






 本文介绍了一个基于C++的词频统计项目,重点介绍了如何利用STL容器和排序函数进行高效的单词计数与排序,同时分享了性能优化的过程。
本文介绍了一个基于C++的词频统计项目,重点介绍了如何利用STL容器和排序函数进行高效的单词计数与排序,同时分享了性能优化的过程。
1. github项目地址
2. PSP表格
| PSP2.1 | ersonal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| Estimate | 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 420 | 910 |
| Analysis | 需求分析 (包括学习新技术) | 210 | 230 |
| Design Spec | 生成设计文档 | 10 | 15 |
| Design Review | 设计复审 | 10 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| Design | 具体设计 | 20 | 15 |
| Coding | 具体编码 | 120 | 110 |
| Code Review | 代码复审 | 15 | 280 |
| Test | 测试(自我测试,修改代码,提交修改) | 25 | 240 |
| Reporting | 报告 | 40 | 65 |
| Test Repor | 测试报告 | 15 | 30 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 465 | 980 |
3. 解题思路
刚拿到题目的时候便看到了没用过的文件IO操作,一开始感觉难点应该在字典序排序和统计单词,统计单词属于字符串处理,每次做字符串处理的时候总是会有很多方面想不到需要一直改进才可以ac;而字典序排序在之前大一大二时做过类似的算法题,具体实现不记得就记得字典序特别复杂。语言方面自己之前看过一些Java教程,但是看到题目要求中要给出由vs2017的性能分析工具,感觉java可能自己在找工具和学习使用工具时会比较麻烦便选择了C++ 实现。
思考及查找资料过程:
- 项目中的IO操作只是基础的文件处理,回宿舍靠着谭浩强C++程序设计就解决了。字符串处理虽然麻烦但只要认真加多花点时间就可以解决;字典序我起初也是这样认为,但多思考了一会感觉在字典序排序的同时还需要考虑单词出现频率,在脑海中过了一下数组、堆栈之类的数据结构感觉处理都很复杂,便开始上网寻找有没有前人造的轮子。
- 上网搜索后我不得不感慨开源的伟大(还有造轮子的前人)。我在数据结构课设 词频统计这篇博客中看到了相似的题目,作者也贴出了源代码,这次项目我从中学到了特别多。这篇文章中作者使用了map容器来存放单词的字符串及其出现次数,再将由单词及其词频的pair对组成的vector使用sort函数进行排序来达到题目要求。在这之前我在某些代码中也看到过vector但是都没去深入的学习容器的相关知识,map和pair则是完全没有了解,同时也从这篇博客知道了C++内部其实已经封装好了字典序的排序,作者处理字符串(即获取字符串中的单词)的方式我也觉得很巧妙,我在本次项目中便使用了这种方法来获取单词,具体会在下文列出。
