






一、Keepalived高可用基本概述
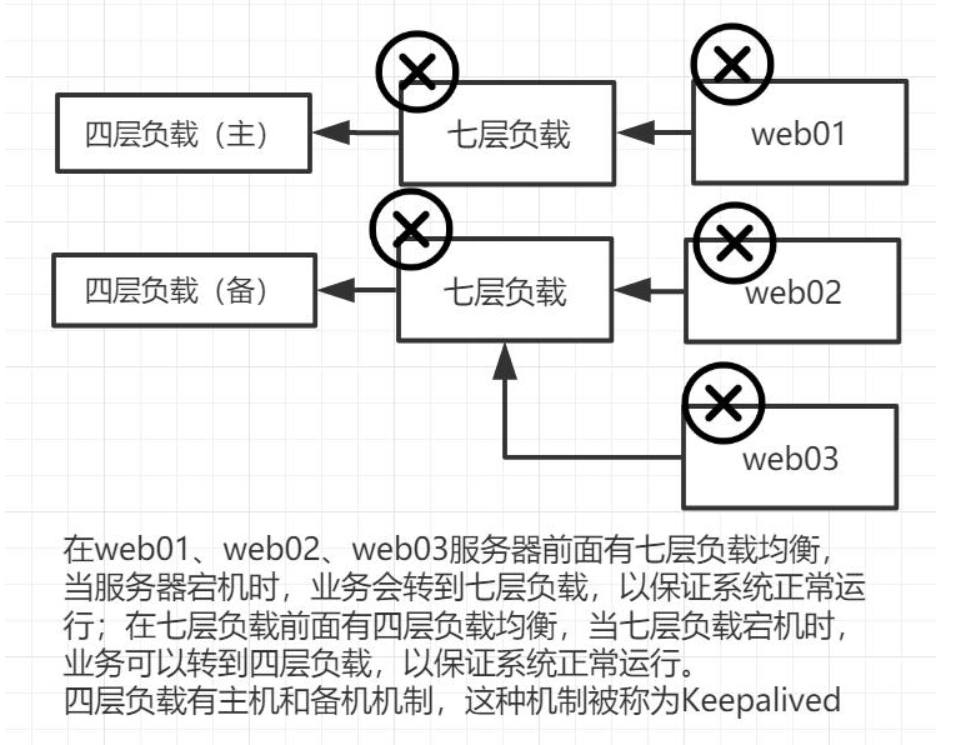
1.1)什么是高可用
一般是指2台机器启动着完全相同的业务系统,当有一台机器down机了,另外一台服务器就能快速的接管,对于访问的用户是无感知的。
现实例子关于keepalived,比如,在公司里,每个部门都有正副经理。平时副经理什么都不管,当经理请假或者不在公司的时候,此时副经理就接替经理的工作。
keepalived软件起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点状态,后来又加入了可以实现高可用的VRRP功能。
keepalived除了能够管理LVS软件外,还可以作为其他服务(例如:Nginx,Haproxy,MySQL等)的高可用解决方案软件。
keepalived软件主要是通过VRRP协议实现高可用功能的。VRRP是Virtual Router Redundancy Protocol(虚拟路由器冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行。Keepalived一方面具有配置管理LVS的功能,同时还具有对LVS下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能。
1.2)高可用通常使用什么软件?
硬件通常使用 F5,软件通常使用 keepalived。
1.3)keepalived服务的重要功能
keepalived服务的重要功能:作为系统网络服务的高可用功能(failover,失效备援)。
keepalived高可用功能实现的基本原理为:
两台主机同时安装好keepalived软件并启动服务,开始正常工作时,角色为Master的主机获得所有资源并对用户提供服务,角色为Backup的主机作为Master主机的热备;
当角色为Master的主机失效或出现故障时,角色为Backup的主机将自动接管Master主机的所有工作,包括接管VIP资源及相应资源服务;
而当角色为Master的主机故障修复后,又会自动接管回他原来处理的工作,角色为Backup的主机则同时释放Master主机失效时他接管的工作,此时,两台主机将恢复到启动时各自的原始角色及工作状态。
1.4)keepalived是如何实现高可用的?
keepalived软件是基于VRRP协议实现的,VRRP虚拟路由冗余协议,主要用于解决单点故障问题。
1.5) 什么是VRRP?原理又是什么?
比如公司的网络是通过网关进行上网的,那么如果该路由器故障了,网关无法转发报文了,此时所有人都无法上网了,怎么办?
