1、解析身份证号码
源代码
citizenID = input("请输入身份证号码:")
province = citizenID[0:2]
city = citizenID[2:4]
county = citizenID[4:6]
year = citizenID[6:10]
month = citizenID[10:12]
day = citizenID[12:14]
area = citizenID[14:16]
sexCode = citizenID[16]
checkNumber = citizenID[17]
sex = "男"
if ((int(sexCode)) % 2 == 0):
sex = "女"
print("省:{},市:{},区:{},年:{},月:{},日:{},派出所:{},性别:{}, 校验码:{}".format(province, city, county, year, month, day, area, sex,checkNumber))
print("(注:地区编码请参考全国地区编码表)")
结果

2、凯撒密码编码与解码
源代码
choose = input("请选择模式: 1.加密 2.解密 :")
ch = int(choose)
def encode(txt, ofs): # 加密
t = ""
for ch in txt:
if 'a' <= ch <= 'z':
t += chr(ord('a') + ((ord(ch) - ord('a')) + ofs) % 26)
elif 'A' <= ch <= 'Z':
t += chr(ord('A') + ((ord(ch) - ord('A')) + ofs) % 26)
else:
t += ch
return t
def decode(txt, ofs): # 解密
t = ""
for ch in txt:
if 'a' <= ch <= 'z':
t += chr(ord('a') + ((ord(ch) - ord('a')) - ofs) % 26)
elif 'A' <= ch <= 'Z':
t += chr(ord('A') + ((ord(ch) - ord('A')) - ofs) % 26)
else:
t += ch
return t
inputTxt = input("请输入文本:")
offset = input("请输入偏移量:")
ofs = int(offset)
if ch == 1:
result = encode(txt=inputTxt, ofs=ofs)
print("加密为:" + result)
else:
result = decode(txt=inputTxt, ofs=ofs)
print("解密为:" + result)
结果


3、网址观察与批量生成
源代码
import webbrowser as web
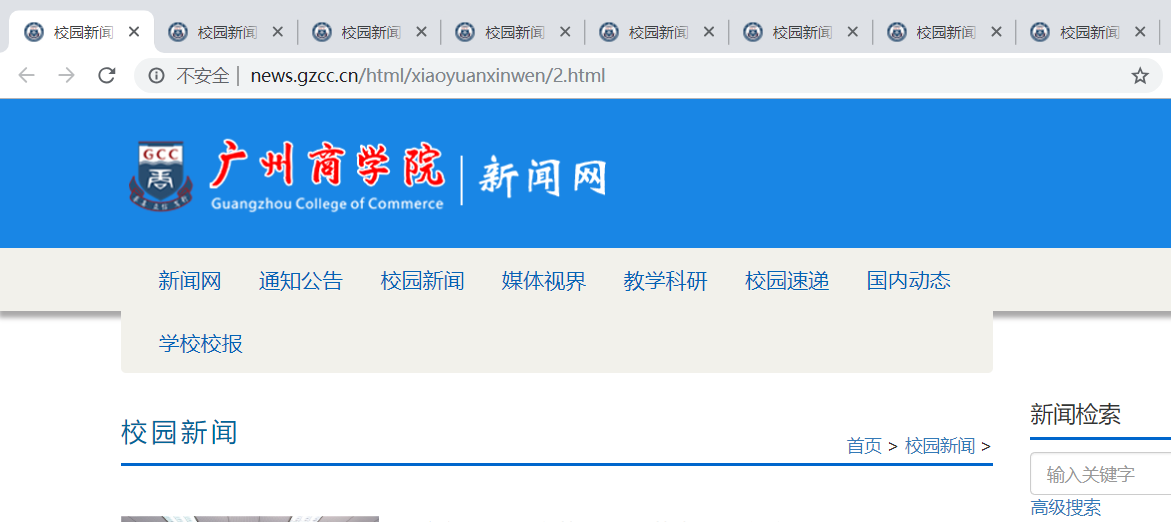
url = "http://news.gzcc.cn/html/xiaoyuanxinwen/2.html"
web.open_new_tab(url)
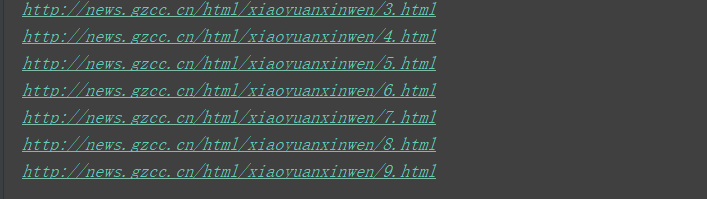
for i in range(3, 10):
url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' + str(i) + '.html'
web.open_new_tab(url)
print(url)
结果
4、英文词频统计预处理
源代码
fo = open(r'G:\test\song.txt', encoding='utf-8')
text = fo.read()
fo.close()
text = text.lower() # 转换成小写
sep = ",.?!:''\n'"
for s in sep: # 去除各种符号,用空格代替
text = text.replace(s, ' ')
allWord = text.split(' ') # 分隔出单词
result = [] # 存储不重复的单词
print("单词 个数")
for b in allWord:
isRepeat = False
for c in result:
if b == c:
isRepeat=True
if isRepeat == False: # 若未出现在result字典里,则加入
result.append(b)
for ch in result:
if ch != '':
print("{:<10} {:<5}".format(ch, allWord.count(ch))) # 格式化输出
结果


 学生编程作业详解
学生编程作业详解







 本文详细介绍学生编程作业的四个部分:身份证号码解析、凯撒密码的编码与解码、网址观察与批量生成、英文词频统计预处理。通过具体源代码展示,帮助读者理解并掌握这些编程技能。
本文详细介绍学生编程作业的四个部分:身份证号码解析、凯撒密码的编码与解码、网址观察与批量生成、英文词频统计预处理。通过具体源代码展示,帮助读者理解并掌握这些编程技能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









