






 本文深入探讨了Python中字符串编码的工作原理,包括Python 2与Python 3在处理编码方面的差异,以及如何正确处理不同编码格式的文件。
本文深入探讨了Python中字符串编码的工作原理,包括Python 2与Python 3在处理编码方面的差异,以及如何正确处理不同编码格式的文件。
前戏
编码 Zh EN
- Ascii 1B
- GB2312 2B 1B
- GBK 2B 1B
- GB18030 2B 1B
- UTF-8 3B 1B
- UTF-16 4B 4B
Python2
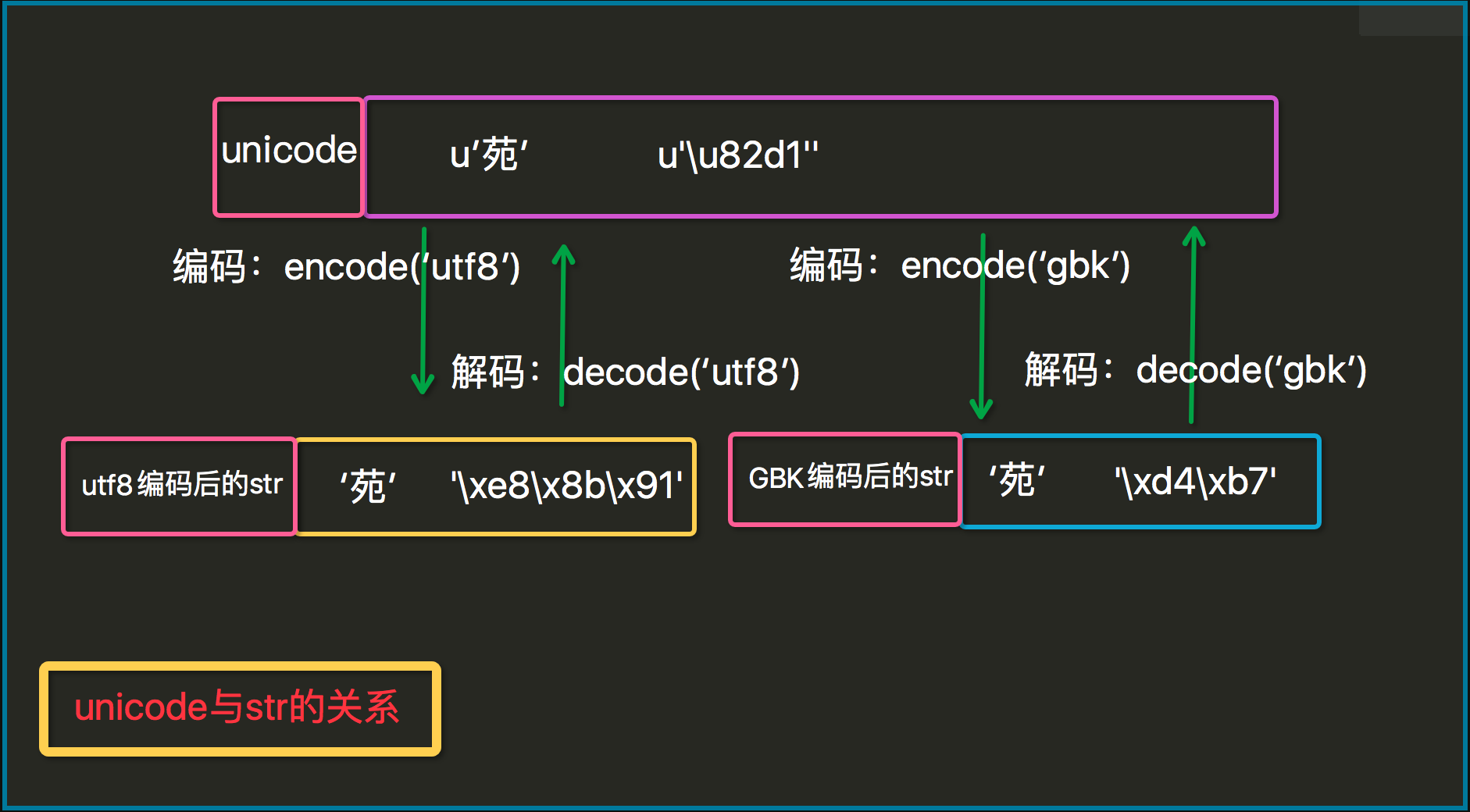
str和Unicode
str=bytes
这里的unicode可以看成真正意义上的字符串,而str存储的是经过编码后的字节串


1 print(u'a'+'b') 2 #ab 3 print(u'a'+'哈') 4 #Traceback (most recent call last): 5 # File "<stdin>", line 1, in <module> 6 #UnicodeDecodeError: 'ascii' codec can't decode byte 0xb9 in position 0: #ordinal not in range(128)
py2这里会把bytes类型自动转换为unicode进行拼接,这里是隐性的转换,但是不会和ascii之外的字符进行拼接转换,比如中文。
encode和decode转换
Python3
Bytes和Unicode
py3的字符串str保存的unicode类型,bytes存储的是byte字节串
py3的最大特点就是严格区分了文本和字节串,文本就是unicode,str类型表示,二进制数据由bytes类型表示。
py3不能将unicode和别的ascii进行拼接,他不会隐性的帮你转换。
encode和decode转换
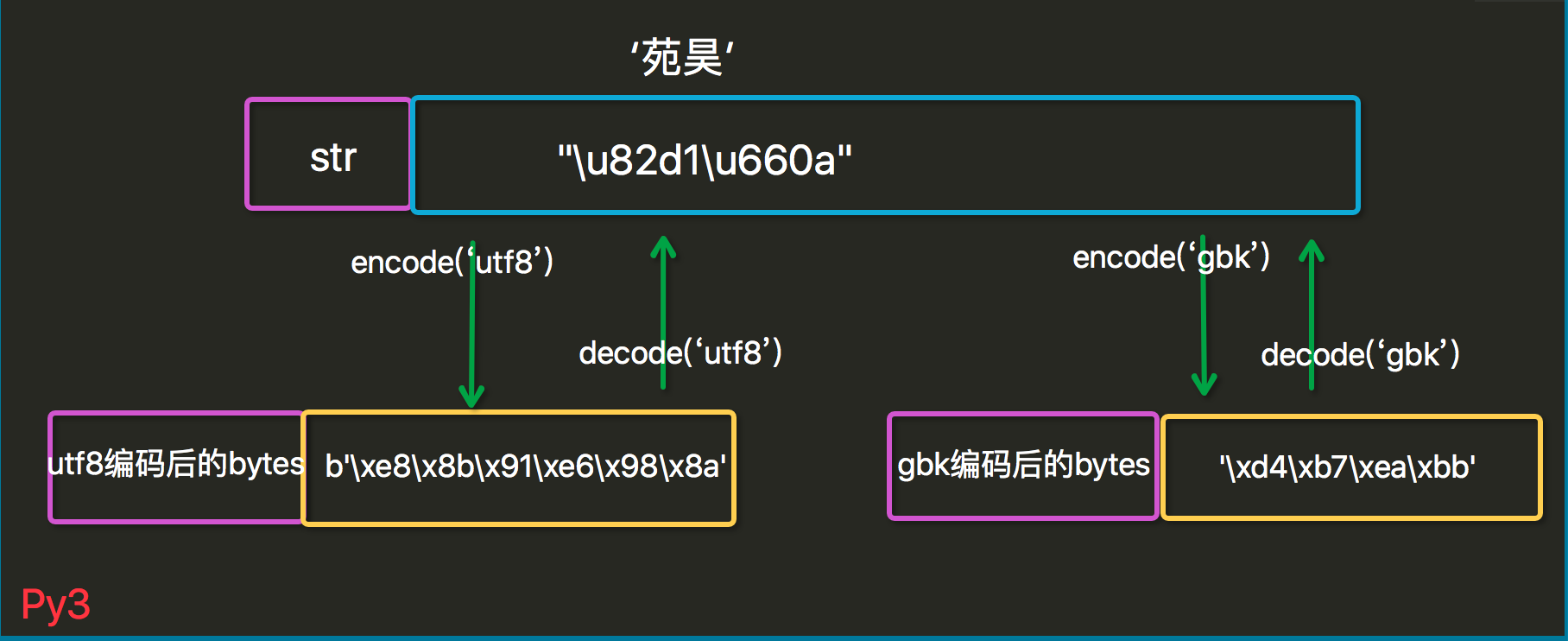
str-->bytes 使用encode,编码成什么形式的bytes(也就是加密成哪种语言的bytes)
bytes--> str 使用decode,用什么编码来解码bytes(也就是用什么语言解码bytes)
