






环境:
centos7
jdk8
1.创建Logstash源
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch touch /etc/yum.repos.d/logstash.repo vi /etc/yum.repos.d/logstash.repo [logstash-5.x] name=Elasticsearch repository for 5.x packages baseurl=https://artifacts.elastic.co/packages/5.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
2.使用yum安装logstash
yum makecache
yum install logstash -y
3.利用 log4j 搜集日志
a.pom.xml 引入
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.9</version>
<scope>provided</scope>
</dependency>
b.log4j.properties添加
log4j.rootLogger = debug, socket log4j.appender.socket=org.apache.log4j.net.SocketAppender log4j.appender.socket.Port=5044 log4j.appender.socket.RemoteHost=192.168.158.128 log4j.appender.socket.layout = org.apache.log4j.PatternLayout log4j.appender.socket.layout.ConversionPattern = %d [%t] %-5p %c - %m%n
c.在logstash服务器上添加配置 log4j-to-es.conf
output 是输出到elasticsearch,可翻阅前面的文章 elk之elasticsearch安装
input {log4j {type => "log4j-json" port => 5044}}
output {
elasticsearch {
action => "index"
hosts => "192.168.158.128:9200"
index => "applog"
}
}
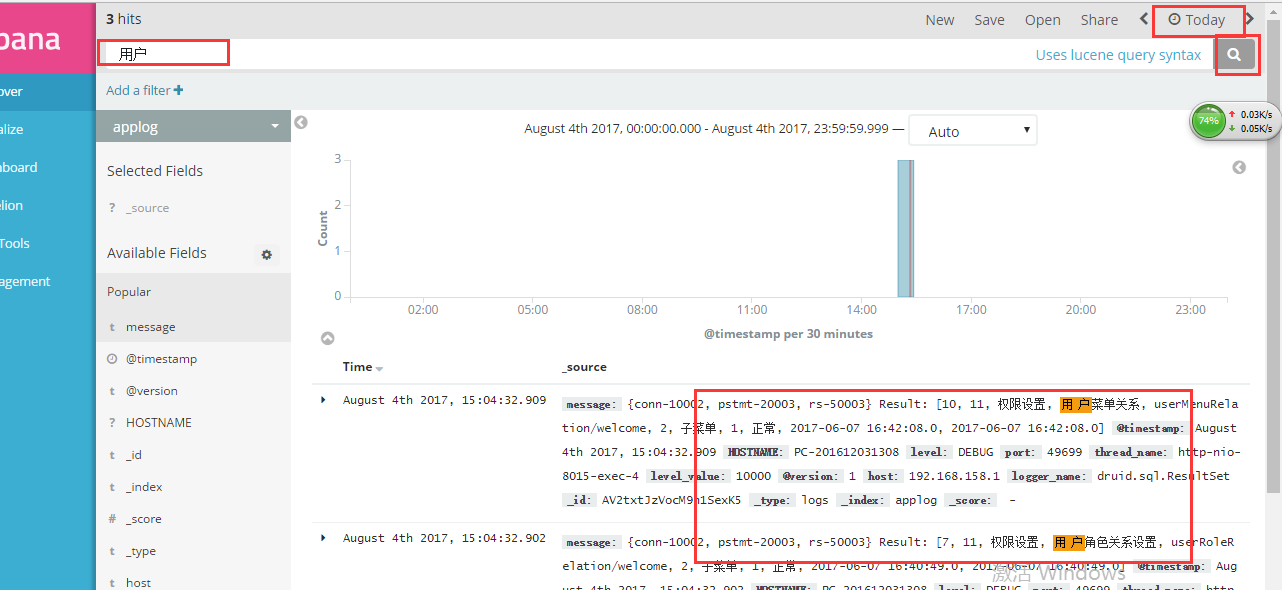
然后重启 logstash ,打开kibana 指定 index or pattern 为我们这里配置的 applog,设置搜索时间就可以查看到日志了
4.利用logback 搜集日志
a.pom.xml 引入
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>4.6</version>
</dependency>
b.配置logback.xml,添加appender
<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- 文件输出格式 --> <property name="PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{50} - %msg%n" /> <!-- test文件路径 --> <property name="LOG_HOME" value="C:/Users/Administrator/Desktop/logs" /> <!-- 控制台输出 --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符 --> <pattern>${PATTERN}</pattern> </encoder> </appender> <!-- logstash 收集日志 --> <appender name="stash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>192.168.158.128:5044</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" /> </appender> <!-- 按照每天生成日志文件 --> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <!--日志文件输出的文件名 --> <FileNamePattern>${LOG_HOME}/yun.%d{yyyyMMdd}.log </FileNamePattern> <!--日志文件保留天数 --> <!-- <MaxHistory>30</MaxHistory> --> </rollingPolicy> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符 --> <pattern>${PATTERN}</pattern> </encoder> <!--日志文件最大的大小 --> <triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy"> <MaxFileSize>500MB</MaxFileSize> </triggeringPolicy> </appender> <logger name="org.springframework.web" level="DEBUG" additivity="false"> <appender-ref ref="STDOUT" /> </logger> <logger name="druid.sql" level="DEBUG" additivity="false"> <appender-ref ref="FILE" /> <appender-ref ref="STDOUT" /> <appender-ref ref="stash" /> </logger> <logger name="com.yun" level="DEBUG" additivity="false"> <appender-ref ref="FILE" /> <appender-ref ref="STDOUT" /> <appender-ref ref="stash" /> </logger> <!-- 日志输出级别 --> <root level="DEBUG"> <appender-ref ref="FILE" /> <appender-ref ref="STDOUT" /> <appender-ref ref="stash" /> </root> </configuration>
c.logstash服务器上添加配置 logback-to-es.conf
input {tcp {port => 5044 codec => "json_lines"}}
output {
elasticsearch {
action => "index"
hosts => "192.168.158.128:9200"
index => "applog"
}
}
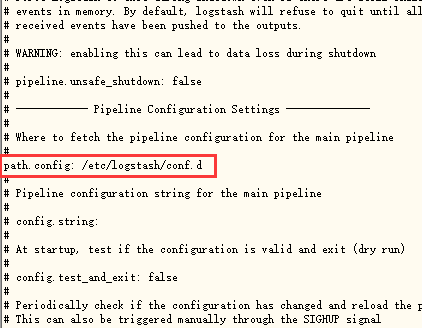
配置目录请认准 /etc/logstash/conf.d
可以打开 logstash.yml 查看 cat /etc/logstash/logstash.yml
d.重启logstash,启动项目产生日志,然后去kibana 查看日志
5.利用filebeat搜集日志

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