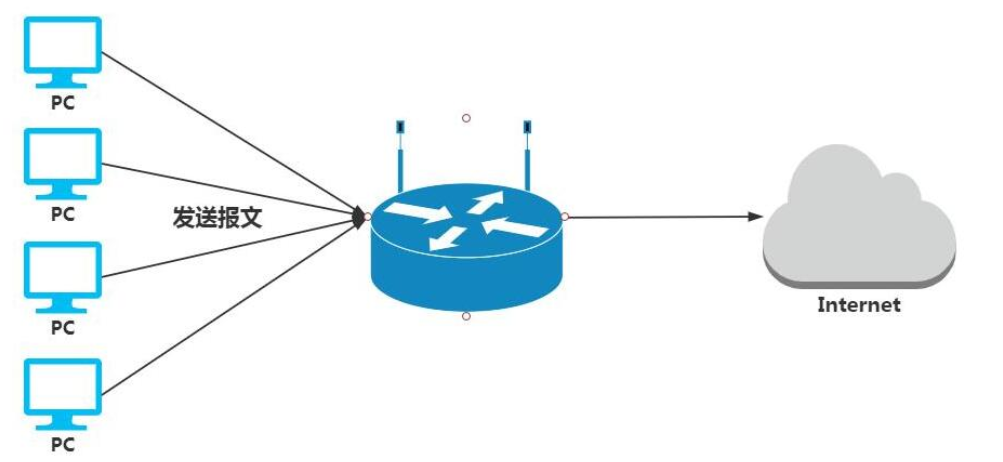
通常做法是给路由器增加一台备节点,但是问题是,如果我们的主网关master故障了,用户是需要手动指向backup的,如果用户过多修改起来会非常麻烦。
问题一:假设用户将指向都修改为backup路由器,那么master路由器修好了怎么办?
问题二:假设Master网关故障,我们将backup网关配置为master网关的ip是否可以?
其实是不行的,因为PC第一次通过ARP广播寻找到Master网关的MAC地址与IP地址后,会将信息写到ARP的缓存表中,那么PC之后连接都是通过那个缓存表的信息去连接,然后进行数据包的转发,即使我们修改了IP但是Mac地址是唯一的,pc的数据包依然会发送给master。(除非是PC的ARP缓存表过期,再次发起ARP广播的时候才能获取新的backup对应的Mac地址与IP地址)
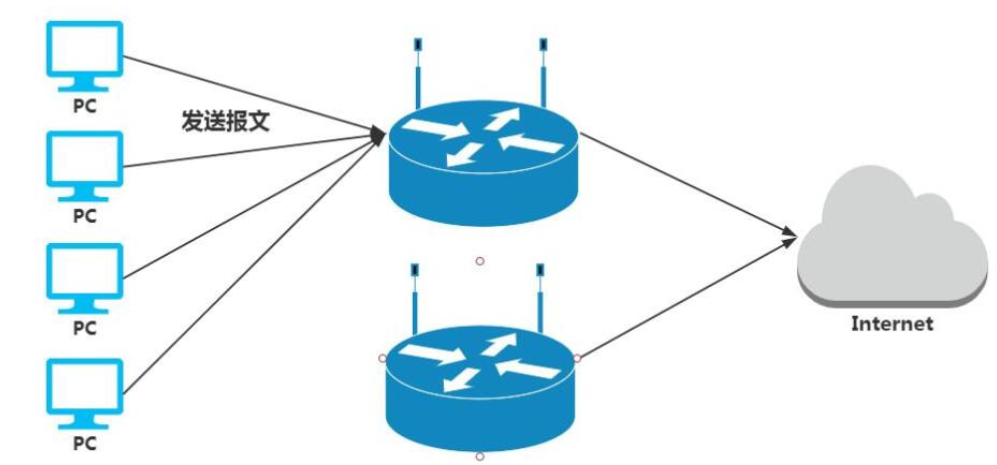
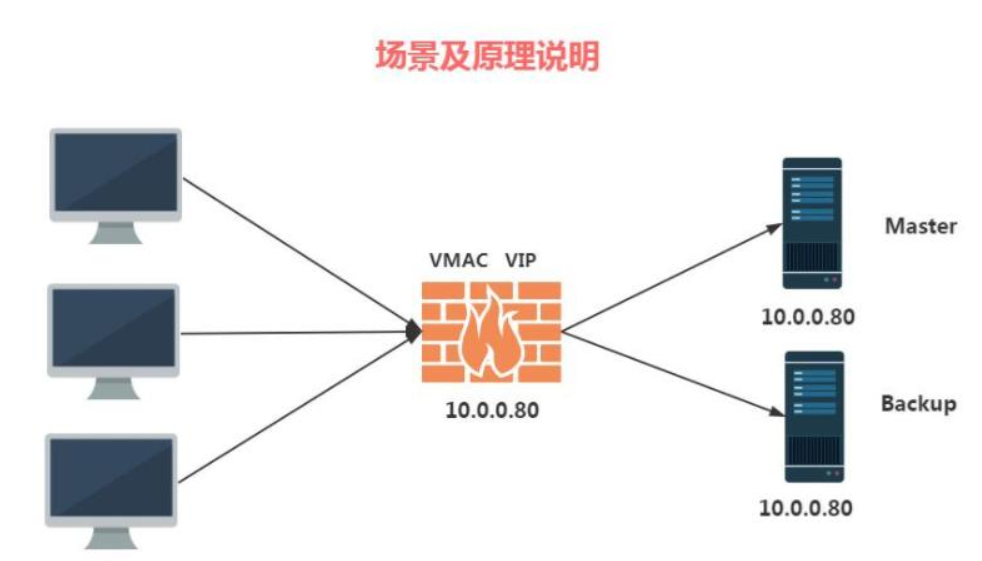
如何才能做到出现故障自动转移,此时VRRP就出现了,我们的VRRP其实是通过软件或者硬件的形式在Master和Backup外面增加一个虚拟的MAC地址(VMAC)与虚拟IP地址(VIP),那么在这种情况下,PC请求VIP的时候,无论是Master处理还是Backup处理,PC仅会在ARP缓存表中记录VMAC与VIP的信息。
