






转载自:https://www.cnblogs.com/klguang/p/4618526.html
报文流
- HTTP 报文是在HTTP 应用程序之间发送的数据块。这些数据块以一些文本形式的元信息(meta-information)开头,这些信息描述了报文的内容及含义,后面跟着可选的数据部分。这些报文在客户端、服务器和代理之间流动。
- HTTP 使用术语流入(inbound)和流出(outbound)来描述事务处理(transaction)的方向
- 不管是请求报文还是响应报文,所有报文都会向下游(downstream)流动
报文组成

- 起始行
报文的第一行就是起始行,在请求报文中用来说明要做些什么,在响应报文中说明出现了什么情况。
- 首部字段
起始行后面有零个或多个首部字段。每个首部字段都包含一个名字和一个值,为了便于解析,两者之间用冒号(:)来分隔。首部以一个空行结束。添加一个首部字段和添加新行一样简单。
- 主体
空行之后就是可选的报文主体了,其中包含了所有类型的数据。请求主体中包括了要发送给Web 服务器的数据;响应主体中装载了要返回给客户端的数据。起始行和首部都是文本形式且都是结构化的,而主体则不同,主体中可以包含任意的二进制数据(比如图片、视频、音轨、软件程序)。当然,主体中也可以包含文本。
MIME 类型是一种文本标记,表示一种主要的对象类型和一个特定的子类型,中间由一条斜杠来分隔。
• HTML 格式的文本文档由 text/html 类型来标记。
•普通的 ASCII 文本文档由 text/plain 类型来标记。
• JPEG 格式的图片为 image/jpeg 类型。
• GIF 格式的图片为 image/gif 类型。
• Apple 的 QuickTime 电影为 video/quicktime 类型。
•微软的 PowerPoint 演示文件为 application/vnd.ms-powerpoint 类型。
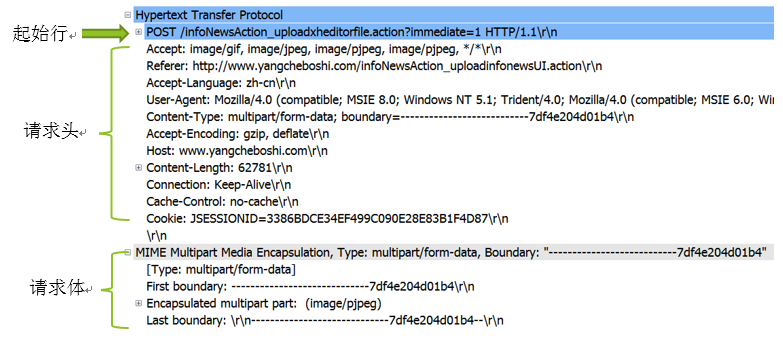
起始行
a.请求行
请求报文请求服务器对资源进行一些操作。请求报文的起始行,或称为请求行,包含了一个方法和一个请求URL,这个方法描述了服务器应该执行的操作,请求URL描述了要对哪个资源执行这个方法。请求行中还包含HTTP 的版本,用来告知服务器,客户端使用的是哪种HTTP。所有这些字段都由空格符分隔。
例如:POST /infoNewsAction_uploadxheditorfile.action?immediate=1 HTTP/1.1
b.响应行
响应报文承载了状态信息和操作产生的所有结果数据,将其返回给客户端。响应报文的起始行,或称为响应行,包含了响应报文使用的HTTP 版本、数字状态码,以及描述操作状态的文本形式的原因短语。 所有这些字段都由空格符进行分隔。
例如:HTTP/1.1 200 OK
首部
1.每个HTTP 首部都有一种简单的语法:名字后面跟着冒号(:),然后跟上可选的空格,再跟上字段值,最后是一个CRLF。(或者换行符)
常见的首部实例
|
首部实例 |
描述 |
|
Date:Tue,3Oct 1997 02:16:03 GMT |
服务器产生响应的日期 |
|
Content-length:15040 |
实体的主体部分包含了15 040 字节的数据 |
|
Content-type:image/gif |
实体的主体部分是一个GIF 图片 |
|
Accept: image/gif, image/jpeg, text/html |
客户端可以接收GIF 图片和JPEG 图片以及HTML |
2. 首部延续行
将长的首部行分为多行可以提高可读性,多出来的每行前面至少要有一个空格或制表符(tab)。
HTTP/1.0 200 OK
Content-Type: image/gif
Content-Length: 8572
Server: Test Server
Version 1.0
• 通用首部
这些是客户端和服务器都可以使用的通用首部。可以在客户端、服务器和其他应
用程序之间提供一些非常有用的通用功能。比如,Date 首部就是一个通用首部,
每一端都可以用它来说明构建报文的时间和日期:
Date: Tue, 3 Oct 1974 02:16:00 GMT
• 请求首部
从名字中就可以看出,请求首部是请求报文特有的。它们为服务器提供了一些额
外信息,比如客户端希望接收什么类型的数据。例如,下面的Accept 首部就用
来告知服务器客户端会接受与其请求相符的任意媒体类型:
Accept首部
|
首 部 |
描 述 |
|
Accept |
告诉服务器能够发送哪些媒体类型 |
|
Accept-Charset |
告诉服务器能够发送哪些字符集 |
|
Accept-Encoding |
告诉服务器能够发送哪些编码方式 |
|
Accept-Language |
告诉服务器能够发送哪些语言 |
|
TE11 |
告诉服务器可以使用哪些扩展传输编码 |
安全请求首部
|
首 部 |
描 述 |
|
Authorization |
包含了客户端提供给服务器,以便对其自身进行认证的数据 |
|
Cookie |
客户端用它向服务器传送一个令牌——它并不是真正的安全首部,但确实隐含了安全功能14 |
|
Cookie2 |
用来说明请求端支持的cookie 版本,参见11.6.7 节 |
• 响应首部
响应报文有自己的首部集,以便为客户端提供信息(比如,客户端在与哪种类型
的服务器进行交互)。例如,下列Server 首部就用来告知客户端它在与一个版
本1.0 的Tiki-Hut 服务器进行交互:
Server: Tiki-Hut/1.0
• 实体首部
实体首部指的是用于应对实体主体部分的首部。比如,可以用实体首部来说明实
体主体部分的数据类型。例如,可以通过下列Content-Type 首部告知应用程
序,数据是以iso-latin-1 字符集表示的HTML 文档:
Content-Type: text/html; charset=iso-latin-1
• 内容首部
|
首 部 |
描 述 |
|
Content-Encoding |
对主体执行的任意编码方式 |
|
Content-Length |
主体的长度或尺寸 |
|
Content-Type |
这个主体的对象类型 |
• 扩展首部
扩展首部是非标准的首部,由应用程序开发者创建,但还未添加到已批准的
HTTP 规范中去。即使不知道这些扩展首部的含义,HTTP 程序也要接受它们并对其进行转发。
方法
常见的http方法

