






1.三元运算
例子a,b,c=1,3,5
d=a if a>b else c
printf(d)
2.python的数据类型
整形(int):python2分长整形和整形
浮点型(float):简单的比如小数
布尔值:真或假 1或0
字符串:helloword
3.数据运算
运算符:
+ - * /(加减乘除)
%取模 eg 9%4=1
**次方eg 2**3=8
//取整eg 9//4=2
比较运算
==等于
!=不等于
<>不低于
<
>
>=
<=
赋值运算:
==
+= c+=a--->c=c+a
-= c-=a--->c=c-a
*= c*=a--->c=c*a
%= c%=a--->c=c%a
//= c//=a--->c=c//a
**= c**=a--->c=c**a
逻辑运算:
and布尔“与”,同时为真即真,一假必假
or布尔“或”,一真即真
not布尔“非”,真假相反 x为真则返回为假,x为假则返回为真
成员运算:
& 按位与运算 两位同时为“1”,结果才为1,否则为0
| 按位或运算 只要有一个为1,值就为1
^ 按位异或 相同为0,相异为1
eg:
x=0101,y=1011
x^y==1110
~ 对二进制数取反
<< 左移 a = a << 2将a的二进制位左移2位 ,相当于该数乘以2。
eg:
a=0011 0011 #十进制等于51
a==a<<2 a==1100 1100 #十进制等于204
>> 右移 a = a >> 2 将a的二进制位右移2位,相当于该数除以2。
eg:
|
1
2
3
|
a=1100 1100 #十进制为204a==a>>2a=00110011 #十进制为51 |
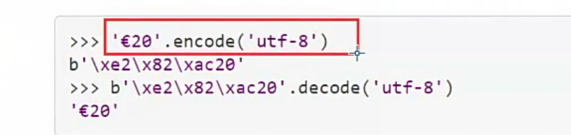
python3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,文本总是unicode,由str类型表示,二进制数据则由byte类型表示。
encode和decode的转换
列表的使用
切片:
# Author:Anjian Xu names=["NieLie", "YeZiYun","XiaoLingEr","YangLiShi"] 切片 print(names) print(names[0],names[2],names[3]) print(names[1:3])#打印列表里面的第二个和第三个 print(names[1:])#打印列表里从第一个开始到最后 print(names[:])#打印从开始到结尾与print(names)差不多 ******运行结果*******
['NieLie', 'YeZiYun', 'XiaoLingEr', 'YangLiShi']
NieLie XiaoLingEr YangLiShi
['YeZiYun', 'XiaoLingEr']
['YeZiYun', 'XiaoLingEr', 'YangLiShi']
['NieLie', 'YeZiYun', 'XiaoLingEr', 'YangLiShi']
******运行结果*******
''' #增 names.append("DuZe")#.append()默认增加在最后 names.insert(1,"DuZe") #.insert(位置,“增的内容”)即:在指定位置增加 print(names)
******运行结果*******
['NieLie', 'DuZe', 'YeZiYun', 'XiaoLingEr', 'YangLiShi', 'DuZe']******运行结果*******
#改
''' names[0]="nielie" print(names) '''
******运行结果*******
['nielie', 'YeZiYun', 'XiaoLingEr', 'YangLiShi']
******运行结果*******
#删 ''' names.remove("YangLiShi") del names[0] names.pop(1)#不填写时默认删除最后一个 print(names)
******运行结果*******
['YeZiYun']
******运行结果*******
''' #查 ''' print(names.index("YangLiShi"))#查出来的是它在列表中的位置
print(names[names.index("YangLiShi")])
******运行结果*******
3
YangLiShi
******运行结果*******
''' #统计同一个变量名 ''' names.insert(1,"YangLiShi")#因为开始的时候列表中只有一个YangLiShi,所以先在这增加一个 print(names) print(names.count("YangLiShi"))#统计YangLiShi个数
******运行结果*******
['NieLie', 'YangLiShi', 'YeZiYun', 'XiaoLingEr', 'YangLiShi']
2
******运行结果*******
''' #清空列表 ''' names.clear() print(names) '''
******运行结果*******
[]
******运行结果*******
#反转列表 ''' names.reverse() print(names) '''
******运行结果*******
['YangLiShi', 'XiaoLingEr', 'YeZiYun', 'NieLie']
******运行结果*******
#排序 names2=["#NieLie", "1YeZiYun","aXiaoLingEr","^YangLiShi"]
''' names2.sort() print(names2)
******运行结果*******
['#NieLie', '1YeZiYun', '^YangLiShi', 'aXiaoLingEr']
******运行结果*******
''' #合并 ''' names.extend(names2) print(names) '''
******运行结果*******
['NieLie', 'YeZiYun', 'XiaoLingEr', 'YangLiShi', '#NieLie', '1YeZiYun', 'aXiaoLingEr', '^YangLiShi']
******运行结果*******
#*步长切片隔一个打印一个 print(names[0:-1:2])#0,-1范围2步长 #names2=[1,2,3,4] #names.extend(names2)
******运行结果*******
['NieLie', 'XiaoLingEr']
******运行结果*******
copy:
*复制
.copy(浅copy,只copy第一一层)
names2=names.copy()
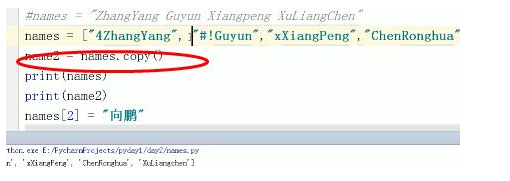
列表里面可以添加子列表