VRRP,全称Virtual Router Redundancy Protocol,中文名为虚拟路由冗余协议。
VRRP的出现就是为了解决静态路由的单点故障问题,VRRP是通过一种竞选机制来将路由的任务交给某台VRRP路由器的。
VRRP通过竞选机制来实现虚拟路由器的功能,所有的协议报文都是通过IP多播(Multicast)包(默认的多播地址224。0。0。18)形式发送的。
虚拟路由器由VRID(范围0-255)和一组IP地址组成,对外表现为一个周知的MAC地址,:00-00-5E-00-01-{VRID}。
所以,在一个虚拟路由器中,不管谁是Master,对外都是相同的MAC和IP(称之为VIP)。
客户端主机并不需要因Master的改变修改自己的路由配置。对它们来说,这种切换是透明的。
在一组虚拟路由器中,只有作为Master的VRRP路由器会一直发送VRRP广播包,此时Backup不会抢占Master。
当Master不可用时,Backup就收不到来自Master的广播包了,此时多台Backup中优先级最高的路由器会抢占为Master。
这种抢占是非常快速的(可能只有1秒甚至更少),以保证服务的连续性,处于安全性考虑,VRRP数据包使用了加密协议进行了加密。
1.6)面试的时候怎么说?
keepalived高可用对之间是通过VRRP通信的,因此,我从VRRP开始给您讲起.
