



tornado iostream篇:
iostream是为了对sokcet异步调用而封装的类, 在后面的httpserver中, tornado会为每一个socket创建一个iostream来对应一个httpconnection
函数如下:
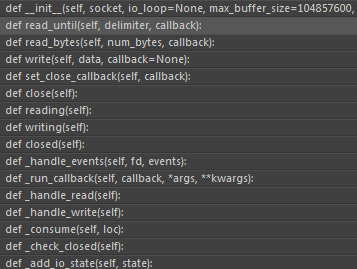
对外有四个函数, 其中主要的read_until, read_bytes, write三个函数
read_until传入两个参数: 读取的结束符和回调函数, 回调函数会把读到的数据作为参数
read_bytes和read_until差不多, 只不过第一个参数是读取的长度
write不用说了就是对socket的写入, 这里要注意的是并不是马上就对socket写入, 而是先写入到缓冲区, 然后改变epoll的状态, 在下一个事件循环中触发写事件再去真正的写入
先介绍一个初始化函数
def __init__(self, socket, io_loop=None, max_buffer_size=104857600,
read_chunk_size=4096):
self.socket = socket //绑定的socket不用说了
self.socket.setblocking(False) //设置非阻塞模式
self.io_loop = io_loop or ioloop.IOLoop.instance() //ioloop主循环
self.max_buffer_size = max_buffer_size //缓冲区大小貌似1G
self.read_chunk_size = read_chunk_size //读区块大小默认4K
self._read_buffer = "" //读缓冲
self._write_buffer = "" //写缓冲
self._read_delimiter = None //读取的结束符 http中是\r\n
self._read_bytes = None //读取的长度, 当http协议是post时, 按照content-length来读取body内容
self._read_callback = None //读回调
self._write_callback = None //写回调
self._close_callback = None //删除回调
self._state = self.io_loop.ERROR
self.io_loop.add_handler(
self.socket.fileno(), self._handle_events, self._state) //添加epoll事件
再来看一看处理epoll事件的函数, 就是上面的_handle_events:
def _handle_events(self, fd, events):
if not self.socket:
logging.warning("Got events for closed stream %d", fd)
return
if events & self.io_loop.READ:
self._handle_read()
if not self.socket:
return
if events & self.io_loop.WRITE:
self._handle_write()
if not self.socket:
return
if events & self.io_loop.ERROR:
self.close()
return
state = self.io_loop.ERROR
#如果没有读取完 还需要继续监听READ事件,
#如果没有_read_bytes或者_read_delimiter, 则不需要监听读事件
#这两个值都是外部调用read和write函数时用的
#在程序运行中其实不太可能存在读写都有的时候,如果真有那么可能程序的逻辑有问题了
#对于_read_delimiter和_read_bytes也是几乎不会同时存在的
if self._read_delimiter or self._read_bytes:
state |= self.io_loop.READ
if self._write_buffer:
state |= self.io_loop.WRITE
if state != self._state:
self._state = state
self.io_loop.update_handler(self.socket.fileno(), self._state)
看一看读写函数即上文的_handle_read和_handle_write:
#读事件, 每次从缓冲区中读取一部分, 默认是4K
def _handle_read(self):
try:
chunk = self.socket.recv(self.read_chunk_size)
except socket.error, e:
#过滤掉非阻塞模式时报的错误
if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
return
else:
logging.warning("Read error on %d: %s",
self.socket.fileno(), e)
self.close()
return
if not chunk:
#当收到消息未空时说明连接关闭, 关掉连接
self.close()
return
self._read_buffer += chunk
if len(self._read_buffer) >= self.max_buffer_size:
logging.error("Reached maximum read buffer size")
self.close()
return
if self._read_bytes:
#如果当前缓存长度大于等于给定的读取长度 说明已经读取完毕
#触发回调函数 清空_read_bytes变量
if len(self._read_buffer) >= self._read_bytes:
num_bytes = self._read_bytes
callback = self._read_callback
self._read_callback = None
self._read_bytes = None
self._run_callback(callback, self._consume(num_bytes))
elif self._read_delimiter:
#如果调用了read_until则查找缓冲区的_read_delimiter如果没有则继续等待
loc = self._read_buffer.find(self._read_delimiter)
if loc != -1:
callback = self._read_callback
delimiter_len = len(self._read_delimiter)
self._read_callback = None
self._read_delimiter = None
self._run_callback(callback,
self._consume(loc + delimiter_len))
# 写函数很简单, 一直写就可以了
def _handle_write(self):
while self._write_buffer:
try:
num_bytes = self.socket.send(self._write_buffer)
self._write_buffer = self._write_buffer[num_bytes:]
except socket.error, e:
if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
break
else:
logging.warning("Write error on %d: %s",
self.socket.fileno(), e)
self.close()
return
if not self._write_buffer and self._write_callback:
callback = self._write_callback
self._write_callback = None
self._run_callback(callback)这是三个辅助函数, 很简单
#读取缓冲区中的数据
def _consume(self, loc):
result = self._read_buffer[:loc]
self._read_buffer = self._read_buffer[loc:]
return result
#检查是否关闭
def _check_closed(self):
if not self.socket:
raise IOError("Stream is closed")
#当当前监听事件不包括需要添加的监听事件时才会更新监听事件
def _add_io_state(self, state):
if not self._state & state:
self._state = self._state | state
self.io_loop.update_handler(self.socket.fileno(), self._state)下面是三个对外暴露的接口:
#先从缓存中查找结束符, 如果查不到需要添加监听读事件
#read_until和read_bytes都会先到缓冲区里面查找, 如果条件不满足的话 去监听读事件
def read_until(self, delimiter, callback):
"""Call callback when we read the given delimiter."""
assert not self._read_callback, "Already reading"
loc = self._read_buffer.find(delimiter)
if loc != -1:
self._run_callback(callback, self._consume(loc + len(delimiter)))
return
self._check_closed()
self._read_delimiter = delimiter
self._read_callback = callback
self._add_io_state(self.io_loop.READ)
def read_bytes(self, num_bytes, callback):
"""Call callback when we read the given number of bytes."""
assert not self._read_callback, "Already reading"
if len(self._read_buffer) >= num_bytes:
callback(self._consume(num_bytes))
return
self._check_closed()
self._read_bytes = num_bytes
self._read_callback = callback
self._add_io_state(self.io_loop.READ)
#添加数据到写缓冲区里面, 并且改变监听事件为写事件,
#在下一个事件循环中触发写事件将缓冲区中的内容写到文件描述符中
def write(self, data, callback=None):
"""Write the given data to this stream.
If callback is given, we call it when all of the buffered write
data has been successfully written to the stream. If there was
previously buffered write data and an old write callback, that
callback is simply overwritten with this new callback.
"""
self._check_closed()
self._write_buffer += data
self._add_io_state(self.io_loop.WRITE)
self._write_callback = callback
iostream大概就这样, 相比来说还算比较简单, 下一篇的httpserver是重点, 也是难点, 不过把iostream和ioloop和http协议理解了也就不难了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









