






 本文介绍了如何使用Python的urllib库获取电影天堂网站的主页源码,并深入探讨了urllib.request模块的功能,包括发送GET和POST请求、处理HTTP响应、自定义请求头以及管理cookie。
本文介绍了如何使用Python的urllib库获取电影天堂网站的主页源码,并深入探讨了urllib.request模块的功能,包括发送GET和POST请求、处理HTTP响应、自定义请求头以及管理cookie。
随着网络的快速发展,万维网成为了大量信息的载体,如何有效地获取那些对我们而言有用的信息呢?一种可行的工具就是网络爬虫。
可以把万维网想象成一张“蜘蛛网”,
我们日常访问的京东,百度,土豆,电影天堂等等网站都在这上面,网络爬虫就像一只蜘蛛,按照我们指定的规则在这张奇大无比的“蜘蛛网”上抓取信息。
官方点的解释就是:
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
举个例子来说,有一天,当你看到: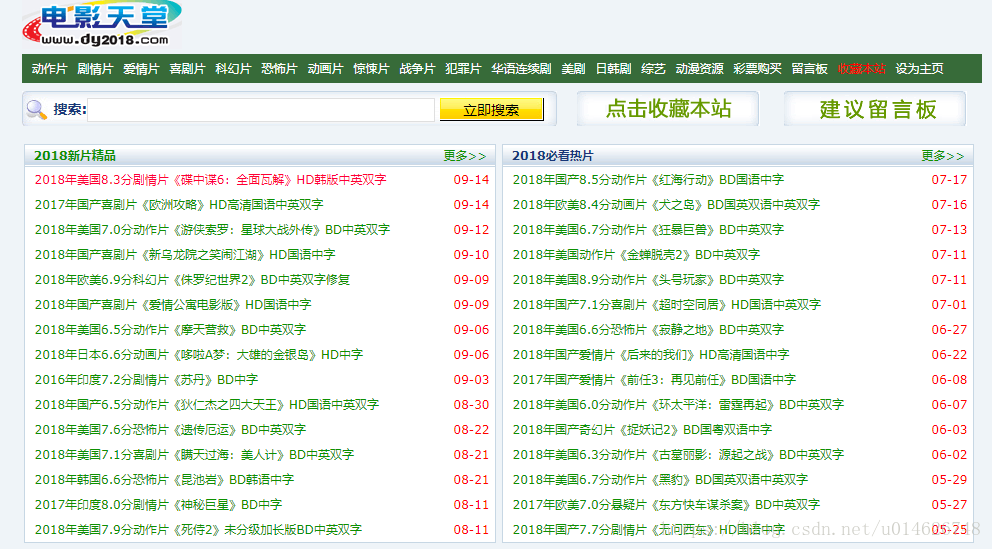
觉得好多电影都不错,于是决定全都下载下来。仔细一看才发现,竟然有三十部,而每部电影都要点击进入,查看下载地址,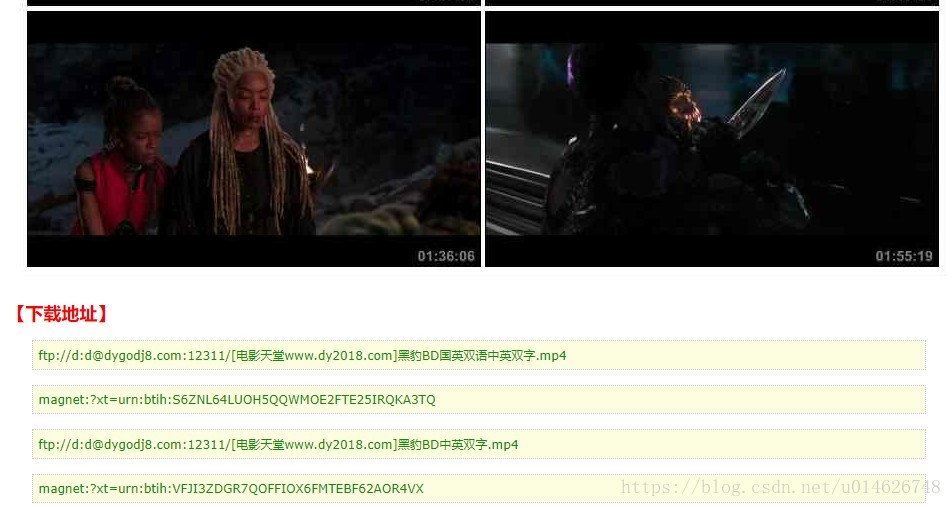
然后就是复制地址进行下载……如此重复三十遍。
很麻烦呀!有没有简单的方法呀?当然有,用网络爬虫就行啦,我们可以让爬虫提取每部电影的下载地址(这就是我们当前指定的规则),然后自己打开迅雷(个人喜好)下载……
那么,具体怎么做呢?不着急,让我们先学点基础知识。
如果对以下部分内容不太清楚的话,可以先看看网络爬虫(一)Web及网络基础。
urllib.request
urllib.request 模块提供了很多可以打开URL并从中获取数据的函数和类。这个模块最常见的用途就是通过HTTP从Web服务器获取数据。如下所示:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
source = response.read()
print(source)运行一下,可以看到:
输出的内容是什么呢?这就是网页的源码呀!我们可以访问百度首页,单击鼠标右键,
查看源代码,

每个网页都是由类似的代码构成的,如果你对这些源码内容一头雾水的话,建议稍微看看(不必过多纠结,有些基本概念即可):
当然,在与实际的服务器交互的时候情况会复杂得多。比如,你可能需要考虑代理服务器、验证、cookie、用户代理、动态加载等其他问题。下面我们就详细了解一下urllib.request 模块的一些内容。
urlopen()函数和请求
最简单明了的请求方式就是使用urlopen() 函数,它的定义如下:
urlopen(url[, data][, timeout])该函数的作用是:打开URL url 并返回类文件对象,可使用该对象读取返回的数据。简而言之,url 可以是包含URL的字符串,也可以是Request 类实例。data 是URL编码的字符串,包含要上传到服务器的表单数据。如果提供了data 那么实际上使用的就是POST 方法,而不是GET (默认值)。通常是使用urllib.parse.urlencode() 之类的函数创建数据。timeout 是可选的超时期(以秒为单位),内部存在阻塞操作时使用。
urlopen() 返回的类文件对象response 支持以下方法:
方法|描述