1)VRRP,全称Virtual Router Reduancy Protocol,中文名为虚拟路由器冗余协议,VRRP的出现是为了解决静态路由的单点故障;
2)VRRP是通过一种竞选协议来将路由任务交给某台VRRP路由器的;
3)VRRP用IP多播的方式,(默认多播地址(224.0.0.18))实现高可用对之间通信;
4)工作时主节点发包,备节点接包,当备节点接收不到主节点发的包的时候,就启动接管程序接管主节点的资源。备节点可以有多个,通过优先级竞选,但一般keepalived系统运维工作中都是一对。
5)VRRP使用了加密协议加密数据,但keepalived官方目前还是推荐用明文的方式配置认证类型和密码。
介绍完了VRRP,接下来我在介绍一下keepalived服务的工作原理;
keepalived高可用对之间是通过VRRP进行通信的,VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时会优先获得所有的资源,备节点处于等待状态,当主挂了的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务。
在keepalived服务对之间,只有作为主的服务器会一直发送VRRP广播包,告诉备它还活着,此时备不会抢占主。当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性,接管速度最快可以小于一秒。
1.7)高可用keepalived使用场景
通常业务系统需要保证7×24小时不DOWN机,比如公司内部的OA系统,每天公司人员都需要使用,则不允许Down机,作为业务系统来说随时都可用。
1.8) 高可用keepalived使用场景
1)如何确定谁是主节点谁是背节点(选举投票,优先级)
2)如果Master故障,Backup自动接管,那么Master回复后会夺权吗(抢占试、非抢占式)
3)如果两台服务器都认为自己是Master会出现什么问题(脑裂)
二、keepalived高可用服务搭建准备
经过了前面对Keepalived的介绍和原理讲解,相信读者已经初步了解了Keepalived这个高可用软件,下面开始实施之旅。
2.1)安装keepalived环境说明
这里使用前面已经搭建完成的Nginx负载均衡的系统环境来安装Keepalived服务,因为后面的实战案例是实现Nginx负载均衡的高可用案例。
安装Keepalived的基础准备环境如下:
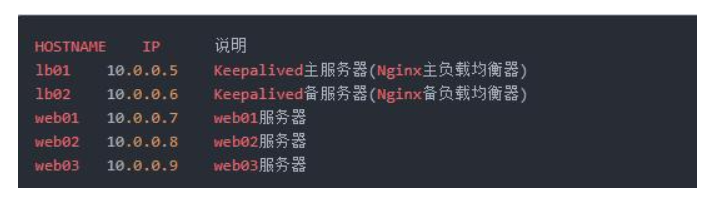
准备5台物理服务器两台做Keepalived服务,3台做测试的web节点。
Keepalived高可用实验环境准备
2.2)安装keepalived软件
注意:lb01和lb02都需要安装。
[root@lb02 ~]# yum install keepalived -y
[root@lb02 ~]# rpm -qa keepalived
keepalived-1.3.5-8.el7_6.5.x86_64
2.3)启动keepalived服务并检查
[root@lb02-e ~]# systemctl start keepalived
[root@lb02-e ~]# ps -ef|grep keepalived
root 10039 1 0 12:21 ? 00:00:00 /usr/sbin/keepalived -D
root 10040 10039 0 12:21 ? 00:00:00 /usr/sbin/keepalived -D
root 10041 10039 0 12:21 ? 00:00:03 /usr/sbin/keepalived -D
###提示:启动后有三个keepalived进程表示安装正确
[root@lb02 ~]# ip a | grep eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute eth0
inet 192.168.200.16/32 scope global eth0
inet 192.168.200.17/32 scope global eth0
inet 192.168.200.18/32 scope global eth0
###提示:默认情况会启动三个VIP地址
[root@lb02-e ~]# systemctl stop keepalived
###提示: 测试完毕后关闭服务,上述测试需要在lb01和lb02两台服务器上进行
2.4)keepalived配置文件说明
和其他yum安装的软件一样,keepalived软件的配置文件默认路径及配置文件名为:
[root@lb02 ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
这里的具备高可用功能keepalived.conf配置文件包含了两个重要区块,下面分别说明:
(1)全局变量(Global Definitions)部分
这部分主要用来设置keepalived的故障通知机制和Router ID标识。示例配置如下:
[root@lb02 ~]# cat -n /etc/keepalived/keepalived.conf
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
5 acassen@firewall.loc
6 failover@firewall.loc
7 sysadmin@firewall.loc
8 }
9 notification_email_from Alexandre.Cassen@firewall.loc
10 smtp_server 192.168.200.1
11 smtp_connect_timeout 30
12 router_id LVS_DEVEL
13 vrrp_skip_check_adv_addr
14 vrrp_strict
15 vrrp_garp_interval 0
16 vrrp_gna_interval 0
17 }
基础参数说明:
第1行是注释,!开头和#号开头一样,都是注释。
第2行是空行。
