






要爬取的链接:
(点我试试)
要爬取的页面:
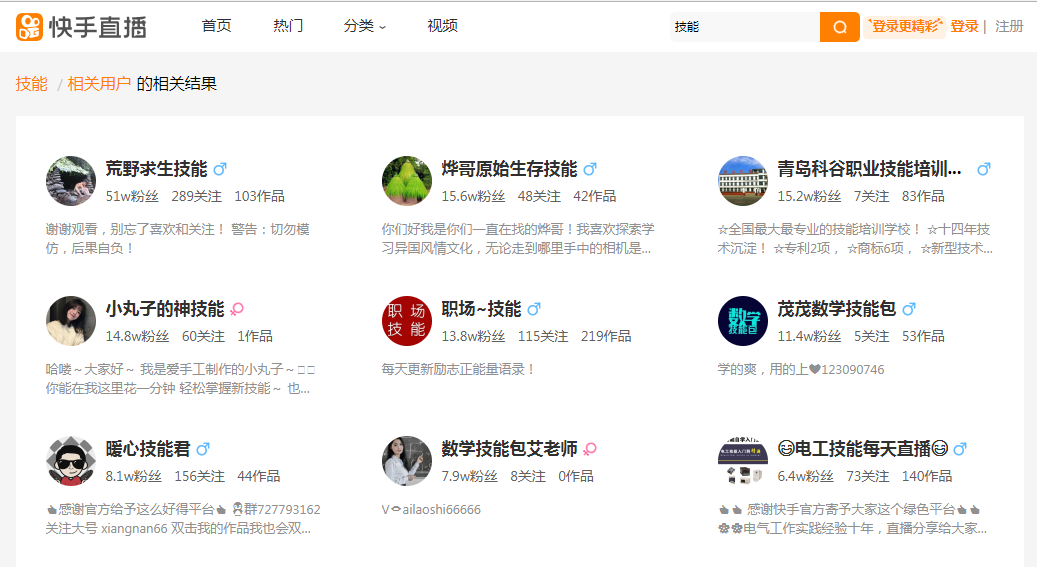
要爬取的内容:
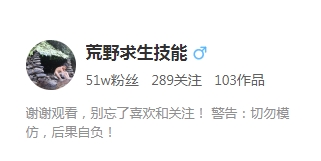
先研究下,
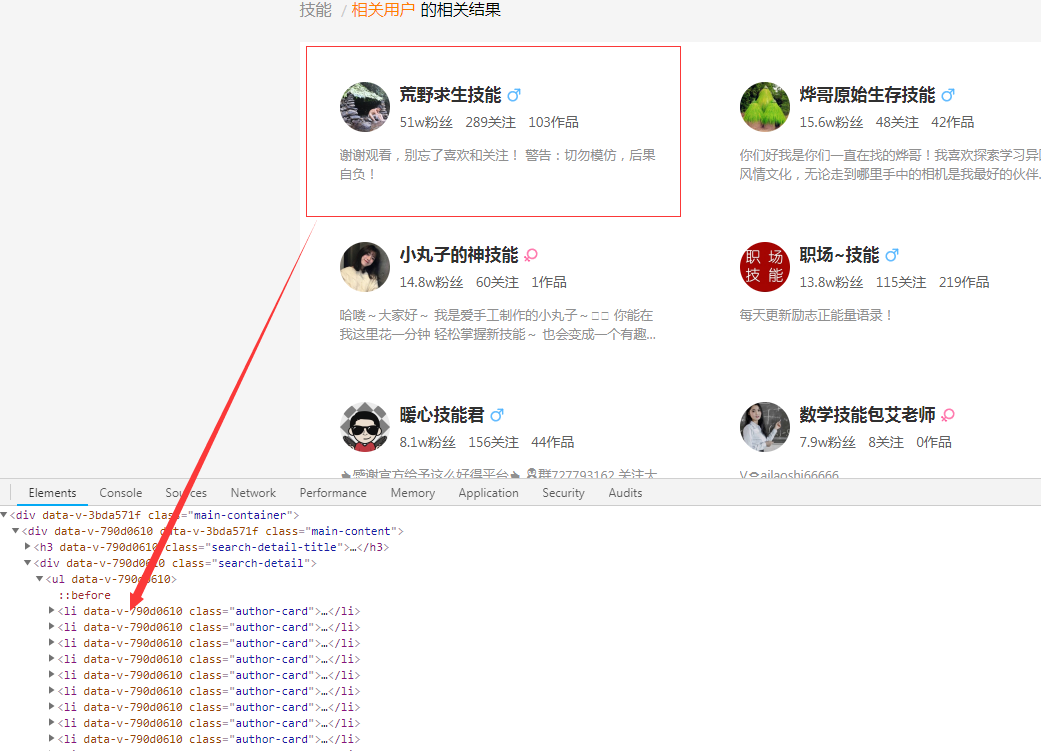
如图,每一个用户信息在一个li标签里面,靠css选择器就能很容易获取到,但是看源码却发现那些关键的数字有字体反爬。如下图:

然后看到这篇(点我试试)博客后,完成了这只小爬虫~
代码:
import requests from pyquery import PyQuery as pq from urllib.parse import urljoin import json def parsingChar(type,data): fontscn_h57yip2q = { '\\uabcf':'4', '\\uaced':'3', '\\uaedd':'8', '\\uaede':'0', '\\uafcd':'6', '\\ubdaa':'5', '\\ubdcd':'1', '\\ubfad':'9', '\\uccda':'2', '\\ucfbe':'7', } fontscn_3jqwe90k = { '\\uaacb':'4', '\\uabcd':'3', '\\uacdd':'0', '\\uaefb':'8', '\\uafbc':'6', '\\ubbca':'1', '\\ubdca':'5', '\\ubfee':'9', '\\uccac':'2', '\\ucfba':'7', } fontscn_yuh4hy4p = { '\\uaabd':'5', '\\uaadd':'0', '\\uacde':'9', '\\uadaa':'2', '\\uadac':'1', '\\uadcb':'7', '\\uaeed':'8', '\\ubebb':'3', '\\ucbdc':'6', '\\ucccf':'4', } fontscn_qw2f1m1o = { '\\uabcb':'4', '\\uaccd':'3', '\\uacda':'0', '\\uaeff':'8', '\\uafbb':'6', '\\ubdca':'1', '\\ubdcc':'5', '\\ubfef':'9', '\\uccaa':'2', '\\ucfba':'7', } fontscn_yx77i032 = { '\\uabce':'4', '\\uaccd':'6', '\\uaeda':'8', '\\uaefe':'0', '\\uafed':'3', '\\ubaaa':'5', '\\ubddd':'1', '\\ubfad':'2', '\\ubfae':'9', '\\uc44f':'7', } woff_dict = {'h57yip2q': fontscn_h57yip2q, '3jqwe90k': fontscn_3jqwe90k, 'yuh4hy4p': fontscn_yuh4hy4p, 'qw2f1m1o': fontscn_qw2f1m1o, 'yx77i032': fontscn_yx77i032} li = [] new_data = (list(map(lambda x: x.encode('unicode_escape'), data))) #这里将data转为编码byte型的数据,如b'\\ubdca' for i in new_data: if len(str(i)) > 5: num = woff_dict[type][str(i)[3:-1]] #str(i)[3:-1]这里是将比如b'\\ubdca'转为字符串\ubdca,好去字典中匹配值 li.append(num) else: li.append(str(i)[2:-1]) res = ''.join(li) return res def handling_detail(word,type): ''' :param word: 含细节的字符串 :param type: 当前页面字体类型 :return: 将数字转换成正常的后返回 ''' try: words = word.split(' ') if 'w粉丝' in words[0]: fans = words[0].replace('w粉丝', '').strip() fans = parsingChar(type, fans)+'w粉丝' else: fans = words[0].replace('粉丝', '').strip() fans = parsingChar(type, fans)+'粉丝' #转换粉丝数为正常数字 follows = words[1].strip().replace('关注','') follows = parsingChar(type,follows) # 转换关注数为正常数字 works = words[2].strip().replace('作品', '') works = parsingChar(type,works) # 转换作品数为正常数字 all = fans+follows+'关注'+works+'作品' return all except: print(word,'handling_detail error') def judge(html): ''' :param html: html源码 :return: 当前页面字体类型 ''' for i in ['h57yip2q', '3jqwe90k','yuh4hy4p', 'qw2f1m1o', 'yx77i032']: if i in html: return i def getList(key,page): ''' :param key: 搜索的关键字 :param page: 页数 :return: 