






场景
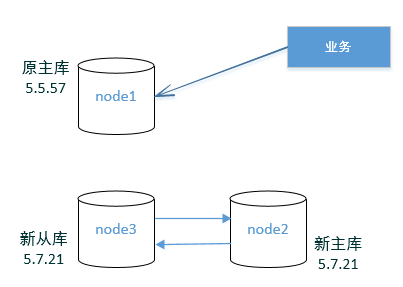
node1 和 node2 为两台不同业务的MySQL服务器。
业务方有个需求,需要将node1上的 employees库的departments 、dept_manager 这2张表同步到 node2 的 hellodb 库下面。
这里涉及到3个方面问题,
- 版本升级,5.5 -> 5.7
- 复制过滤,只复制 departments 、dept_manager 2张表
- 重写库名,主库名为 employees ,备库名为 hellodb
接下来,我们一步步解决上述的 3 个问题。
架构图1:
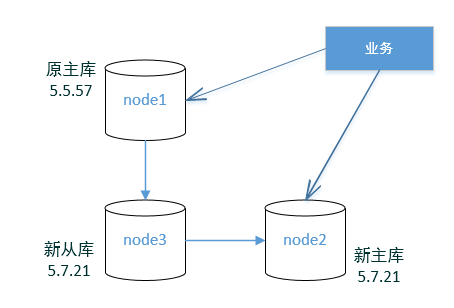
架构图2:
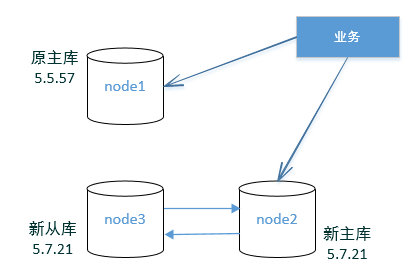
架构图3:
一、版本升级
原主库版本是 5.5.57,新库版本是 5.7.21(开启了gtid,master_auto_position=1)。
首先要把新库的复制改为传统复制:
# node2 && node3
stop slave; CHANGE MASTER TO master_auto_position=0; start slave;
然后关掉 GTID:
# node2 && node3
# node2: set global gtid_mode=ON_PERMISSIVE; # node3: set global gtid_mode=ON_PERMISSIVE; # node2: set global gtid_mode=OFF_PERMISSIVE; # node3: set global gtid_mode=OFF_PERMISSIVE; # node2: set global gtid_mode=OFF; # node3: set global gtid_mode=OFF; # node2: set global enforce_gtid_consistency=OFF; # node3: set global enforce_gtid_consistency=OFF;
# 注意 GTID 的在线开启和关闭,主从需要依次逐步开启
这样,5.5 到 5.7 的复制就不会有GTID的硬性问题了(如果你碰到其他不兼容,比如datetime默认值问题,谷歌解决即可)
然后把 node1 的employees库的departments 、dept_manager 这2张表同步到 node3 的 hellodb 库下面。
# node3
stop slave; change master to ...
二、复制过滤及重写库名
接下来设置复制过滤,我采用了笨重的重启方法(5.7 已经支持在线设置复制过滤了),这也是为什么业务迁到 node2,我却用node3 作为 node1的从库,因为需要重启。
修改node3的配置文件:
replicate-rewrite-db = employees -> hellodb replicate-wild-do-table=hellodb.departments replicate-wild-do-table=hellodb.dept_manager 注意,如果有 replicate-rewrite-db , replicate-wild-do-table 后面的库名要写 rewrite 之后的库名,而不是原来的库名。
然后重启 node3,现在,node1 employees 库下面的 departments 、dept_manager 表,就会实时同步到 node3和node2 。
node1 -> node3 -> node2
show slave status\G
Replicate_Wild_Do_Table: hellodb.departments,hellodb.dept_manager
Replicate_Rewrite_DB: (employees,hellodb)
附:在线修改复制过滤
Syntax: CHANGE REPLICATION FILTER filter[, filter][, ...] filter: REPLICATE_DO_DB = (db_list) | REPLICATE_IGNORE_DB = (db_list) | REPLICATE_DO_TABLE = (tbl_list) | REPLICATE_IGNORE_TABLE = (tbl_list) | REPLICATE_WILD_DO_TABLE = (wild_tbl_list) | REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) | REPLICATE_REWRITE_DB = (db_pair_list) db_list: db_name[, db_name][, ...] tbl_list: db_name.table_name[, db_table_name][, ...] wild_tbl_list: 'db_pattern.table_pattern'[, 'db_pattern.table_pattern'][, ...] db_pair_list: (db_pair)[, (db_pair)][, ...] db_pair: from_db, to_db
# 设置只同步db1,db2这2个库:(要先停止SQL线程)
使用命令很简单:CHANGE REPLICATION FILTER REPLICATE_DO_DB = (db1, db2);
# 要是又要全部的库都要同步该如何操作呢,也很简单。
STOP SLAVE SQL_THREAD;
CHANGE REPLICATION FILTER REPLICATE_DO_DB = ();
start SLAVE SQL_THREAD;
# 同样可以可以设置只同步某个库下面的某张表,或者不同步某个库下面的某张表。看命令。
mysql> CHANGE REPLICATION FILTER
-> REPLICATE_WILD_DO_TABLE = ('db1.t1%'),
-> REPLICATE_WILD_IGNORE_TABLE = ('db1.t2%');
# 设置同时同步1个库下面的某些表可以这样写:
mysql> CHANGE REPLICATION FILTER
-> REPLICATE_WILD_DO_TABLE = ('db2.t1%','db2.t2%');
# 设置重写DB:(注意需要加2个括号,否则语法报错,2个括号是因为可以同时设置多对重写规则)
CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB = ((db_activity,db_webadmin),(db_a,db_b));


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