第3行—8行是定义故障服务报警的Email地址。作用是服务发生切换或RS节点等有故障时,需要发送的Email地址,可以有多个,每行一个。
第9行是制定发送邮件的发送人,即发送人地址,也是可选配置。
第10行smtp_server指定发送邮件的smtp服务器,如果本机开启了sendmail或postfix。就可以使用上面默认配置实现邮件发送,也是可选配置。
第11行smtp_connect_timeout是连接smtp的超时时间,也是可选配置。
第12行是Keepalived服务器的路由标识{route_id}。在一个局域网内,这个标识{route_id}应该是唯一的。
大括号{}用来区分区块,要成对出现。如果漏写了半个大括号,keepalived运行时,不会报错,但是也不会得到预期的结果。另外,由于区块间存在多层嵌套关系,因此很容易遗漏区块结尾处的大括号,需要特别注意。
(2)VRRP实例定义区域(VRRP instance(s))部分
这部分主要用来定义具体服务实例配置,包括Keepalived主备状态,接口,优先级,认证方式和IP信息等,配置如下:
19 vrrp_instance VI_1 {
20 state MASTER
21 interface eth0
22 virtual_router_id 51
23 priority 100
24 advert_int 1
25 authentication {
26 auth_type PASS
27 auth_pass 1111
28 }
29 virtual_ipaddress {
30 192.168.200.16
31 192.168.200.17
32 192.168.200.18
33 }
34 }
参数说明:
第19行表示定义一个vrrp_instance实例,名字为VI_1,每个vrrp_instance实例可以认为是Keepalived服务的一个实例或者作为一个业务服务,在Keepalived服务配置中,这样的vrrp_instance实例可以有多个。 注意,存在于主节点中的vrrp_isntance实例在备节点也要存在,这样才能实现故障切换接管。
第20行state MASTER表示当前示例VI_1的角色状态,当前角色为MASTER,这个状态只能有MASTER和BACKUP两种状态,并且需要大写这些字符。其中MASTER为正式工作的状态,BACKUP为备用的状态。当MASTER所在的服务器故障或失效时,BACKUP所在的服务器会接管故障的MASTER继续提供服务。
第21行interface为网路通信接口。为对外提供服务的网络接口,如eth0,eth1当前主流的服务器都有2~4个网络接口,在选择服务接口时,要搞清楚。
第22行virtual_router_id为虚拟路由ID标识,这个标识最好是一个数字。
第23行priority为优先级,其后面的数值也是一个数字,数字越大,表示实例优先级越高。在同一个vrrp_instance实例里,MASTER的优先级配置要高于BACKUP的。若MASTER的priority值为150,那么BACKUP的priority必须小于150,一般建议隔50以上为佳。
第24行advent_int为同步通知间隔。MASTER与BACKUP之间通信检查的时间间隔,默认为1秒。
第25-27行authentication为权限认证配置。包含认证类型(auth_type)和认证密码(auth_pass) 。认证类型有PASS(simple passwd),AH(IPSEC)两种,官方推荐使用的类型为PASS。验证密码为明文方式,最好长度不能超过8个字符,建议四位数字,同一vrrp实例的MASTER与BACKUP使用相同的密码才能正常通信。
第29-32行virtual_ipaddress为虚拟IP地址。可以配置多个IP地址,每个地址占一行,配置时最好明确指定子网掩码以及虚拟IP绑定的网络接口。否则,子网掩码默认是32位,绑定的接口和前面的interface参数配置的一致。注意,这里的虚拟IP就是在工作中需要和域名绑定的IP,即和配置的高可用服务监听的IP要保持一致。
三、配置keepalived实现单IP自动漂移接管
实际上可以将高可用对的两台机器应用服务同时开启,但是只让VIP一段的服务器提供服务,若主的服务器宕机,VIP会自动漂移到备用服务器,此时用户的请求直接发送到备用服务器上,而无须临时启动对应服务(事先开启应用服务)。下面来讲解VIP自动漂移实战案例。
四、实战配置keepalived主服务器lb01 MASTER
0、准备工作
#优化基本源
[root@lb01-e ~]# vim /etc/yum.repos.d/CentOS-Base.repo
[root@lb02-e ~]# vim /etc/yum.repos.d/CentOS-Base.repo
[root@lb03-e ~]# vim /etc/yum.repos.d/CentOS-Base.repo
1、keepalived安装
[root@lb01 ~]# yum install keepalived -y
[root@lb02 ~]# yum install keepalived -y
2、查看配置文件的路径
[root@lb01 ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
3、配置一台机器的nginx,配置keepalived主服务器lb01 MASTER
#配置keepalived主服务器lb01 MASTER
[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
global_defs { #全局配置
router_id lb01 #keepalived服务器的路由标识(route_id)
}
vrrp_instance VI_1 { #vrrp实例,命名叫VI_1
state MASTER #当前实例VI_1的角色状态
interface eth0 #是对外提供服务的网络接口
virtual_router_id 50 #虚拟路由ID标识
priority 150 #优先级
advert_int 1 #同步通知间隔时间
authentication { #权限认证配置
auth_type PASS #认证方式