- 知道了容器在处理数据中的方便和C++ 在STL中已经封装好了字典序排序,接下去便只需要去找资料和学习了。在
C++ STL中容器的使用全面总结和map 学习(上)——C++中 map 的使用以及map 学习(下)——C++ 中的 hash_map unordered_map这三篇博客中学习了C++容器的使用,同时发现在这次项目中按照我使用的方法在排序前时对单词保存的顺序没有要求,而数据结构课设 词频统计使用了map来保存排序前的单词,我认为使用查找速度更快unordered_map更合适。在学习完这些之后便足以实现项目要求的基本功能了。
4. 设计实现过程
代码思路
代码文件
031602511
|- src
|- WordCount.sln
|- WordCount
|- FileRead.h
|- FileRead.cpp
|- Main.cpp
|- WordCount.vcxproj- 代码初始有一个
FileRead类,定义于FileRead.h中;在后续优化排序算法时新增了一个cmp类其中有一个用于根据题意对单词排序,仅有一个重载操作符()的函数,过于简单故不截图说明 FileRead代码中函数都在类中定义,分为公有成员函数和私有成员函数公有成员函数(面向用户,即用户接口)

私有成员函数(获取数据以保证公有成员函数的实现)

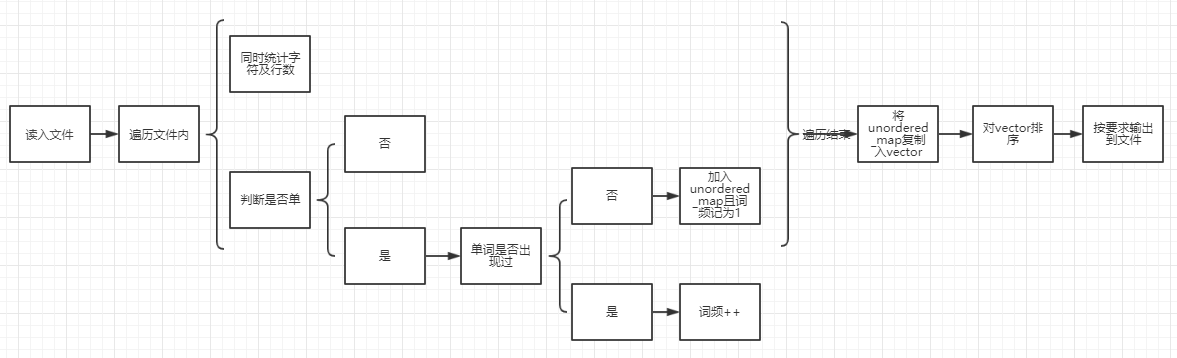
