



 本文记录了ELK日志系统出现的问题及其解决过程。通过对网络延时、内存分配等因素的排查,最终确定问题源于Elasticsearch内存不足,并通过调整JVM配置成功解决了问题。
本文记录了ELK日志系统出现的问题及其解决过程。通过对网络延时、内存分配等因素的排查,最终确定问题源于Elasticsearch内存不足,并通过调整JVM配置成功解决了问题。
etc在日志系统搭建起来后大半年一直没有出现大的问题,在上个月的某段时间,我慢慢发现有这个问题的存在了,首先是自己遇到过,后面也有人反应这个问题。于是就开始对这个问题进行分析:

1.因为服务器是放在国外的(新加坡的),所以考虑到是不是网络延时较大导致的,我通过新加坡的代理进行访问还是会出现这个问题。我到新加坡代理的延迟不高,新加坡代理到ELK主机的延迟也不高。最后排除是网络问题导致的,但是后期还是会对ELK主机在香港进行代理下,加快访问速度。
2.考虑到是不是服务器进程较多,内存不足,IO读写阻塞。首先说下我们服务器的配置——4G运行内存,2CPU ,硬盘大小我不记得了(好像是100GB)。我们在这个主机上面搭建了
ELK的logstash +elasticsearch +kibana +nginx ,以及zabbix agent,file2ban等。我通过top查看CPU负载不高,很正常,IO也正常,但是我之前给elasticsearch 的JVM配置中只给了1G内存,因为我前期考虑到如果elasticsearch 中占有了太多内存,那么其他服务logstash或者是kibana容易由于内存不足进程被杀死。我觉得可能是这个问题导致的。elasticsearch 需要的内存不足。后面我将配置改为elasticsearch 的JVM配置为2G内存,发现这个问题消失了。
最后总结下:如果ELK出现这种问题的话我觉得有两种解决方法:
1,如果机器的内存还是毕竟充足的话,那么就给elasticsearch多一点内存,配置文件/etc/elasticsearch/jvm.options
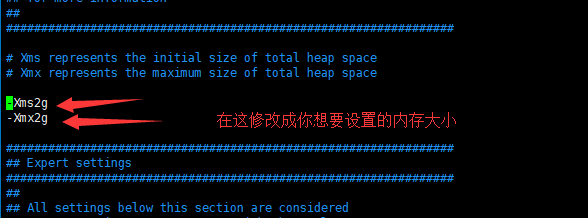
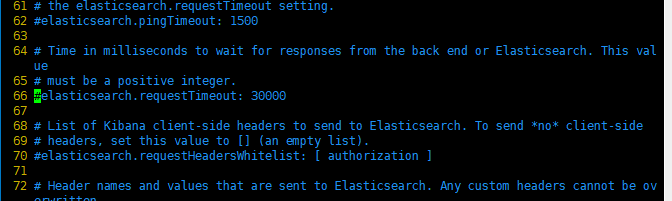
2,如果机器的内存不是那么的充足的话,我们可以改改后端弹性搜索的阈值。修改配置文件/etc/kibana/kibana.yml的第66行,将#去掉,然后将30000毫秒(也就是30s)
更改成40000(40秒),这个根据实际情况进行修改。
以上就是关于这个问题的解决,在此记录下,便于以后查询。

















 2434
2434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