auth_pass 1111 #认证密码
}
virtual_ipaddress {
10.0.0.4 #虚拟的VIP地址
}
}
配置完毕后,启动keepalived服务,如下:
#启动keepalived(lb01)
[root@lb01 ~]# systemctl enable keepalived
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@lb01 ~]# systemctl start keepalived
然后检查配置结果,查看是否有虚拟IP10.0.0.4
[root@lb01-e ~]# ip addr | egrep 10.0.0.4
inet 10.0.0.4/32 scope global eth0
出现上述带有vip:10.0.0.3行的结果表示lb01的keepalived服务单实例配置成功。
4、配置另一台机器的nginx,实战配置keepalived备服务器lb02 BACKUP
#实战配置keepalived备服务器lb02 BACKUP
[root@lb02 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.4
}
}
启动lb02的keepalived服务
#启动lb02的keepalived
[root@lb02 ~]# systemctl enable keepalived
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@lb02 ~]# systemctl start keepalived
检查配置结果,查看是否有虚拟IP10.0.0.4
#可以看到地址被lb02接管,即IP地址已发生漂移
[root@lb02 ~]# ip addr | grep 10.0.0.4
这里没有返回任何结果就对了,因为lb02为BACKUP,当主节点活着的时候,他不会接管VIP 10.0.0.4。
出现上述无任何结果的现象,表示lb02的keepailved服务单实例配置成功.如果lv02的配置过滤后有10.0.0.3的IP,则表示keepalived工作不正,同一个IP地址同一时刻应该只能出现在一台服务器上。
如果查看BACKUP备节点VIP有,说明高可用裂脑了,裂脑是两台服务器争抢统一资源导致的,例如:两边都配置了同一个VIP地址。
5、出现脑裂后的排查
出现上述两台服务器争抢同一IP资源问题,一般要先考虑排查两个地方:
(1)主备两台服务器之间是否通讯正常,如果不正常是否有iptables防火墙阻挡?
(2)主备两台服务器对应的keepalived.conf配置文件是否有错误?例如是否同一实例的virtual_router_id配置不一样。
6、进行高可用主备服务器切换
停掉主服务器上的keepalived服务或关闭主服务器,操作并检查步骤
[root@lb01 keepalived]# ip addr|egrep 10.0.0.3
inet 10.0.0.3/24 scope global secondary eth0:1
[root@lb01 ~]# systemctl start keepalived
[root@lb01 keepalived]# ip addr|egrep 10.0.0.3
可以看到VIP 10.0.0.3消失了,此时查看BACKUP备服务器,看是否会有VIP 10.0.0.3出现,操作及检查步骤如下:
[root@LVS-6 ~]# ip addr|egrep 10.0.0.3
[root@LVS-6 ~]# ip addr|egrep 10.0.0.3
inet 10.0.0.3/24 scope global secondary eth0:1
可以看到备节点lb02已经接管绑定了10.0.0.3这个VIP,这期间备节点还会发送ARP广播,让所有的客户端更新本地的ARP表,以便客户端访问接管VIP服务的节点。
此时如果再启动主服务器的keepalived服务,主服务器就会接管回VIP 10.0.0.3启动后可以观察下主备的IP漂移情况,备服务器是否释放了IP?主服务器是否又接管了IP ?
主节点启动keepalived服务后,发现很快就又接管了VIP 10.0.0.3,操作及检查步骤如下:
[root@lb01 keepalived]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@lb01 keepalived]# ip addr|egrep 10.0.0.3
inet 10.0.0.3/24 scope global secondary eth0:1
与此同时,备节点上的VIP 10.0.0.3则被释放了,如下:
[root@LVS-6 ~]# ip addr|egrep 10.0.0.3
7、 单实例主备模式keeplibed配置文件对比
可以看到,上述keepalived单实例MASTER和BACKUP节点的配置差别项,只有3项是不同的。
| Keepalived配置参数 | MASTER节点特殊参数 | BACKUP节点特殊参数 |
|---|---|---|
| router_id(唯一标识) | router_id lb01 | router_id lb02 |
| state(角色状态) | state MASTER | state BACKUP |
| priority(竞选优先级) | priority 150 | priority 100 |
五、keepalived高可用服务器的脑裂问题
5.1)什么是脑裂
由于某些原因,导致两台高可用服务器对在指定时间内,无法检测到对方的心跳消息,各自取得资源及服务的所有权,而此时的两台高可用服务器都还活着并在正常运行,这样就会导致同一个IP或服务在两端同时存在而发生冲突,最严重的是两台服务器占用同一个VIP地址,当用户写入数据时可能会分别写入到两端,这可能会导致服务器两端的数据不一致或造成数据丢失,这种情况就被成为脑裂。
5.2)导致脑裂发生的原因
一般来说,脑裂的发生,有以下几种原因
高可用服务器对之间心跳线链路发生故障,导致无法正常通信
心跳线坏了(包括断了,老化)
网卡及相关驱动坏了,IP配置及冲突问题(网卡直连)