文件与编码
打开一个py文件,都有一定编码相对应,比如你的文件是utf8格式的文件,如果你用gbk打开,就会发生乱码,你必须用和文件一样的编码打开。
一般情况下pycharm会自动识别文件的编码格式然后用相应的编码打开。
默认编码就是解释器打开文件的时候默认的编码
python2的默认编码是ascii,python3的默认编码是utf8,可以通过sys.getdefaultencoding()方法查看默认编码。
在py2上如果你写一个中文,你可能出错,因为py2是以ascii编码打开的,识别不了utf8,如果你在前面加上coding:utf8,这样文件就会以utf8编码格式打开
文件与执行
在py3上创建一个文件,写下
print(‘哈哈’)
这个文件是utf8方式保存的,在硬盘上是以二进制存储的。
当我们执行这个文件,会以utf8编码格式存储在内存,但是里面的‘哈哈’字符串会另外存储在内存的一个区域,以unicode编码存储。
如果在py2上创建,字符串则是以不同类型的字节数据存储的。
常见错误
hello.py
#coding:utf8
print ('苑昊')
文件保存时的编码也为utf8。
思考:为什么在IDE下用2或3执行都没问题,在cmd.exe下3正确,2乱码呢?
我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身就是一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print'苑昊'时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe显示,而在py2里这个内容就是utf8编码的字节数据,而这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,符合ISO统一标准的,所以没问题。
参考文章:
http://www.cnblogs.com/yuanchenqi/articles/5938733.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