- 关键函数单词计数并存入容器
wordCount()(以及单词排序wordPair()),wordPair()代码较为简单无需流程图且代码会在下文性能改进中贴出,故此处仅列出wordCount()的关键代码即单词判断部分函数关键代码
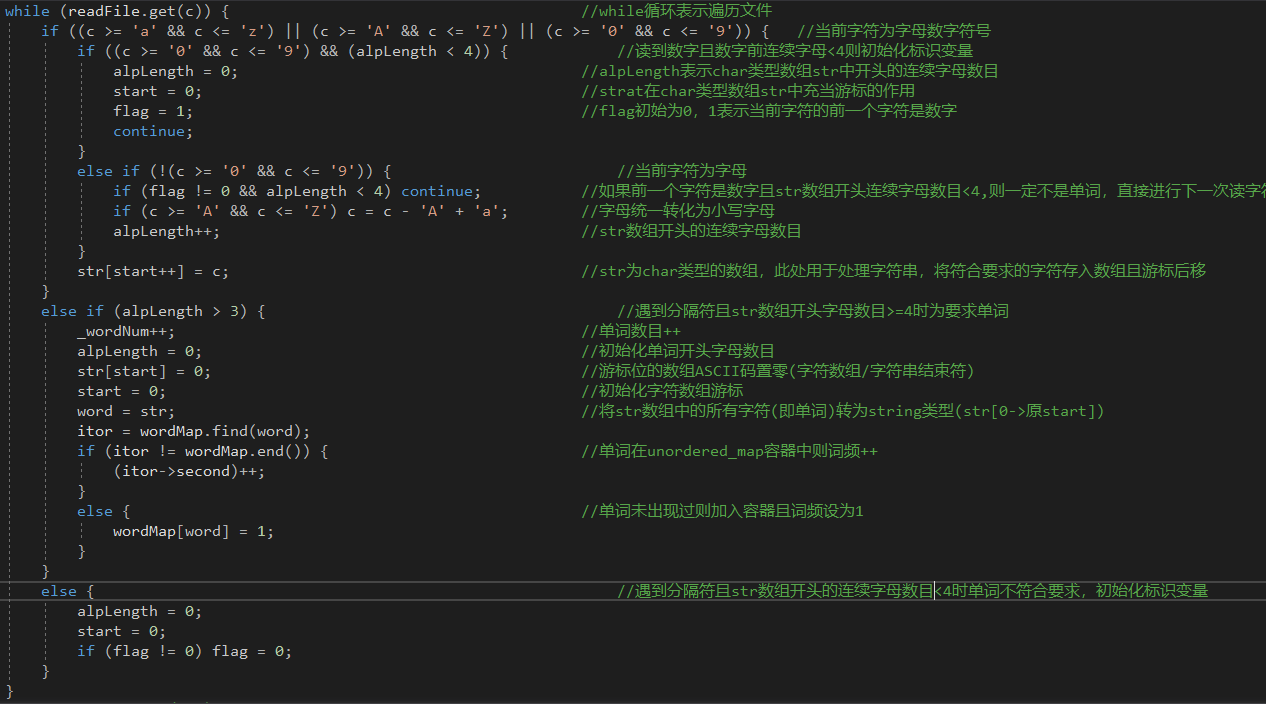
函数流程图
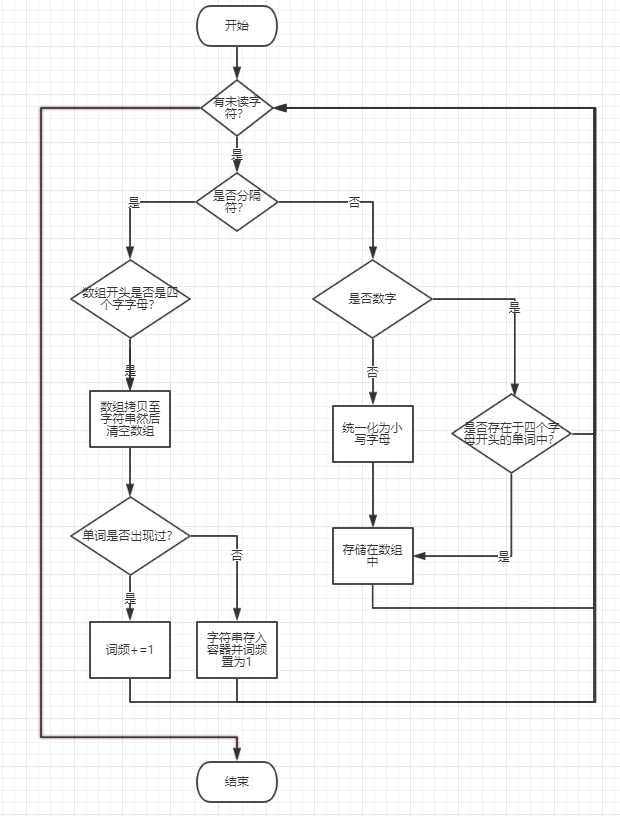
- 算法关键
- 单词判断;单词排序
- 独到之处
- 在性能改进阶段进行后,单词由全排序优化为仅求最大词频的前十位单词;使用了STL中的容器及内置排序函数,方便使用且拥有良好的可拓展性
5. 计算模块接口部分的性能改进
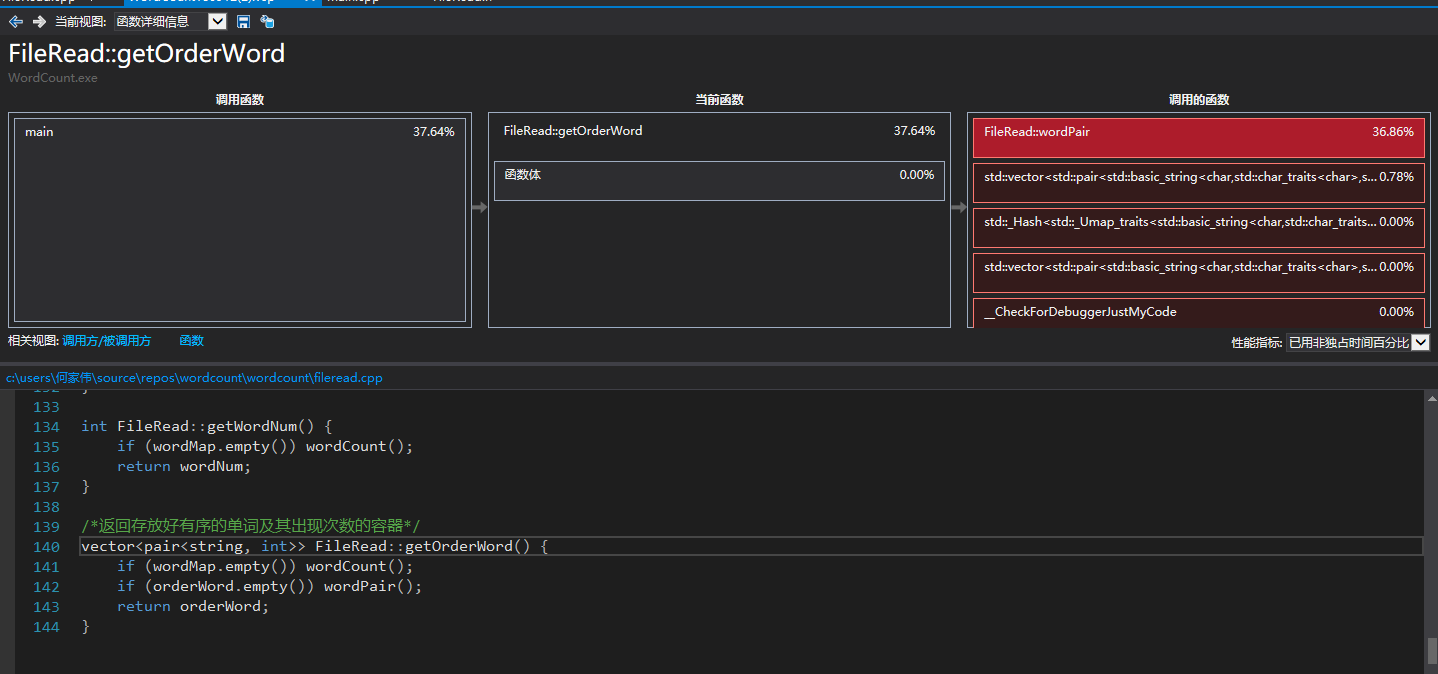
初始性能分析图,可以看出主要都是获取排序后单词容器的用户接口
getOrderWord()中wordPair()函数中对vector排序的sort函数占用独立时间较多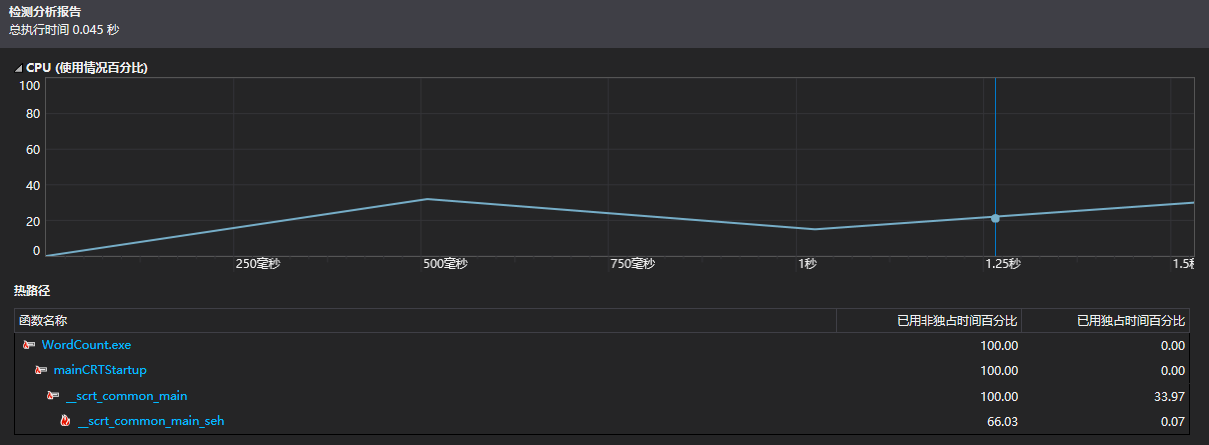
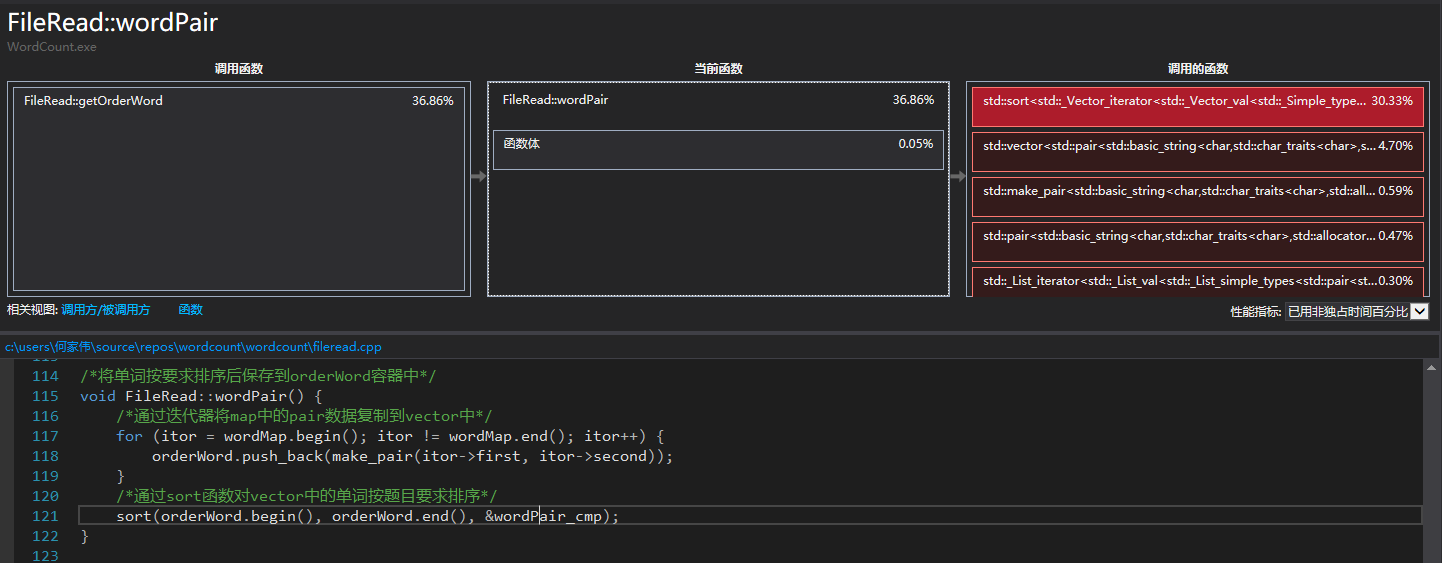
- 改进思路
- 主要是sort函数耗时多,所以有两种改进思路:一是改进进行排序的元素的数据结构,但考虑到可拓展性(和我决定自己打太麻烦)以及vector可以方便的进行查询单词及对应词频,我觉得元素数据结构无需修改;二是改进排序的算法,一开始是对所有单词采用STL中的快速排序,复杂度是n * log(n),在思考及查阅资料后,将sort函数改为同样STL中的partial_sort,对仅排序出词频在前十的单词,partial_sort采用堆排序,如果对n个元素进行前m元素的排序,时间复杂度为n * log(m)。修改后代码如下
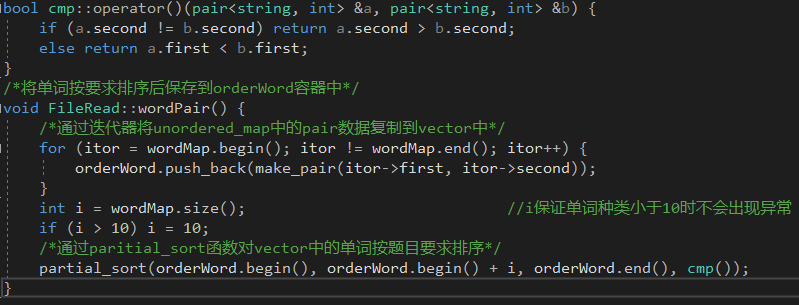
- 主要是sort函数耗时多,所以有两种改进思路:一是改进进行排序的元素的数据结构,但考虑到可拓展性(和我决定自己打太麻烦)以及vector可以方便的进行查询单词及对应词频,我觉得元素数据结构无需修改;二是改进排序的算法,一开始是对所有单词采用STL中的快速排序,复杂度是n * log(n),在思考及查阅资料后,将sort函数改为同样STL中的partial_sort,对仅排序出词频在前十的单词,partial_sort采用堆排序,如果对n个元素进行前m元素的排序,时间复杂度为n * log(m)。修改后代码如下
改进后性能分析图,可以看出占用独立时间最多的函数已经由
getOrderWord()变成了获取单词数目的getWordNum(),即新的排序算法比原先更优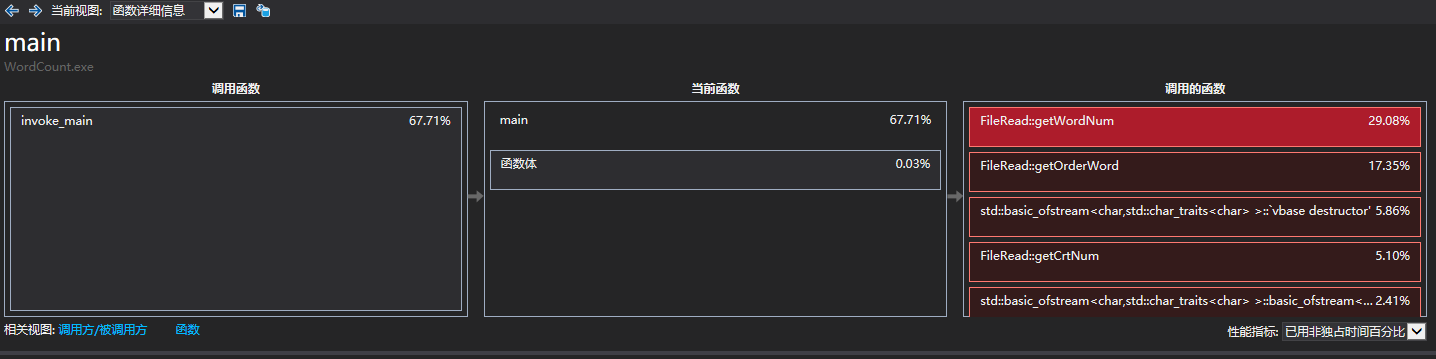
6. 计算模块部分单元测试展示
- 单元测试函数
reading_flie.getCrtNum():用户接口,返回文件字符数reading_flie.getWordNum():用户接口,返回文件单词总数reading_flie.getLineNum():用户接口,返回文件行数
- 单元测试数据构造思路
