



 本文全面介绍了Python中的68个内置函数,分为作用域相关、迭代器生成器相关、基础数据类型相关等六大类。深入讲解了每类函数的特点及应用场景,并提供了大量实例代码。
本文全面介绍了Python中的68个内置函数,分为作用域相关、迭代器生成器相关、基础数据类型相关等六大类。深入讲解了每类函数的特点及应用场景,并提供了大量实例代码。
引子
什么是内置函数?
内置函数就是python 提供给我们直接拿来就可以用的函数
内置函数--内置命名空间
只管调用 不管实现
总共68个
def func(): == #这是自己定义的函数
pass
print() == #这是python 提供的内置函数
内置函数分为六大类,总数68个:
1.作用域相关的有两个
2.迭代器生成器相关的有三个
3.基础数据类型相关的有三十八个
4..面向对象相关的有九个
5.反射相关的有四个
6.其他的有十二个
标红色的为必会方法...不....会....混...不....下..去...
第一类:作用域相关函数两个
局部作用域中的变量 —— locals() #本地
全局作用域中的变量 —— globals()
在全局执行这两个方法,结果相同
在局部执行,locals表示函数内的名字,globals始终不变


def func(): x = 1 y = 2 print(locals()) print(globals()) func()
第二类迭代器生成器相关函数的有三个
iter , next , range
所有可以调用双下方法的都可以写成加 () 执行
next() 会在生成器中常用到
range() 会常用到 范围和步长
iter() 不常用 ,只要是可迭代的都会有iter方法
在python里 要尽量少去调用双下方法
# def iter(iterable):
# return iterable.__iter__()
#print([1,2,3].__iter__()) #内置的特殊成员
# iterator = iter({1,2,3,4})
# # def next(iterator):
# # return iterator.__next__()
# print(next(iterator)) #iterator.__next__()
# print(next(iterator))
# print(next(iterator))
range(100) #[0,99] [0,100)
range(10,100) #[10,99]
range(10,100,2) #[10,99]隔一个取一个
#可迭代对象 最好循环取结果
第三类其他类十二个
小类1>>字符串类型代码执行
eval exec compile
compile不要随便用 最好不用 危险系数五颗星*****
#直接拿来执行的方式一定不要随便用
#如果非用不可,你也要做最起码的检测
eval : 有返回值
exec :没有返回值
complie:当需要对某一个字符串数据类型的python代码多次执行的时候,就是用compile先编译一下
# code1 = 'for i in range(0,10): print (i)'
# compile1 = compile(code1,'','exec') #编译
# # print(compile1) #code
# exec(compile1)
# code2 = '1 + 2 + 3 + 4'
# compile2 = compile(code2,'','eval')
# print(eval(compile2))
# name = 'egon'
# code3 = 'name = input("please input your name:")'
# compile3 = compile(code3,'','single')
# exec(compile3)
# print(name)
小类2>>输入输出
inpurt 和 print
input输入时最好加上一些标识符 更好理解的去输入
print 重点有几个方法 sep='***' end=' ' file=f
结合代码去理解
#a = input('>>>')
# print(11232)
# print(11232,1234,sep='***')
# print('ajkdshkljaf',end=' ')
# print('sagjkg')
# print(12,34,56,sep=',')
# print('%d,%d,%d'%(12,34,56))
# f = open('print_test','a',encoding='utf-8')
# print(12146798,file=f)
*************************************************
import time
for i in range(0,101,2):
time.sleep(0.1)
char_num = i//2 #打印多少个'*'
per_str = '\r%s%% : %s\n' % (i, '*' * char_num) if i == 100 else '\r%s%% : %s'%(i,'*'*char_num)
print(per_str,end='', flush=True)
\r 可以把光标移动到行首但不换行
**************************************************
import sys
# for i in range(10):
# time.sleep(0.1)
# print(i*'*',end='')
# # sys.stdout.flush()
小类3内存相关>>hash和id
hash
hash的结果是拿到一个不变的数字和数据库相关
但是重复哈希的值会变 这和算法有关
可变的数据类型都不可以被哈希 --列表 字典 集合
**************************************************
id 标志着一个数据的内存地址
is is not 不仅比较值的大小还比较内存地址是否一致
身份运算 ==只比较值的大小
# hashlib模块
# print(hash('sdfsdf'))
# print(hash('sdfsdf'))
# print(hash('sdfsdf'))
# print(hash('sdfsdf'))
# 是一种摘要算法 每次hash的结果都不一样
# print(hash((1,2,3,4,5,6,7)))
# print(hash([12,2,54]))#可变的数据类型都不可以被哈希 列表 字典 集合
#hash的结果是一个数字
# hash作用 作为字典的key
# 数据库 字典
# hash在python的一次执行中,对于相同的可hash对象来说
#
#
# id()标志着一个数据的内存地址
# is is not 不仅比较值的大小还比较内存地址是否一致
# 身份运算 ==只比较值的大小
小类4>>文件操作相关 open()
小类5>>模块相关__import__但是要这样用 import
小类6>>帮助 help() 退出 是q
小类7>>调用相关 判断是否可调用 callable
小类8>>查看内置属性 dir()看到数据类型里面有什么方法/内置属性
print(dir(__builtins__)) 查看所有的
第四类基础数据类型相关的有三十八个
基础数据类型分为两大类 : 数字相关里有三小类 和 数据结构相关 里有三小类
...... .. .......
