及实例启动方法,帮助开发者更好地理解并运用Activity生命周期。
Activity大家从开始开发Android就开始用了 也就是Android的窗口了 类似与一个容器你可以在上面放文本,按钮等等的UI组件.
所以其余的不用多啰嗦 直接说下他的理论部分:
1.Activity的生命周期(引用官网 图片)
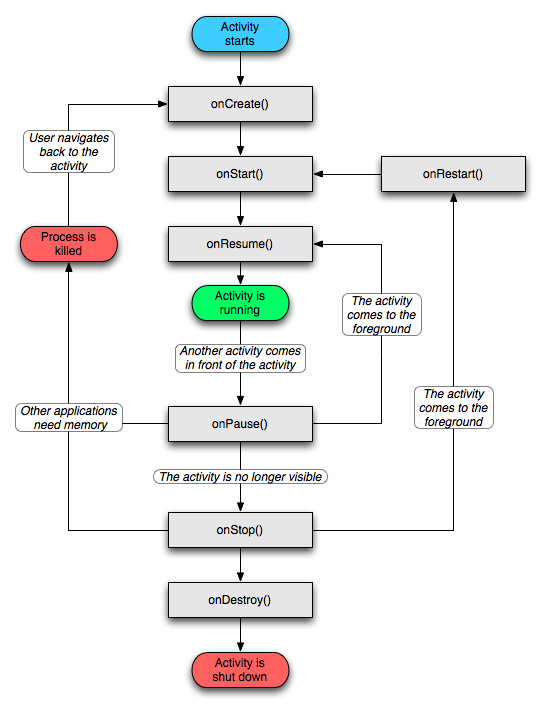
1.2
1.2.1Activity的三个状态:
a>当它在屏幕前台时(位于当前任务堆栈的顶部),它是激活或运行状态。它就是响应用户操作的Activity。
b>当它上面有另外一个Activity,使它失去了焦点但仍然对用户可见时(如右图),它处于暂停状态。在它之上的Activity没有完全覆盖屏幕,或者是透明的,被暂停的Activity仍然对用户可见,并且是存活状态(它保留着所有的状态和成员信息并保持和窗口管理器的连接)。如果系统处于内存不足时会杀死这个Activity。
c>当它完全被另一个Activity覆盖时则处于停止状态。它仍然保留所有的状态和成员信息。然而对用户是不可见的,所以它的窗口将被隐藏,如果其它地方需要内存,则系统经常会杀死这个Activity。
1.2.2当Activity从一种状态转变到另一种状态时,会调用以下保护方法来通知这种变化:
void onCreate(Bundle savedInstanceState)
void onStart()
void onRestart()
void onResume()
void onPause()
void onStop()
void onDestroy()
这七个方法定义了Activity的完整生命周期。实现这些方法可以帮助我们监视其中的三个嵌套生命周期循环:
-Activity的完整生命周期自第一次调用onCreate()开始,直至调用onDestroy()为止。Activity在onCreate()中设置所有“全局”状态以完成初始化,而在onDestroy()中 释放所有系统资源。例如,如果Activity有一个线程在后台运行从网络下载数据,它会在onCreate()创建线程,而在 onDestroy()销毁线程。
-Activity的可视生命周期自onStart()调用开始直到相应的onStop()调用结束。在此期间,用户可以在屏幕上看到Activity,尽管它也许并不是位于前台或者也不与用户进行交互。在这两个方法之间,我们可以保留用来向用户显示这个Activity所需的资源。例如,当用户不再看见我们显示的内容时,我们可以在onStart()中注册一个BroadcastReceiver来监控会影响UI的变化,而在onStop()中来注消。onStart() 和 onStop() 方法可以随着应用程序是否为用户可见而被多次调用。
-Activity的前台生命周期自onResume()调用起,至相应的onPause()调用为止。在此期间,Activity位于前台最上面并与用户进行交互。Activity会经常在暂停和恢复之间进行状态转换——例如当设备转入休眠状态或者有新的Activity启动时,将调用onPause() 方法。当Activity获得结果或者接收到新的Intent时会调用onResume() 方法。关于前台生命周期循环的例子请见PPT下方备注栏。
1.2.3Activity的四种启动模式:(standard/singleTop/singleTask/singleInstance)

1.2.3.1standard模式
默认模式,可以不用写配置。在这个模式下,都会默认创建一个新Activity的实例并放入到任务栈中。因此,在这种模式下,可以有多个相同的实例,也允许多个相同Activity叠加。
例如:点击Activity A中为事件到Activity B(创建新的Activity事例)再点击 B 中事件到Activity C(创建新的Activity事例) 点击C中的事件到D(创建新的Activity事例) .......他们会按照A->B->C->D...依次的压入栈中,当回退的时再依次按照栈的顺序退出.
1.2.3.2singleTop模式
如果在任务栈顶正好存在该Activity的实例,就会重用该实例(会调用实例的onNewIntent()),否则就会创建新的实例并放入栈顶(即使任务栈中已经存在该Activity的实例,只要不在栈顶,就会创建实例)
1.2.3.3singleTask模式
如果在战中已经有该Activity的实例,就重用该实例(会调用实例的onNewIntent()),重用时,会让该实例回到栈顶,依次在它上面的实例将会被移除任务栈.如果栈中不存在该实例,将会创建新的实例放入栈中.
1.2.3.4singleInstance模式
在一个新栈中创建该Activity的实例,并让多个应用共享该栈中的该Activity实例,一旦该模式的activity实例已经存在在某个战中,任何应用再激活该Activity时都会重用该栈中的实例(会调用实例的onNewIntent()),其效果相当于多个应用共享一个Activity应用,无论谁激活该Activity都会进入到同一个应用中.\
1.2.4在一个Activity中启动第二个Activity方法:1.startActivity(intent);2.startActivityForResult(intent, 100);
1.2.5怎么携带数据请参考 Intent的详解

















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









