






 本文介绍了自组织映射(SOM)神经网络的工作原理及其学习过程。SOM是一种无监督学习算法,通过竞争学习的方式实现高维数据到低维空间的映射。文章详细讲解了SOM的学习规则、权重更新策略以及收敛条件。
本文介绍了自组织映射(SOM)神经网络的工作原理及其学习过程。SOM是一种无监督学习算法,通过竞争学习的方式实现高维数据到低维空间的映射。文章详细讲解了SOM的学习规则、权重更新策略以及收敛条件。
网络的输出神经元之间相互竞争,同一时刻只有一个神经元获胜。
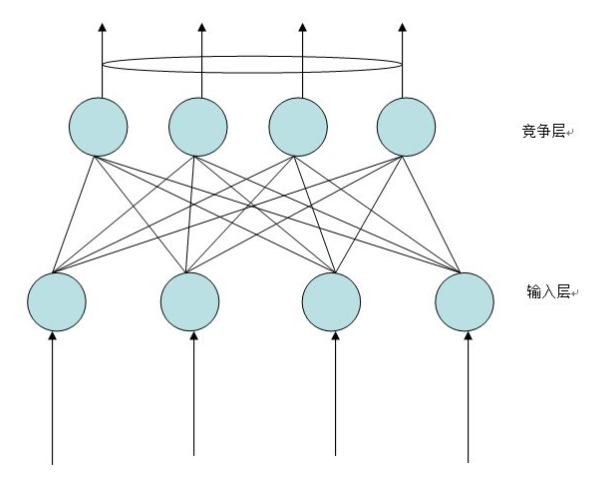
二、学习规则
竞争神经网络的学习规则是由内星规则发展而来的Kohonen学习规则。
4.SOM学习算法
- 设定变量:X=[x1,x2,x3,…,xm]为输入样本,每个样本为m维向量。ωi(k)=[ωi1(k), ω i2(k),…,ωin(k)]为第i个输入节点与输出神经元之间的权值向量
- 初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X’ = x/||x||
ω’i(k)= ωi(k)/||ωi(k)||
||x||和||ωi(k)||分别为输入向量和权值向量的欧几里得范数 - 将样本输入网络:样本与权值向量做内积,内积值最大的输出神经元赢得竞争,记为获胜神经元
- 更新权值:对获胜的神经元拓扑邻域内的神经元采用内星规则进行更新
ω(k+1)= ω(k)+ η(x- ω(k)) - 更新学习速率η及拓扑邻域,并对学习后的权值重新归一化
- 判断是否收敛。如果中心改变很小或达到预设的迭代次数,结束算法

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