----|----response.read([nbytes])|以字节字符串形式读取nbytes个数据response.readline()|以字节字符串形式读取单行文本response.readlines()|读取所有行并返回列表response.fileno()|返回整数文件描述符response.close()|关闭连接response.info()|返回映射对象,该对象带有与URL关联的元信息。对HTTP来说,返回的服务器响应包含HTTP报头。对于FTP来说,返回的报头包含‘content-length’。对于本地文件来说,返回的报头包含‘content-length’和‘content-type’字段response.getcode()|返回整数形式的HTTP响应代码,例如,成功时返回200,未找到文件时返回404response.geturl()|查看返回数据的实际URL,可能有重定向问题
我们可以在之前例子的基础上试试看,比如:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.info())
print('*'*25)
print(response.getcode())
print('*'*25)
print(response.geturl())
print('*'*25)
print(response.fileno())
print('*'*25)
print(response.read(150))
print('*'*25)结果如下所示: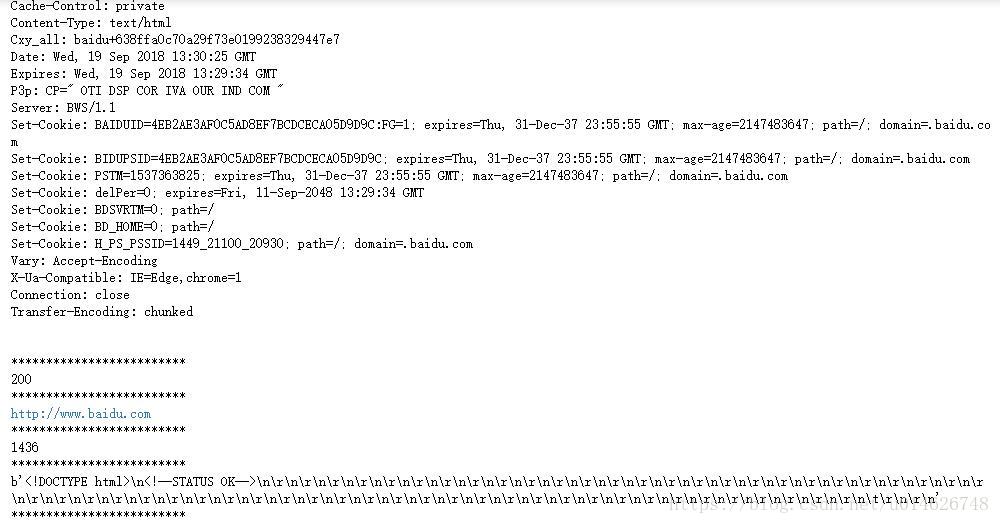
需要注意的是,类文件对象response 以二进制模式操作。如果需要以文本形式处理响应数据,则要使用codecs或类似方式解码数据。
对于一些简单的请求来说,使用urlopen() 函数即可。但如果需要执行更加复杂的操作,如修改HTTP请求报头,就可创建Request 实例。
Request(url[, data][, headers][, origin_req_host][, unverifiable])新建Request 实例。url 指定URL(比如http://httpbin.org/post)。data 是URL编码的数据,要通过HTTP请求传到服务器。提供该参数时,它将HTTP请求类型由GET 改为 POST 。headers 是一个字典,包含了可表示HTTP报头内容的键值映射。origin_req_host 设为事务的请求主机,通常是发出请求的主机名称。如果请求的是无法验证的URL,则unverifiable 设为True。无法验证的URL的非正式定义是:不是用户直接输入的URL,如加载图像的页面中嵌入的URL。unverifiable的默认值是False。
举个例子:
from urllib.request import Request
from urllib.parse import urlencode
import urllib.request
post_data = {
'name':'Viljw',
'language':'Python',
'favorite':'Cat'
}
header = {
'name':'Viliw',
'language':'Python'
}
request = Request('http://httpbin.org/post',data=urlencode(post_data).encode('utf-8'),headers=header)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))结果如下所示:
Request 的实例request 具有以下方法:
request.add_header(key,val)向请求添加报头信息。key 是报头名称,val 是报头值。两个参数的值都是字符串。