- 共十份数据,包括一些例如文件中不存在非空白字符或是所读取文件不存在的特殊情况外都是一些尽可能复杂、随机的数据
部分单元测试代码(测试是否能正确读取数据不存在非空白字符文件的数据)
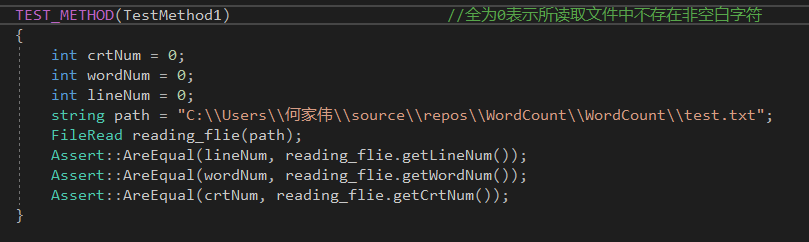
单元测试覆盖率截图(人为传入文本文件路径前提下),未覆盖代码基本都是用于异常处理或是本次测试未出现的特殊情况(例如关于文本最后一行是否是空字符行的判断)

7. 计算模块部分异常处理说明
- 本次项目我设计了三个异常:
- 需要读取的文件打开失败(文件不存在)
异常处理代码

对应单元测试

- 需要写入的文件写入失败
- 异常处理代码
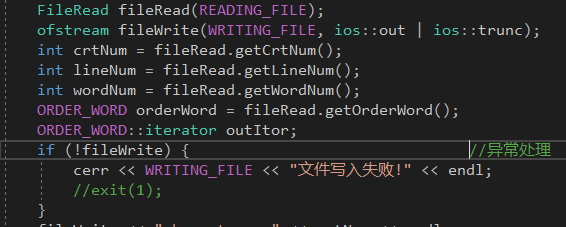
- 异常处理代码
- 传入命令行参数个数错误
- 异常处理代码
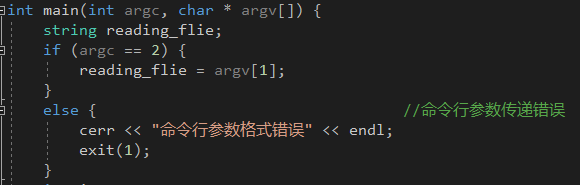
- 异常处理代码
- 虽然我设置了第二个异常,但我没能想出第二种异常的发生情况。这次题目中说的是
按照字典序输出到文件result.txt,并没有说明是否要自动生成result.txt文件,在项目中我设置为若result.txt不存在则自动在项目目录下生成并把数据写入其中(但是又怕有什么自己不知道的错误会导致写入失败),便设置了第二个异常。第三个异常则是因为我认为无法在单元测试中体现(单元测试无法使用命令行传参,会被认为是文件不存在的异常)。
- 需要读取的文件打开失败(文件不存在)
8. 心路历程与收获