数字相关分为 1.数据类型 2.进制转换 3.数学运算
数据结构相关分为 4. 序列 5.数据集合 6.相关内置函数
1.数据类型 包括 布尔bool , int , float ,complex
bool() :bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False 返回值 返回 Ture 或 False。
int () :int() 函数用于将一个字符串会数字转换为整型,去浮点数,也就是转换成数字
print(type(int('123'))) print(type('123'))用于强转数据类型
float() :float()函数用于将整数和字符串转换成浮点数。 就是加上了末尾的小数点
compile():compile() 函数将一个字符串编译为字节代码。
2. 进制转换 包括 bin oct hex
bin:转换为二进制 oct 转换成八进制 hex 转化成十六进制
3.数学运算 包括 abs divmod round pow sum min max (都是重点)
abs:计数绝对值 相当于负数都是正数然后去计算
divmod:返回商取余 ,用于分页
# ret = divmod(21, 5) # print(ret) # #商4余1 用于分页 # #105 分10页 余 5 11页 # ret = divmod(105, 10) # print(ret)
round: 幂运算 print(pow(2,3))
sum: 求和 print(sum([1,2,3,4,5],'本钱')) print(sum(range(100)))
min: 计算最小值 max:计算最大值
可以接收散列的值,和可迭代的对象 key是一个函数名,判断的结果根据函数的返回值来确定
defult 如果可迭代对象为空,设置默认最小值
print(min(range(20))) print(min([1,2,3,4,5])) print(max([1,2,3,4,5])) print(min([-1,-5,6],key=abs))装成绝对值 计算 print(max([1,-8,6],key=abs))装成绝对值 计算 key根据函数的返回值 来判断大小 min max 可以接收散列的名 和可迭代对象 key 是一个函数名 根据函数的返回值 来判断大小
4.序列:包括列表和原组 list tuple 主要用于强转 reversed 反转 slice 相当于切片
list() 方法用于将元组转换为列表。tuple() 函数将列表转换为元组。
注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。
tuple({1:2,3:4}) #针对字典 会返回字典的key组成的tuple (1, 3)
aList = [123, 'xyz', 'zara', 'abc'];
aTuple = tuple(aList)
Tuple elements : (123, 'xyz', 'zara', 'abc')
aTuple = (123, 'xyz', 'zara', 'abc');
aList = list(aTuple)
列表元素 : [123, 'xyz', 'zara', 'abc']
reversed() 反转数据 就是倒着输出
ret = reversed([1,2,3,4]) print (list(ret)) print (set(ret)) ret = reversed(range(0,20)) # print(list(ret)) # print(tuple(ret)) ret = reversed('ajagjfd') # print(ret) print('323'.join(list(ret)))
4.1字符串类型 包括: str format bytes bytearray memoryview ord chr ascii repr
str:强转字符串
format:格式化输出
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
....................................................