心跳线之间连接的设备故障(网卡及交换机)
仲裁的机器出问题了(采用总裁的方案)
高可用服务器上开启了iptables防火墙阻挠了心跳信息传输
高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
其他服务配置不当等原因,如心跳方式不同,心跳广播冲突,软件bug等。
5.3) 解决脑裂的常见方法
在实际成产环境中,我们可以从以下几个方面来防止裂脑问题发生:
同时使用串行电缆和以太网电缆连接,同时用两条心跳线,这样一条线路坏了,另一个还是好的,依然能传送心跳信息。
当检测到裂脑时强行关闭一个心跳节点(这个功能需要特殊设备支持,如stonith,fence)相当于备节点接收不到心跳信息,通过单独的线路发送命令关闭主节点的电源。
做好对裂脑的监控报警(如邮件及手机短信等或值班),在问题发生时人为第一时间介入仲裁,降低损失。
5.4) 解决keepalived裂脑的常见方案
作为互联网应用服务器的高可用,特别是前端web负载均衡器的高可用,脑裂的问题对普遍业务的影响是可容忍的,如果是数据库或者存储的业务,一般出现裂脑问题就非常严重了。因此,通过增加冗余心跳线来避免脑裂问题发生,同时加强了对系统的监控。
如果开启防火墙,一定要让心跳消息通过。一般通过允许IP段的形式解决。
可以拉一条以太网网线或者串口线作为主备节点心跳线路的冗余。
开发检测程序通过监控软件检测脑裂,如zabbix检测如果主备都有VIP就报警。
比较严谨的判断,备节点出现对应VIP,并且主节点及对应服务(如果能远程连接主节点看是否有VIP就更好了)还活着,就说明发生脑裂了。
5.5)模拟keepalived脑裂场景
抓包
tcpdump -nn -c 20 -i any host 224.0.0.18
开启防火墙
[root@lb02 scripts]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface eth0 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
[root@lb02 scripts]# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface eth1 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
iptables
iptables -I INPUT -i eth0 -d 224.0.0.0/8 -p vrrp -j ACCEPT
iptables -I OUTPUT -o eth0 -d 224.0.0.0/8 -p vrrp -j ACCEPT
再次抓包查看
tcpdump -nn -c 20 -i any host 224.0.0.18
六、Nginx负载均衡配合keepalived双主模式实战
结合前面介绍的Nginx负载均衡的环境,调整好住负载均衡器lb01,备用负载均衡器lb02服务器上Nginx负载均衡环境,两台服务器的安装基础环境一模一样。
| HOSTNAME | IP | 说明 |
|---|---|---|
| lb01 | 10.0.0.5 | VIP:10.0.0.12(用于绑定A服务www.etiantian.org域名) |
| lb02 | 10.0.0.6 | VIP:10.0.0.13(用于绑定B服务bbs.etiantian.org域名) |
| web01 | 10.0.0.8 | Nginx web服务器1 |
| web02 | 10.0.0.7 | Nginx web服务器2 |
6.1)配置keepalived双主
lb01配置
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_01
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3/24 dev eth0 label eth0:1
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.4/24 dev eth0 label eth0:2
}
}
6.2)lb02配置
lb02配置
[root@lb01 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_02
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3/24 dev eth0 label eth0:1
}
}
vrrp_instance VI_2 {
state MASTER
interface eth0
virtual_router_id 52
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.4/24 dev eth0 label eth0:2
}
}
6.3)Nginx负载均衡
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
upstream server_pools {
server 10.0.0.7;
server 10.0.0.8;
server 10.0.0.9;
}
server {
listen 10.0.0.3:80;
server_name www.etiantian.org;
location / {
proxy_pass http://server_pools;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
}
access_log logs/access_www.log main;
}
server {
listen 10.0.0.4:80;
server_name blog.etiantian.org;
location / {
proxy_pass http://server_pools;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
}
access_log logs/access_blog.log main;
}