更多方法及属性如下所示:
request.data # 返回请求的数据
request.get_full_url() # 返回请求的完整URL
request.get_method() # 返回HTTP方法
request.selector # 返回URL的选择器部分(如'/index.html')
request.get_type() # 返回URL类型(如'http')
request.has_header(header) # 如果请求具有报头header,则返回True
request.set_proxy(host,type) # 准备请求连接代理服务器。这将使用host替换原来的主机,使用type替换原来的请求类型在之前的例子中,可以看到报头User-Agent 的值为Python-urllib/3.6 ,我们使用Request 对象更改urlopen() 使用的User-Agent 报头:
import urllib.request
from urllib.request import Request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61'
}
request = Request('http://httpbin.org/get',headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))输出结果如下:
自定义opener
基本的urlopen() 函数不支持验证、cookie或者其他高级HTTP功能。要支持这些功能,必须使用build_opener() 函数创建自己的自定义opener 对象:
build_opener([handler, ...])构建用于打开URL的自定义opener 对象。参数handler 是特殊处理程序对象的实例。这些处理程序的目的是向得到的opener 对象添加各种功能。下表列出了一些可用的处理程序对象。
| 处理程序 | 描述 |
|---|---|
| CacheFTPHandler | 具有持久FTP连接的FTP处理程序 |
| FileHandler | 打开本地文件 |
| FTPHandler | 通过FTP打开URL |
| HTTPBasicAuthHandler | 基本的HTTP验证处理 |
| HTTPCookieProcessor | 处理HTTP cookie |
| HTTPDefaultErrorHandler | 通过引发HTTPError异常来处理HTTP错误 |
| HTTPDigestAuthHandler | HTTP摘要验证处理 |
| HTTPHandler | 通过HTTP打开URL |
| HTTPRedirectHandler | 处理HTTP重定向 |
| HTTPSHandler | 通过HTTPS打开URL |
| ProxyHandler | 通过代理重定向请求 |
| ProxyDigestAuthHandler | 摘要代理验证 |
| ProxyBasicAuthHandler | 基本代理验证 |
| UnknownHandler | 处理所有未知URL的处理程序 |
build_opener() 返回的对象具有open(url[, data][, timeout]) 方法,作用是根据各种处理程序提供的规则打开URL。open() 的参数与传递给urlopen() 函数的参数相同。
install_opener(opener)安装不同的opener 对象作为urlopen() 使用的全局URL opener。opener 通常是build_opener() 创建的opener 对象。
