






- perform both classification and regression tasks and even mulioutput tasks
- how to train, visualize, and make predictions with Decision Tree
- CART training algorithm
- limitation of Decision Tree
Training and Visualizing a Decision Tree¶
In [2]:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, 2:]
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)
Out[2]:
In [9]:
from sklearn.tree import export_graphviz
import os
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "decision_trees"
def image_path(fig_id):
return os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id)
export_graphviz(
tree_clf,
out_file=image_path('iris_tree.dot'),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)

Making Predictions¶
- $$ Gini\ impurity:\ G_i=1-\sum_{k=1}^{n}p_{i,k}^{\ \ \ \ \ 2} $$
- $p_{i,k}$是第i个实例分到第k类的比例
- white box
Estimating Class Probabilities¶
输出的时所属的非叶子节点的实例的比例
In [10]:
tree_clf.predict_proba([[5, 1.5]])
Out[10]:
In [11]:
tree_clf.predict([[5,1.5]])
Out[11]:
The CART Training Algorithm¶
- sklearn use Classification And Regression Tree(CART) to train Decision Tree
- splite the train set in two purest subsets:$$ J(k,t_k) = \frac{m_{left}}{m} G_{left} + \frac{m_{right}}{m} G_{right} \\ where \left\{\begin{matrix} G_{left/right}\ measures\ the\ impurity\ of\ the\ left/right\ subset\\ m_{{left}/{right}}\ is\ the\ number\ of\ instances\ in\ the\ left/right\ subsets. \end{matrix}\right. $$
- reasonably good solution
Computational Complexity¶
- $O(log_2(m))$ for prediction and $O(n \times log_2{m})$ for train
Gini Impurity or Entropy¶
- entropy origined thermodynamics to measure molecular disorder
- in ml, it is frequently used as an impurity measure.
- $$ H_i=-\sum_{k=1,p_{i,k}\neq 0}^{n}p_{i,k}log(p_{i,k}) $$
- Gini is fast, Gini and Entropy lead to similar tree
- when they differ, Gini impurity tend to isolate the most frequent class in its own bench of tree, while entropy trens to produce slightly more balanced trees
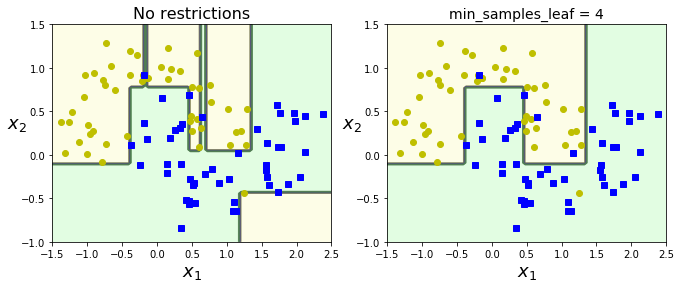
Regularization Hyperparameters¶
- nonhyperparametric model:the number of parameters is not determined prior to training
- most likely to overfitting, so need to restrict the freedom called regularization
- generally this is controlled by max_depth
- DecisionTreeClassifier class has min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_leaf_nodes, max_features
- 也可先不加限制生成决策树,再剪枝。如果统计学不显著,就剪掉
In [17]:
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np
def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap, linewidth=10)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
if plot_training:
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", label="Iris-Setosa")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y==2], X[:, 1][y==2], "g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
if legend:
plt.legend(loc="lower right", fontsize=14)
Xm, ym = make_moons(n_samples=100, noise=0.25, random_state=53)
deep_tree_clf1 = DecisionTreeClassifier(random_state=42)
deep_tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42)
deep_tree_clf1.fit(Xm, ym)
deep_tree_clf2.fit(Xm, ym)
plt.figure(figsize=(11, 4))
plt.subplot(121)
plot_decision_boundary(deep_tree_clf1, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("No restrictions", fontsize=16)
plt.subplot(122)
plot_decision_boundary(deep_tree_clf2, Xm, ym, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title("min_samples_leaf = {}".format(deep_tree_clf2.min_samples_leaf), fontsize=14)
plt.show()
Regression¶
In [18]:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
Out[18]:
In [22]:
export_graphviz(
tree_reg,
out_file=image_path('moons_tree1.dot'),
rounded=True,
filled=True
)

$$ cost\ function=J(k,t_k)=\frac{m_{left}}{m}MSE_{left}+\frac{m_{right}}{m}MSE_{right}\\ where\left\{\begin{matrix} MSE_{node}=\sum_{i \in {node}}(\widehat{y}_{node}-y^{(i)})^2 \\ \widehat{y}_{node}=\frac{1}{m_{node}}\sum{i \in {node}}y^{(i)} \end{matrix}\right. $$
Instability¶
- Decision Tree love orthogonal decision boundaries which make them sensitive to training set rotation; One way to limit this problem is to use PCA
- they are very sensitive to small variations in training set; Random Forests can limit this instability by averaging predictions over many trees
In [ ]:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









