






一天晚上(2018.3.28),老大根据业务需要在群里出了这么一个问题,题目是这样的:
考虑一个场景,有6个人为一个教练打分,最低一个星(1分),最高5个星(5分),六个人打完分之后,求一个平均分,问这个教练可能拿到的平均分有多少种情况。
群里面一共有4个人,除了老大以外,还有后端小哥A,后端小哥B和我。然后我们分别给出了三种方法。
我的方法 -- 六重循环?
我给出了一个简单粗暴的方法,就是六重循环大法,大概长这个样子:
let average = [];
for(var f=1;f<6;f++){
for(var a=1;a<6;a++){
for(var b=1;b<6;b++){
for(var c=1;c<6;c++){
for(var d=1;d<6;d++){
for(var e=1;e<6;e++){
average.push((a+b+c+d+e+f)/6)
}
}
}
}
}
}
console.log(average.length)
console.log(new Set(average))代码一贴到群里,群里沉默了一分钟,估计是在鄙视我。。。不过笨归笨,我算是给出了一个答案啊,紧接着后端小哥A在群里贴出了一段代码,证明了我答案的正确。
后端小哥A--递归法
上面的代码存在一个明显的问题,就是当人数变成7人的时候,你只能在循环里套一重循环,实现一个人数和平均分种数的函数才是更好的办法。下面是后端小哥A给出的函数,基本思路是递归,用GO实现的: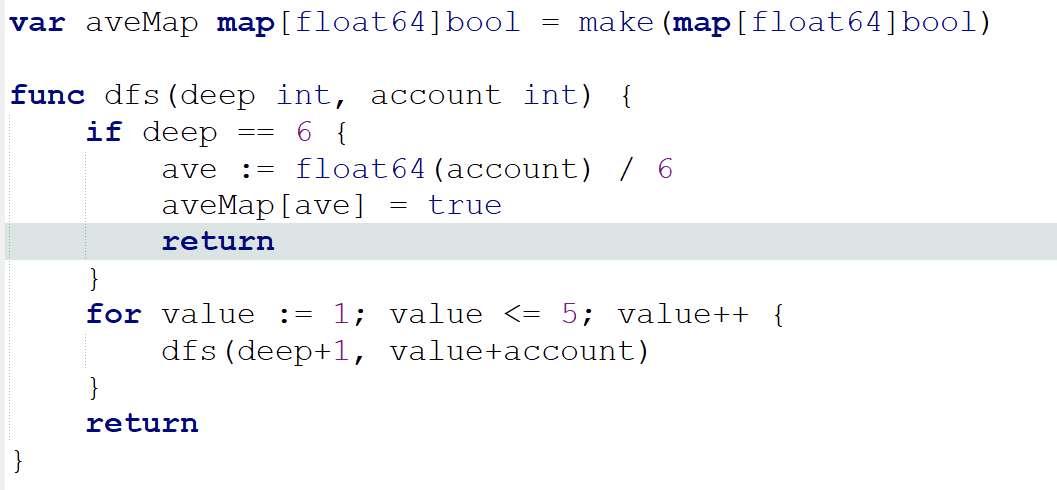
我后来用js又实现了一下。
let averages = new Set();
function getAverage(people, total=0){
if(people === 0){
let aver = total/6;
averages.add(aver);
return;
}
for(let score = 1; score <=5 ; score++){
getAverage(people-1, total+score)
}
}
getAverage(6);
console.log(averages,averages.size);这样,我们只需要改一个数字,就可以得到各种人数下的平均分种类,而不是像上面那样加循环了。然而客观上来说,这个算法还不算高明,尤其是跟后端小哥B的方法比起来
后端小哥B的方法--undefined法
之所以叫undefined法,是因为我也不知道起什么名字好,所以索性就叫undefined吧。同时也显出这个方法的高明,就像武林高手总喜欢隐姓埋名一样。这个方法的思路是这样的:
考虑平均分的情况就是考虑总分的情况,有多少种总分就有多少种平均分。总分最低时是每人打1分,最高时是每人打5分,也就是6-30,共25种情况,所以平均分也就有25种情况
所以说,算法好了,真的是可以为所欲为的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









