



 本文介绍了XML的基础知识,包括其用途、语法特点及与JSON的区别,并详细讲解了使用Python的DOM方式进行XML解析的方法。
本文介绍了XML的基础知识,包括其用途、语法特点及与JSON的区别,并详细讲解了使用Python的DOM方式进行XML解析的方法。
0. XML 基础
参考文档:http://www.runoob.com/xml/xml-tutorial.html
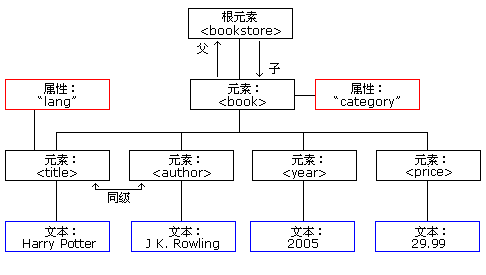
0A. XML 特性
- XML 用于传输数据,而不是显示数据 <--> HTML
- 具有自我描述性
- 没有预定义的标签
0B. XML 语法
- XML申明(可选):<?xml version="1.0" encoding="UTF-8"?>
- XML 文档形成一种树结构:element; attribute; element content
- 根元素(必有)
- 所有XML 元素都必须有一个关闭标签(与HTML不同)
- 对大小写敏感
- 元素必须正确嵌套
- 属性值必须加引号
- 实体引用 “<”<-->“<” ,“>”<-->“>” ,“&”<-->“&” ,“'”<-->“'” ,“"”<-->“"”
- 注释:<!-- This is a comment -->
- 空格会被保留
- 以 LF 存储换行
0C. XML 与 JSON 主要组成成分区别
- XML是element、attribute和element content
- JSON是object、 array、string、number、boolean(true/false)和null
1. DOM 解析XML
Python主要有三种方式解析XML:
- SAX (simple API for XML)
- DOM(Document Object Model)
- ElementTree(元素树)
参考文档:
https://docs.python.org/2/library/xml.dom.minidom.html;
https://docs.python.org/2/library/xml.dom.html
DOM中所有对象类型:
| Interface | Section | Purpose |
|---|---|---|
DOMImplementation | DOMImplementation Objects | Interface to the underlying implementation. |
Node | Node Objects | Base interface for most objects in a document. |
NodeList | NodeList Objects | Interface for a sequence of nodes. |
DocumentType | DocumentType Objects | Information about the declarations needed to process a document. |
Document | Document Objects | Object which represents an entire document. |
Element | Element Objects | Element nodes in the document hierarchy. |
Attr | Attr Objects | Attribute value nodes on element nodes. |
Comment | Comment Objects | Representation of comments in the source document. |
Text | Text and CDATASection Objects | Nodes containing textual content from the document. |
ProcessingInstruction | ProcessingInstruction Objects | Processing instruction representation. |
- 其中最重要是Node类,他是实现XML所有组成部分的父类,他的子类包括:Document;Element;Attr;Comment;Text;ProcessingInstruction
- 通过getElementsByTagName()和getElementsByTagNameNS()方法会得到Node类的集合,即NodeList
- DocumentType为定义文档、标签含义用法等,譬如testng中的xml文件头部:<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
DOM Node类型
参考文档:http://www.w3school.com.cn/xmldom/dom_nodetype.asp
| 节点类型 | Named Constant | 描述 | nodeName 的返回值 | nodeValue 的返回值 | nodeType 的返回值 |
| Element | ELEMENT_NODE | element(元素)元素 | element name | null | 1 |
| Attr | ATTRIBUTE_NODE | 属性。 | 属性名称 | 属性值 | 2 |
| Text | TEXT_NODE | 元素或属性中的文本内容。 | #text | 节点内容 | 3 |
| CDATASection | CDATA_SECTION_NODE | 表示文档中的 CDATA 区段(文本不会被解析器解析) | #cdata-section | 节点内容 | 4 |
| EntityReference | ENTITY_REFERENCE_NODE | 实体引用元素。 | 实体引用名称 | null | 5 |
| Entity | ENTITY_NODE | 实体。 | 实体名称 | null | 6 |
| ProcessingInstruction | PROCESSING_INSTRUCTION_NODE | 表示处理指令。 | target | 节点的内容 | 7 |
| Comment | COMMENT_NODE | 注释。 | #comment | 注释文本 | 8 |
| Document | DOCUMENT_NODE | 表示整个文档(DOM 树的根节点) | #document | null | 9 |
| DocumentType | DOCUMENT_TYPE_NODE | 向为文档定义的实体提供接口。 | doctype 名称 | null | 10 |
| DocumentFragment | DOCUMENT_FRAGMENT_NODE | 表示轻量级的 Document 对象,其中容纳了一部分文档。 | #document fragment | null | 11 |
| Notation | NOTATION_NODE | 表示在 DTD 中声明的符号。 | 符号名称 | null | 12 |
注意:
XML中所有的数据,包括属性attr,文本内容test,都是node,所以不要直接对标签对nodeValue,而是要获取到childNode[0]后,childNode[0].nodeValue
常用方法
更多方法:https://docs.python.org/2/library/xml.dom.html
#1A. import minidom from xml.dom.minidom import parse, parseString #1B. 解析XML文件成document对象 # parse()可以传入文件名或文件对象 dom1 = parse('c:\\temp\\mydata.xml') # parse an XML file by name datasource = open('c:\\temp\\mydata.xml') dom2 = parse(datasource) # parse an open file #1c. 解析XML字符串 dom3 = parseString('<myxml>Some data<empty/> some more data</myxml>') #1d. 获取根节点 root = dom1.documentElement #1e.获取指定节点下,指定标签名的节点s,返回list elements = root.getElementsByTagName("XXX") #1f.获取子节点s,返回list
elements = root.childNodes
#1g.将节点及其子节点转换为xml(即str),可指定编码:toxml("utf-8") root.toxml()
# 还有一系列对node增删改的方法,可以参看官方手册文档

















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