HTTP Cookie
如果要管理HTTP Cookie,需要创建添加了HTTPCookieProcessor 处理程序的opener 对象。例如:
from urllib.request import HTTPCookieProcessor
from urllib.request import build_opener
cookiehandler = HTTPCookieProcessor()
opener = build_opener(cookiehandler)
response = opener.open('http://www.baidu.com')默认情况下,HTTPCookieProcessor 使用http.cookiejar模块中的CookieJar 对象。将不同类型的CookieJar 对象作为HTTPCookieProcessor 的参数提供,可以支持不同类型的cookie处理方法。例如:
from urllib.request import HTTPCookieProcessor
from urllib.request import build_opener
from http.cookiejar import MozillaCookieJar
cookie = MozillaCookieJar('cookies.txt')
cookiehandler = HTTPCookieProcessor()
opener = build_opener(cookiehandler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)代理
如果请求需要通过代理重定向请求,可创建ProxyHandler 实例。
ProxyHandler([proxies])参数proxies 是一个字典,将协议名称(如,http 、ftp 等)映射到相应代理服务器的URL。
举个例子:
from urllib.request import ProxyHandler
from urllib.request import build_opener
proxy = ProxyHandler({'http':'http://127.0.0.1:1080'})
opener = build_opener(proxy)
response = opener.open('http://www.google.com')urllib.parse
urllib.parse 模块用于解析URL字符串,如http://www.baidu.com ,也可用于对组成URL的数据进行解码和编码。
更多内容可查看:urllib.parse
urllib.error
urllib.error 模块定义了urllib.request 常抛出的异常。
ContentTooShort
在下载数据量小于预期的数据量(由Content-Length 报头定义)时引发。
HTTPError
在HTTP协议发生问题时引发。该错误可以用来提醒需要验证之类的事件。该异常还可以用作文件对象,以读取服务器返回的与错误有关的数据。它是URLError 的子类。
URIError
处理程序检测到问题时引发的错误。它是OSError 的子类。异常实例的reason属性包含相关问题的更多信息。
urllib.robotparser
urllib.robotparser 模块用于获取和解析用来指示Web爬虫的robots.txt 文件的内容,如需更多的使用信息,请查看:urllib.robotparser
获取电影天堂主页源码
终于回到我们一开始的话题,怎么获取电影天堂主页源码呢?相信有了前面的介绍,可以开始尝试一下啦!
