



下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
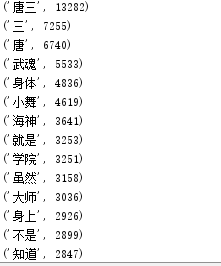
import jieba fo = open('douluo.txt','r',encoding='utf-8').read() wordsls = jieba.lcut(fo) wcdict = {} # for word in wordsls: # if len(word)==1: # continue # else: # wcdict[word]=wcdict.get(word,0)+1 for i in set(wordsls): wcdict[i]=wordsls.count(i) delete={'你','我','他','自己','都','已经','着','不','她','没有','和','他们','中','我们','下','什么','一个', '道','的','们','所','在','来','有','过','从','而','才','要','因','为','地','将','上','共','自','是', '令','但','被','就','也','说','语','呀','啊','呵','个','人','里','罢','内','该','与','会','对','去', '出','动','却','超','已','只','放','这','比','还','则','见','到','最','话','加','更','并','把', '儿','大','小','那',' ','了','-','\n',',','。','?','!','“','”',':',';','、','.','‘','’'} for i in delete: if i in wcdict: del wcdict[i] sort_word = sorted(wcdict.items(), key = lambda d:d[1], reverse = True) # 排序 for i in range(20): # 输出 print(sort_word[i]) # fo = open("douluo1.txt", "r",encoding='utf-8') # print ("文件名为: ", fo.name) # for index in range(5): # line = next(fo) # print ("第 %d 行 - %s" % (index, line)) # # # 关闭文件 # fo.close()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









