



 本文对比了UsingtheAlphaChannel和DoitTwice两种深度处理技术,前者直接在物体绘制阶段计算深度并存储,后者通过额外的深度通道和后缓存绘制阶段进行深度信息的获取和使用。
本文对比了UsingtheAlphaChannel和DoitTwice两种深度处理技术,前者直接在物体绘制阶段计算深度并存储,后者通过额外的深度通道和后缓存绘制阶段进行深度信息的获取和使用。
我们跟Using the Alpha Channel进行一下对比:
1. Using Alpha Channel这个例子中,物体的深度直接在物体绘制的Vertex Shader中计算出来,然后route到Pixel Shader中,再在Pixel Shader利用景深计算公式(公式自变量就是深度)
1 float Blur = max(clamp(0,1, 1 - (Depth-Near_Dist)/Near_Range),
2 clamp(0,1,(Depth-(Far_Dist-Far_Range))/Far_Range));
再进一步将Blur值存入到绘制物体的可渲染纹理。
最终的后缓存绘制Pass中,直接读取每个像素的Blur值对RenderTarget及模糊后的RenderTarget进行插值。
2. Do it Twice并没有在物体绘制阶段进行任何深度存储。而是重新添加了两个Depth Pass,将物体重新绘制一编,并且在Vertex Shader计算出深度,route到Pixel Shader中,注意在Pixel Shader中没有直接根据深度值计算Blur Amount,而是将32bit的深度值pack到了另外添加的可渲染纹理表面。
虽然可渲染纹理是32bit,深度也是32bit的,但是并不能直接将深度值赋值给可渲染纹理,因为可渲染纹理纹理是8bit一个单元(RGBA各占8个),作者将32bit纹理稍微做了一下压缩,pack到了16bit然后存到了纹理中。之所以这么做是因为那个时候硬件不支持浮点数可渲染纹理,如果支持的话,就不用这么麻烦了(现在的显卡早就支持浮点可渲染纹理了,我用DXCpas View看了下自己显卡(GT240)的Caps,D3DUSAGE_RENDERTARGET 的D3DFMT_A32B32G32R32F正好是YES,无压力,阿门!O(∩_∩)O哈哈~)。
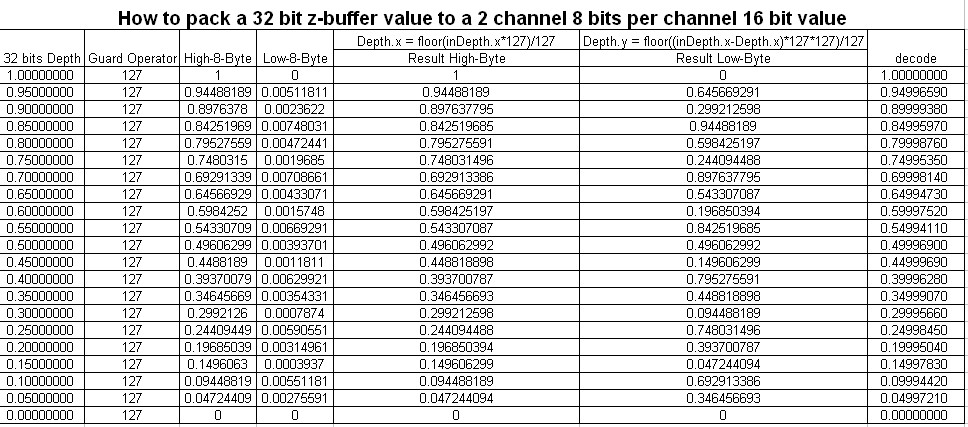
Depth pack 把32位的深度压缩到16位中了一些精度,我做了一个表,把精度损失做了个对比:
第一列是未pack前的深度,最后一列是pack后的深度,可以看出,误差大概到小数点第五六位了,差别不是太大。
然后在绘制后缓存的Pass中,对保存了深度值的Depth RT进行逐像素采样,再根据
1 float Blur = max(clamp(0,1, 1 - (Depth-Near_Dist)/Near_Range),
2 clamp(0,1,(Depth-(Far_Dist-Far_Range))/Far_Range));
中计算出来的Blur对RenderTarget(RT)和模糊后的RenderTarget(RT)进行插值运算。
注:为什么要对32bitW深度进行pack,请看下边的图,
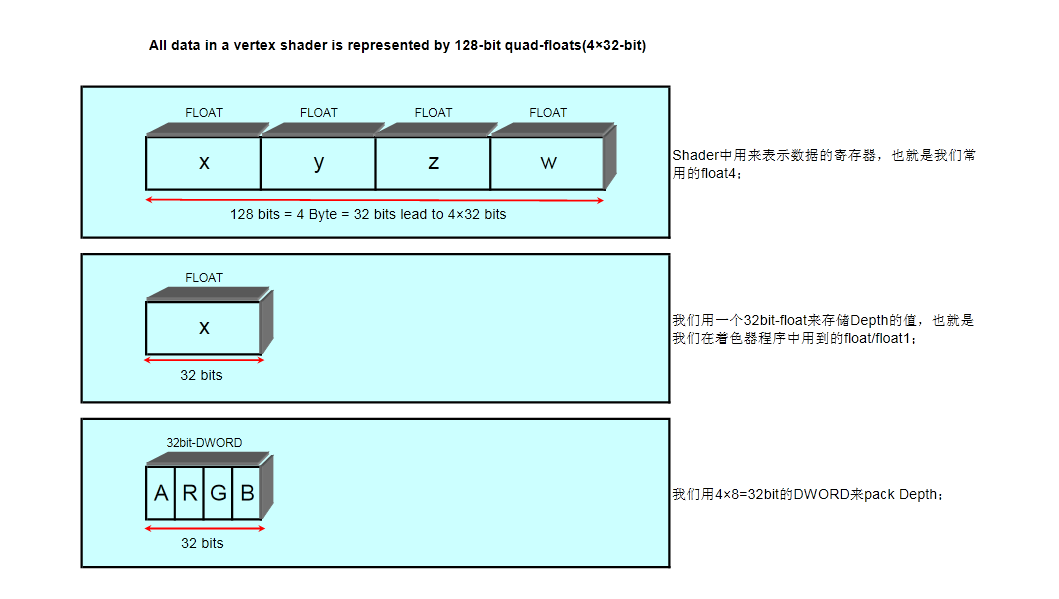
如果我们将32bit的W深度值直接赋值给组成可渲染纹理32Bit-DWORD值,W深度会被截取到32bit的DWORD进行截取存储!

















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









