



 本文介绍了一种使用Fiddler抓包和Python爬虫技术来查询7天酒店积分免费房的方法。通过抓取酒店的基本信息及房间状态,利用requests和SQLite实现酒店列表和免费房状态的数据获取。
本文介绍了一种使用Fiddler抓包和Python爬虫技术来查询7天酒店积分免费房的方法。通过抓取酒店的基本信息及房间状态,利用requests和SQLite实现酒店列表和免费房状态的数据获取。
抓包软件:Fiddler
Python模块:requests、SQLite
一、准备工作
安装Fiddler、设置教程参考:
http://jingyan.baidu.com/article/03b2f78c7b6bb05ea237aed2.html
http://www.cnblogs.com/wakey/p/4244301.html
为了方便 建议设置filters中Host为 trip.plateno.com
点击订酒店就会发现如下的包被抓取:
其中必要重要的一个包是/hotel/query/ota/basic的这个包。
其发送的JSON为:
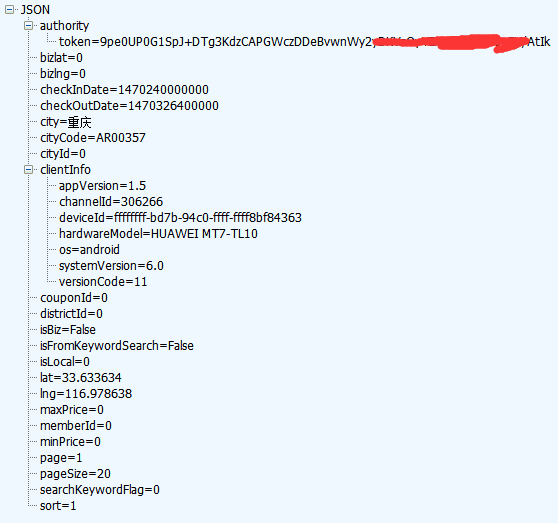
其中需要关注的几个值分别是:
- token:这个值需要自己抓包来获取,具体生成机制不明,但是很久都不会变。
- checkInDate和checkOutDate分别是入住和离店时间的时间戳,在爬虫中可以用time.time()来生成。
- city就是utf-8编码的城市名,cityCode也需要抓包获得。
接收到的JSON为:

其中data存储了每个酒店的一些基本信息,点开可以获得,此处需要关注的值是:
- hotelSum指出查询的城市的酒店数量
- data中获取chainCode和innName分别就是酒店的编号和酒店名。
然后,随便点开一家7天酒店,关注/hotel/roomStatus这个包
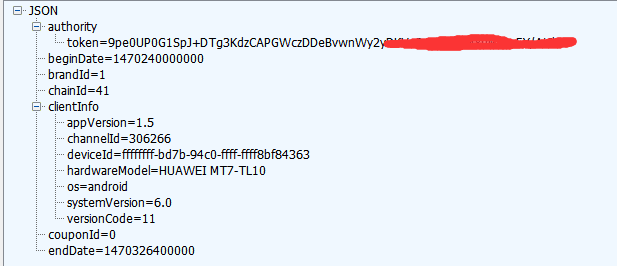
需要关注的值是:
- token同上
- beginDate和endDate同样是时间戳
- chainID 和上文中的chainCode相同,都是酒店的编号
至于积分免费房的信息的具体位置,就在返回的JSON中,通过如下的解析判断方式可以获得免费房信息,其中hotel就是返回的JSON字符串经过loads后的字典。
def can_book_free_room(hotel):
for i in hotel['result']['data']:
# 自主大床房
if i['roomTypeId'] == '220':
for j in i['roomStatusList'][0]['roomRates']:
# 积分免费房
if j['actLabel'] == u'2000积分免费房':
if j['canBooking']:
return True
else:
return False此时也就完成了所有的准备工作,获取了所有需要的url、request的body及其参数。
二、爬虫编写
因为代码较长,故不在此放出,请移步github:
https://github.com/HortonHu/7days_free_room
下载后需要在项目中新建一个token.ini配置文件,内容是:
[room]
room_token=***上述步骤中第一个token***
[hotel]
hotel_token=***上述步骤中第二个token***代码主要分为两个文件:
运行hotel.py获得指定城市的所有7天酒店列表,用SQLite进行存储,因为每个城市只需要最多几次的请求,所以没有引入多线程。
运行示例如图:

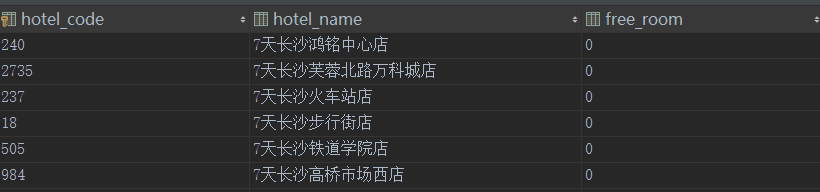
数据库中将存储如下数据。其中其中free_room指的是酒店是否有免费房,默认是0,提供则为1。
运行room.py获得指定城市所有酒店的免费房状态。其中city指定了城市,days指定了查询日期距离当天的天数,例如查询当天信息则为0。
因为一个城市中需要查询的酒店数量在几十个左右,网络IO占据了大量时间,多以引入了多线程来爬取酒店的免费房信息,同时考虑到不要给服务器带来太大的负担,因此只是在一秒钟进行10个请求。
运行示例如下: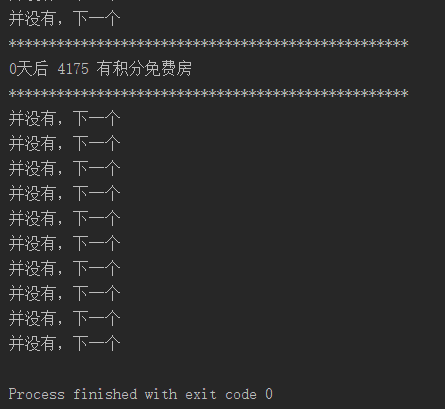
更新与:2016年8月5日17:34:35
服务器对于同一IP的大量访问会封IP,因此加入了代理。
目前使用的是VPN,下一步目标是从IP代理网站爬取代理IP,维护一个代理IP池进行代理。

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