import urllib.request
url = 'https://www.dy2018.com'
response = urllib.request.urlopen(url)
print(response.read())运行结果如下:
如果以文本形式显示,别忘记我们需要对其进行解码,以什么编码方式进行解码呢?我们可以先来到电影天堂,单击鼠标右键: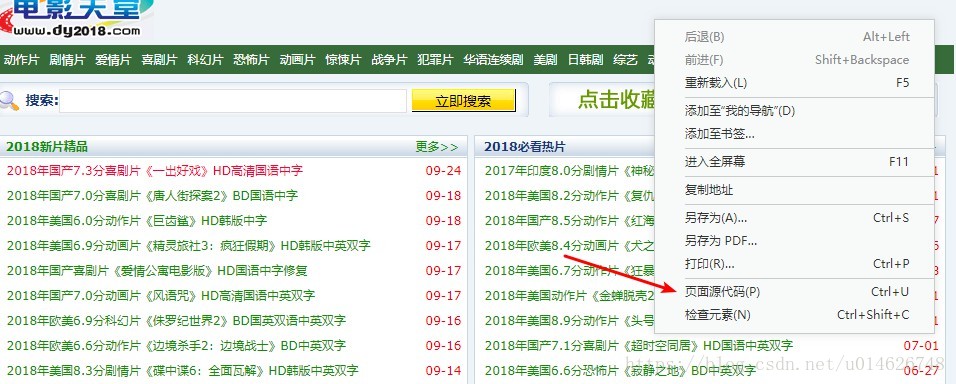
可以找到如下内容: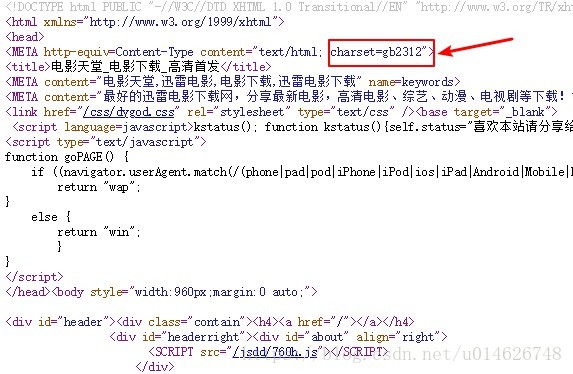
这就是我们一直想要的编码方式(当然,如果你也可以尝试一下chardet模块),代码自然可以对应改一下:
import urllib.request
url = 'https://www.dy2018.com'
response = urllib.request.urlopen(url)
print(response.read().decode('gb2312'))运行结果如下: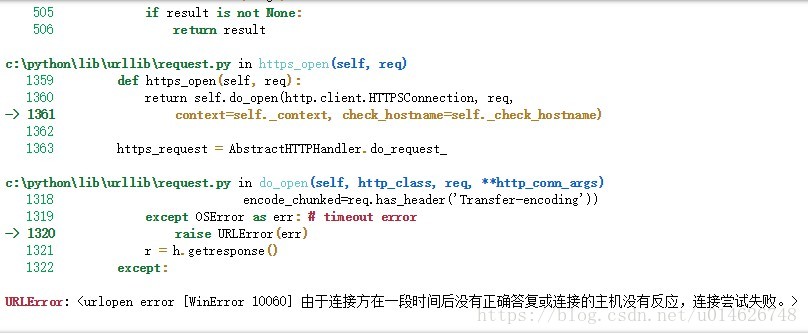
竟然报错了,怎么回事?原因是网站有反爬措施,此时我们可以尝试如下处理:
import urllib.request
from urllib.request import Request
url = 'https://www.dy2018.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61'
}
request = Request(url,headers=headers)
response = urllib.request.urlopen(request)
print(response.read().decode('gb2312'))运行一下,结果如下:
很好,主页的信息正常获取到了,那怎么进入每部电影的主页并获取到下载地址呢?卖个关子,下次再说吧。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