}
6.4)重启nginx和keepalived
systemctl restart keepalived
systemctl restart nginx
6.5)配置windows解析
10.0.0.3 www.etiantian.org
10.0.0.4 blog.etiantian.org
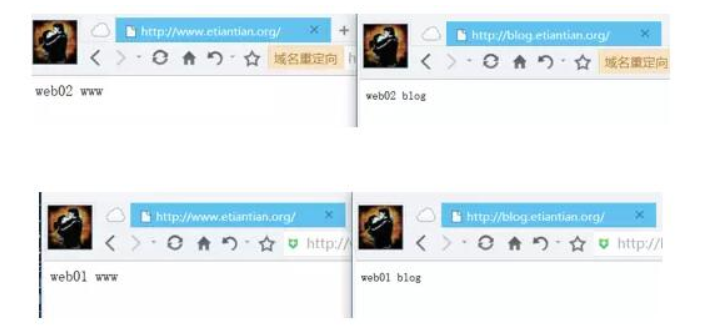
6.6)访问测试
6.7)模拟keepalived故障
此时停掉lb01服务器或停止keepalived服务器,观察结果是否正常,
然后观察lb02备点是否接管了VIP 10.0.0.3。
6.8)恢复lb01的keepalived服务
查看是否恢复正常。
七、开发监控keepalived脑裂的脚本
检测思路,VIP什么时候、什么条件才会飘走
由于某些原因,导致两台 keepalived 高可用服务器在指定时间内,无法检测到对方的心跳消息,各自取得资源及服务的所有权,而此时的两台高可用服务器又都还活着。
服务器网线松动等网络故障
服务器硬件故障发生损坏现象而崩溃
主备都开启 firewalld 防火墙
Nginx 服务死掉等
7.1)lb01检查web脚本
#!/bin/bash
nginxpid=$(ps -C nginx --no-header|wc -l)
#1.判断 Nginx 是否存活,如果不存活则尝试启动 Nginx
if [ $nginxpid -eq 0 ];then
systemctl start nginx
sleep 3
#2.等待 3 秒后再次获取一次 Nginx 状态
nginxpid=$(ps -C nginx --no-header|wc -l)
#3.再次进行判断, 如 Nginx 还不存活则停止 Keepalived,让地址进行漂移,并退出脚本
if [ $nginxpid -eq 0 ];then
systemctl stop keepalived
fi
fi
keepalived配置:
global_defs {
router_id lb01
}
vrrp_script check_web {
script "/server/scripts/check_web.sh"
interval 5
weight 50
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth1
virtual_router_id 55
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.16.1.4
}
#2.调用并运行该脚本
track_script {
check_web
}
}
7.2)lb02脚本
检查VIP脚本
global_defs {
router_id lb01
}
vrrp_script check_web {
script "/server/scripts/check_web.sh"
interval 5
weight 50
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth1
virtual_router_id 55
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.16.1.4
}
#2.调用并运行该脚本
track_script {
check_web
}
}
检查web脚本
[root@lb02 /server/scripts]# cat check_brain.sh
#!/bin/bash
lb01_vip=10.0.1.3
lb01_nginx=$(curl -x 10.0.1.5:80 -I -s -w "%{http_code}\n" -o /dev/null blog.oldzhang.com)
#ping -c 1 -W 1 ${lb01_ip} &>/dev/null
#如果lb01的IP能ping通,但是我自己也存在VIP,我就认为发生裂脑了,我就把自己的keep干掉
if [ ${lb01_nginx} -eq 200 -a `ip add|grep "$lb01_vip"|wc -l` -eq 1 ];then
echo "ha is bad" >> /tmp/check.txt
systemctl stop keepalived
else
echo "ha is ok" >> /tmp/check.txt
fi
检查配置结果,查看是否有虚拟IP10.0.0.4
#lb01存在vip地址
[root@lb01 ~]# ip addr | grep 10.0.0.4
inet 10.0.0.4/32 scope global eth0
#停止lb01上的keepalived,检测vip已不存在
[root@lb01 ~]# systemctl stop keepalived
[root@lb01 ~]# ip addr | grep 10.0.0.4
keepalived配置
global_defs {
router_id lb02
}
vrrp_script check_web {
script "/server/scripts/check_web.sh"
interval 5
weight 50
}
vrrp_script check_brain {
script "/server/scripts/check_split_brain.sh"
interval 5
weight 50
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
vrrp_instance VI_2 {
state MASTER
interface eth1
virtual_router_id 55
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.16.1.4
}
#2.调用并运行该脚本
track_script {
check_web
check_brain
}
}

















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