- 这次项目实际用时和一开始预计用时有很大出入,起先我觉得主要应该是在写代码会花费很多时间,代码写好后无论博客或是说其它的什么要求应该改一改就好了。结果整个项目下来在代码编写好之后的代码复审和不断的改进整个代码结构和性能上下了特别多功夫,这篇博客也花费了很多的时间。虽然代码测试修改方面用时很多,但最终一个个封装好的接口和统一的编码风格一看就给人一种很舒服的感觉;编码过程中也学到了之前未接触过的容器类型,体会到了前人造的轮子是多么的强大,也跟着项目要求学习了git的使用和代码覆盖率、单元测试等实用工具。其实刚开始使用单元测试的时候我内心是有一些抗拒的,那时候感觉自己写代码的时候便会一直调试、测试数据,但随着后面不断地对代码进行修改才发现单元测试可以免去我们重复输入测试数据和检验的步骤,节省大量的测试时间。同样相见恨晚的便是git的代码管理功能,一开始因为感觉命令行之类的很麻烦(网络上各种教程看得头疼)就一直没有去学习,还是在最后两三天的时候请教了同学才弄清细致步骤,熟练之后才知道git的好。总的来说这次项目我对自己不太满意:在一开始学习容器和其它新知识的时候花费的时间过多,项目耗时被自己拖得太长、做项目的时间也没有安排好总是有零零散散东西第二天就有些记忆模糊又要重新回忆或者是学习(写博客时也是,有些之前想好的却因为断断续续的写结果写起来很不顺畅)。希望自己能引以为戒,在之后注重提高自己的效率、尽量不要把要做的事分成太多次来做。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









