



 本文探讨了PolyLDA(一种处理多语言语料库的主题模型)及其基于Gibbs采样的实现方式,并将之与Mr.LDA进行了比较。Mr.LDA是一种适用于大规模数据集并能在Hadoop上运行的变分推断主题模型。
本文探讨了PolyLDA(一种处理多语言语料库的主题模型)及其基于Gibbs采样的实现方式,并将之与Mr.LDA进行了比较。Mr.LDA是一种适用于大规模数据集并能在Hadoop上运行的变分推断主题模型。
Abstract
This month , my work is mainly about Bilingual Topic model , that is PolylLDA . The base of PolyLDA are Gibbs Sampling and Variational Inference , similar as monolingual LDA . Being familiar with Gibbs Sampling , I select PolyLDA based Gibbs Sampling to deal with bilingual corpus . Attachment is the final result file where I deal with sample parallel corpus .
PolyLDA
PolyLDA is the shorthand of Polylingual LDA . It assumes that a single document has words in multiple languages , but each document has a common distribution of topics . Each topic also has different facets of languages , these topics end up being consistent due to the links across language encoded in the consistent themes present in document .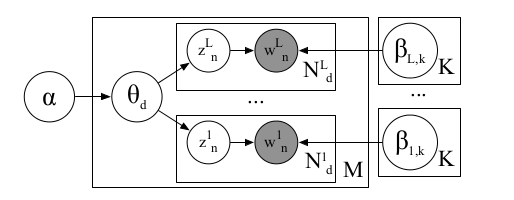
Gibbs & Variational Inference
Variational Inference :
-- Map reduce : The lda project based on Variational Inference can be executed on the Hadoop , which can deal with data with huge size effectively .Gibbs sampling :
-- Drawback : Convergence of sampler to its stationary distribution is difficult to diagnose , and sampling algorithm can be slow to converge in high dimensional models .
Thus , if we want to deal with data with huge size , variable inference is best choice for us .
Mr.LDA
Mr.LDA is used to deal with multilingual topic modeling using variational inference in MapReduce , which fits into a distributed environment well . Morever ,compared to LDA based on Gibbs Sampling , Mr.LDA is easily extensible .
Two main extensions
- Informed priors : To guide topic discovery .
- PolyLDA : To extracting from multilingual corpus .
In the package given on the github , PolyLDA is a branch of Mr.LDA , separated . The PolyLDA can run well and produce the final result , but the files of result can't be read directly . We should use some tools to decode and extract it , whose download link and directions are ignored in its README . Being out of data , the README just contains the directions of executing monolingual topic model . It is a pity that I just can run the monolingual topic model using Mr.LDA .
Howerve , with description in detail of the difference in detail between Gibbs Sampling and Variational Inference , its paper is very nice . By comparison , variational Inference is more popular than Gibbs Sampling , both in execution speed and likelihood . In view of its great idea and powerful source , I think mastering Mr.LDA is the final step of researching topic model .
Further work
- Mr.LDA
- Hadoop : Learning it to read the codes of Mr.LDA
- Tf-idf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