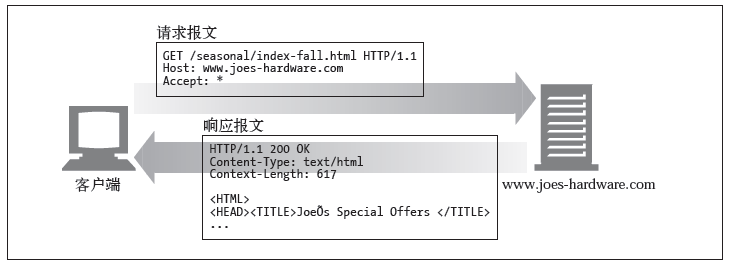
1.GET
通常用于请求服务器发送某个资源。
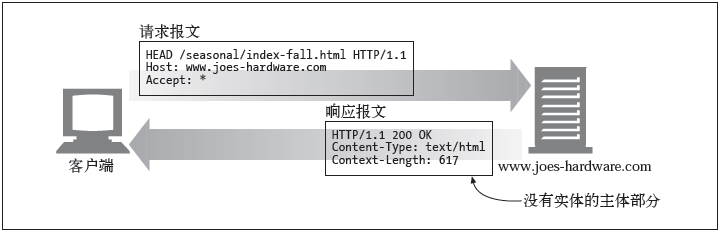
2.HEAD
HEAD 方法与GET 方法的行为很类似,但服务器在响应中只返回首部。不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。
使用HEAD,可以:在不获取资源的情况下
- 了解资源的情况(比如,判断其类型);
- 通过查看响应中的状态码,看看某个对象是否存在;
- 通过查看首部,测试资源是否被修改了。
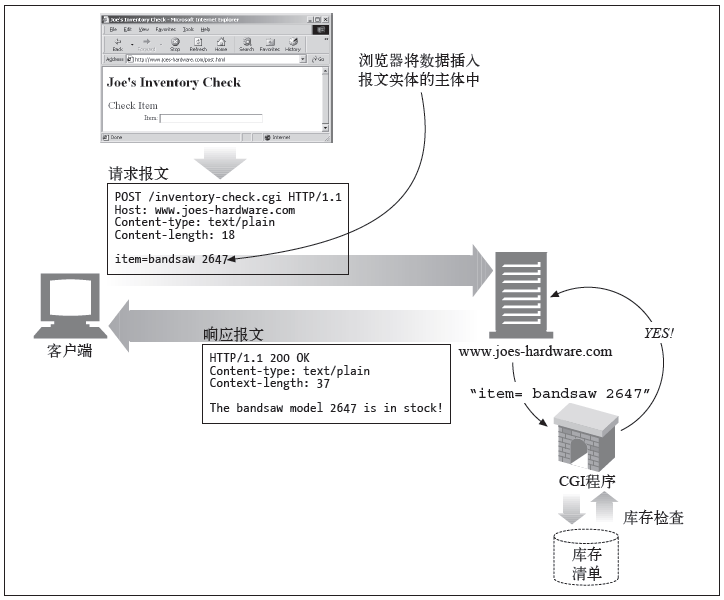
3.post
通常用于向服务器提交数据。表单提交常常用到post。

















 5057
5057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









