



使用scrapy
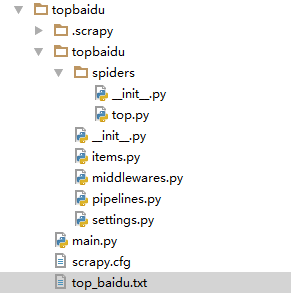
top.py 爬虫主要工作
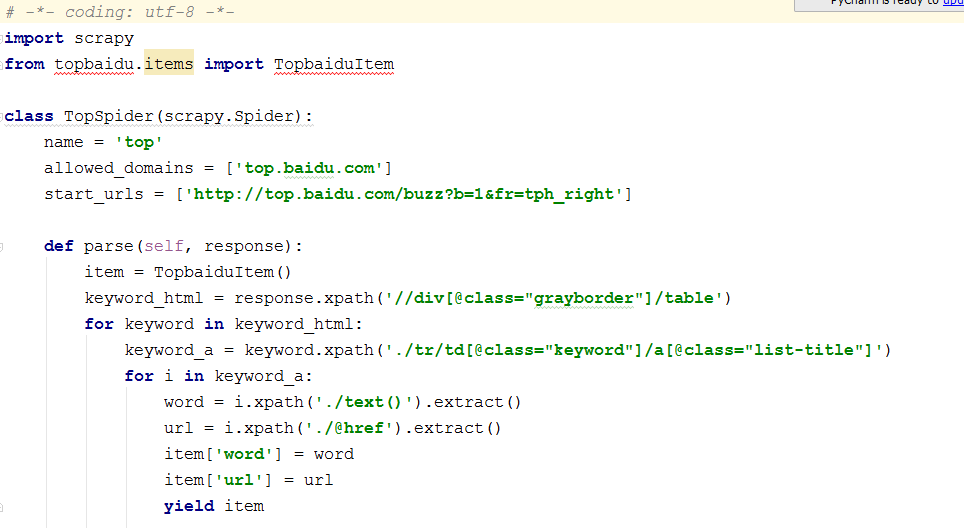
pipelines.py 数据保存
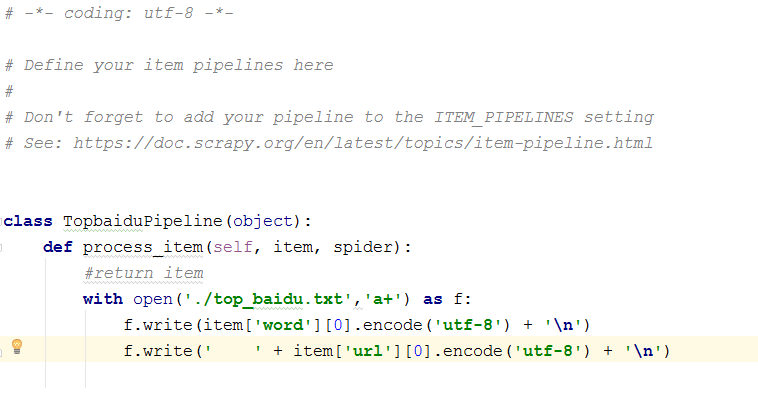
main.py 执行脚本
items.py 初始化item
 本文介绍了Scrapy爬虫框架的主要组成部分:top.py负责爬虫任务调度,pipelines.py用于数据保存,main.py是执行脚本,items.py则用于初始化item。通过这些关键文件的了解,可以深入掌握Scrapy的工作原理。
本文介绍了Scrapy爬虫框架的主要组成部分:top.py负责爬虫任务调度,pipelines.py用于数据保存,main.py是执行脚本,items.py则用于初始化item。通过这些关键文件的了解,可以深入掌握Scrapy的工作原理。
使用scrapy
top.py 爬虫主要工作
pipelines.py 数据保存
main.py 执行脚本
items.py 初始化item
转载于:https://www.cnblogs.com/wozuilang-mdzz/p/9736497.html

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1117
1117