用户的一些细节,用户名,用户主页url,用户画像,用户签名,用户粉丝数等等... ''' all = {} url = 'https://live.kuaishou.com/search/author?keyword='+key+'&page='+str(page) original_url = 'https://live.kuaishou.com' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} r = requests.get(url=url,headers=headers) type = judge(r.text)#判断当前页面字体类型 html = pq(r.text) lis = html('.search-detail ul .author-card').items() for li in lis: ''' 这里是用pyquery的css选择器对用户信息的获取 ''' name = li('.profile-card-user-info-intro').attr('title').strip() #用户名 detail = li('.profile-card-user-info-counts').text().strip() detail = handling_detail(detail,type)#对有字体反爬地方处理 #粉丝数作品数有反爬的部分 sign = li('.profile-card-user-info-description.notlive').text().strip() #签名 user_url = li('.profile-card-user-info a').attr('href').strip() user_url = urljoin(original_url,user_url) #主播首页url user_img = li('img').attr('src').strip() #用户画像url all[name] = {'user_url':user_url,'detail':detail,'sign':sign,'user_img':user_img} return all if __name__ == '__main__': key = '技能' for i in range(1,11): with open('kuaishou.json','a',encoding='utf-8') as f: json.dump(getList(key,i), f, ensure_ascii=False, sort_keys=True, indent=4) #json文件保存获取的内容
结果:
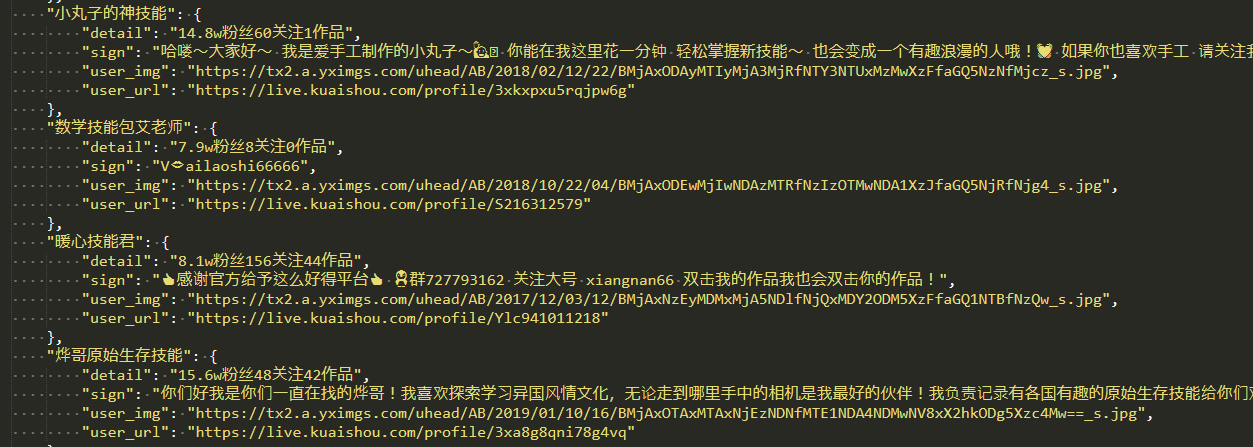

















 2242
2242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