#!/usr/bin/python
# -*- coding: UTF-8 -*-
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是可选的
format
#字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐
print(format('test', '<20'))
print(format('test', '>20'))
print(format('test', '^20'))
bytes:转换成为bytes直接编码 解码需要decode
# s = 'alex' # by = bytes(s,encoding='utf-8') #新华字典第n页第m行第k个 # print(by) # print(by.decode('utf-8'))
bytearray:修改字符编码组 但是修改完不改变内存地址 但是需要记住编码号
#array == 数组 #alex [a,l,e,x] # s = 'alex' # ret = bytearray(s,encoding='utf-8') # print(id(ret)) # ret[0] = 65 # print(ret,id(ret)) # s = ret.decode('utf-8')
memoryview :转化为字符组 进行节省内存的切片操作
ord:字符按照unicode转数字
chr:数字按照unicode转字符
ascii:字符串转ascaii
repr:用于%r格式化输出 大白话就是保留原始输入的数据类型,不会进行任何改变
5.数据集合:包括字典dict()和集合() 和 frozenset()转变为不可变的集合
字典:dict 用于构建字典
集合:set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
x = set('runoob') y = set('google') print(x,y) 删除重复原素 还可以进行 交并差集计算
frozenset():转变为不可变的集合 这种方法去掉了删除功能
frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
6.相关内置函数
len:计算数据长度 字典根据一对是一个值 来计算
enumerate:enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter'] >>> list(enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')] >>> list(enumerate(seasons, start=1)) # 小标从 1 开始 [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')] 普通的 for 循环 >>>i = 0 >>> seq = ['one', 'two', 'three'] >>> for element in seq: ... print i, seq[i] ... i +=1 ... 0 one 1 two 2 three for 循环使用 enumerate >>>seq = ['one', 'two', 'three'] >>> for i, element in enumerate(seq): ... print i, seq[i] ... 0 one 1 two 2 three >>>
all:判断 是否有bool值为fales的值 只要有一个不是真就返回fales
any:判断 是否有bool值为True的值 只要有一个是真就返回True
zip:zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同 通俗理解就是两个元素相加得到相对应的列表中的元组集合
>>>a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)] #zip # l = (12,3,4,5,6,7) # l2 = ('a','b','c','d') # l3 = [9,8,7] # ret = zip(l,l2,l3) # for i in ret: # print(i)
匿名函数
lambda表达式应用
Python中的lambda表达式就是匿名函数,也就是没有名字的函数。lambda表达式的语法非常简单:
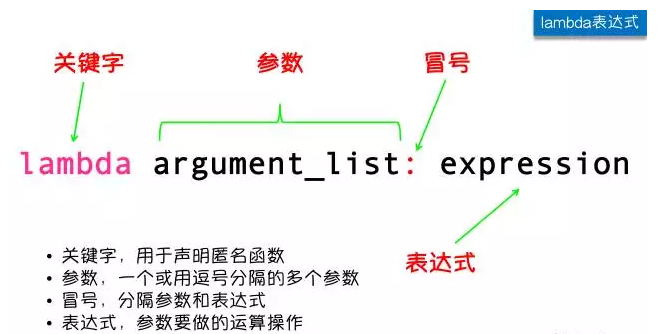
下图是定义lambda表达式和定义一个普通函数的对比:
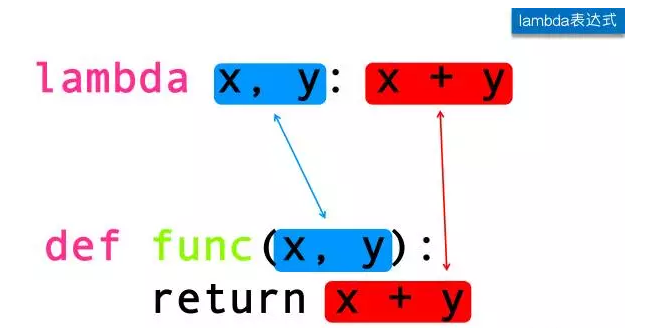
lambda表达式通常是配合其他的内置函数一起使用,以达到简化代码使代码逻辑更清晰的目的。
注意:
使用lambda表达式并不能提高代码的运行效率,它只能让你的代码看起来简洁一些。
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式

#普通函数
1 def func(a):
2 return a+1
3 print 'test1_func0:',func(1000)
4
#lambda表达式 5 func0 = lambda a:a+1 6 print 'test2_func0:',func0(1000)
上面这种方法,都实现了将1000+1的结果打印出来这个功能,但是用下面
lambda存在意义就是对简单函数的简洁表示。
说道lambda,这里再赠送一些可以给lambda加buff小伙伴:
1.map函数,我们使用map函数将会对列表中的所有元素进行操作。map有两个参数(函数,列表),它会在内部遍历列表中的每一个元素,执行传递过来的函数参数。在输出到新列表中。
1 li = [11, 22, 33]
2 new_list = map(lambda a: a + 100, li)
输出:[111, 122, 133]
当然,map还可以完成多个数组的相加:
1 li = [11, 22, 33]
2 sl = [1, 2, 3]
3 new_list = map(lambda a, b: a + b, li, sl) 4 print new_list
输出:[12, 24, 36]
2.reduce函数,对于序列内所有元素进行累计操作:
1 lst = [11,22,33]
2 func2 = reduce(lambda arg1,arg2:arg1+arg2,lst)
3 print 'func2:',func2
输出:func2: 66
3.filter函数,他可以根据条件对数据进行过滤:
1 li = [11, 22, 33]
2 new_list = filter(lambda arg: arg > 22, li)
3 print new_list
输出:[33]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









