



相关分析
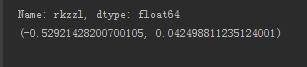
import statsmodels.api as sm import pandas as pd import numpy as np from patsy.highlevel import dmatrices # 这个是线性回归的 from common.util.my_sqlalchemy import sqlalchemy_engine import math from scipy.stats.stats import pearsonr sql = "select Q1R3, Q1R5, Q1R6, Q1R7 from db2017091115412316222027656281_1;" df = pd.read_sql(sql, sqlalchemy_engine) df_dropna = df.dropna() result = pearsonr(df_dropna['Q1R3'], df_dropna['Q1R5']) print(result)
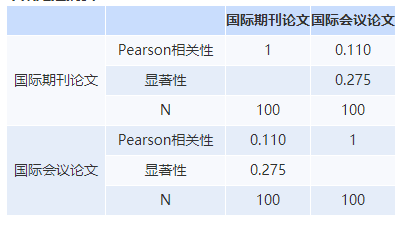
报告展示:
相关性检验显示,rkzzl与gmsr显著负相关(Pearson’r=-0.529,p<0.05)。
若p>0.5则写:rkzzl与gmsr无显著相关关系(Pearson’r=-0.529,p>0.05)。
|
|
Pearson’r |
p |
|
|
-0.5292 |
0.0425 |
| A | B | C | |
| A | AA | AB | AC |
| B | AB | BB | BC |
| C | AC | CB | CC |
二期
经过数据分析部指导,系数做了算法优化
def CorrelationAnalysisDetail(UserID,ProjID,QuesID,VariableNames,CasesCondition,VariableIDs,Corr): select_id_ret = select_ques_datatableid_optionid() whether_datatableid = select_id_ret.SelectDatatableIDTwoSql(UserID, ProjID, QuesID, VariableIDs[0]) select_id_ret.close() if whether_datatableid: DataTableID = whether_datatableid[0]["DataTableID"] DatabaseName = whether_datatableid[0]["DatabaseName"] TableName = JoinTableName(whether_datatableid) df_dropna = CorrelationAnalysisModel(VariableNames,TableName, DatabaseName, CasesCondition) # spearman 斯皮尔曼系数 # kendall 肯德尔系数 # pearson 皮尔逊系数 # return pearsonr(df_dropna[xVariable], df_dropna[yVariable]) return df_dropna.corr(method=Corr).to_dict()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