*完整复制,在最前面import.copy{很少用占内存}
names2=names.deepcopy()

*列表循环for i in names
print(i)
*步长切片
隔一个打印一个
print(names[0:-1:2])
*用浅copy来实现比如双胞胎孩子的信息,因为他们只有姓名不同
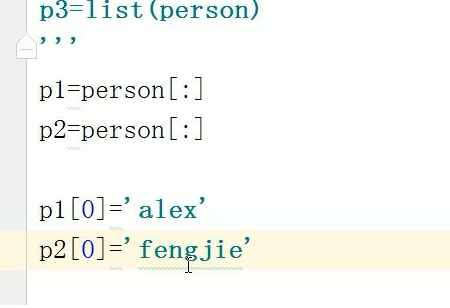
夫妻两人共同存款帐号
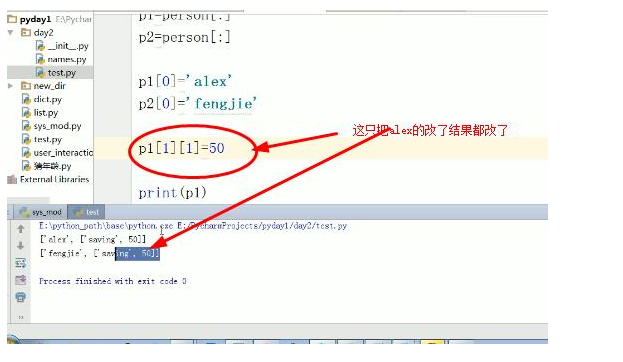
*元组(只能查不能修改)也叫只读列表
写法
tuple.py

购物车程序
需求:
1.启动程序后,让用户输入工资,然后打印商品列表
2.允许用户根据商品编号购买商品
3.用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
4.可随时退出,退出时,打印已购买商品和余额
shopping_list=[] product_list=[ ('iphone',5888), ('mac pro',12000), ('bike',800), ('alex python',120), ('coffee',31), ] salary=input('please input your salary:') if salary.isdigit(): salary=int(salary) while True: for index,item in enumerate(product_list): # print(product_list.index(item),item) print(index,item) user_choice=input("选择要买啥?>>:") if user_choice.isdigit(): user_choice=int(user_choice) if user_choice<len(product_list) and user_choice>=0: p_item=product_list[user_choice] if p_item[1]<=salary: #买得起 shopping_list.append(p_item) salary -=p_item[1] print("Added %s into shopping cart,your current balsnce is \033[31;1m%s\033[0m"%(p_item,salary)) else: print("\033[41;1m你的余额已剩[%s],还买个毛线啊\033[0m"%salary) else: print("product code [%s] is not list"%user_choice) elif user_choice=='q': print("exit......") else: print("invild option") else: print("输入数字啊,傻嗨!")
字符串操作


1 # author:"Jason lincoln" 2 3 #name ='my \tname is alex' 4 name="my \tname is {name} and i am {year} years old" 5 print(name.capitalize()) #首字母大写 6 print(name.count("a")) #统计 7 print(name.center(50,"-")) #打印50个字符,不够用“-”补齐,name放中间 8 print(name.endswith("ex")) #判断字符串以什么结尾 9 print(name.expandtabs(tabsize=30)) #加空格,没什么卵用 10 print (name[name.find("name"):]) #切片 11 print(name.format(name='alex',year=23)) 12 print(name.format_map({'name':'alex','year':23})) 13 print('abc123'.isalnum()) #是不是阿拉伯数字和字母 14 print('Aassafsdf'.isalpha()) #是不是纯英文字母 15 print('10'.isdigit()) #是不是整数 16 print('1f'.isdecimal()) #是不是十进制 17 print('f-f'.isidentifier())#判断是不是一个合法的标识符 18 print('22'.isnumeric()) #是不是只有数字 19 print('qqQ'.isupper()) #是不是全是大写 20 print('+'.join(['1','2','3','4'])) 21 print(name.ljust(50,'*')) #放左边,不够用*补齐 22 print(name.rjust(50,'*')) #放右边,不够用*补齐 23 print('ALEX'.lower()) #变小写 24 print('alex'.upper()) #变大写 25 print('\nalex'.lstrip())#去左边的空格回车 26 print('alex\n'.rstrip())#去右边的空格回车 27 print(' alex\n'.strip())#去两边空格回车 28 p=str.maketrans("abcdeflix","123456789") #加密 29 print("alex li".translate(p)) #加密 30 print('alex li'.replace('l','L',1)) 31 print('alex li'.rfind('l')) #找到最右边的值的下标 32 print('1+2+3+4'.split('+')) 33 print('1+2\n3+4'.splitlines()) 34 print('Alex Li'.swapcase()) #大小写转换 35 print('alex li'.title()) 36 print('alex li'.zfill(50)) #不够用0补上
字典:
# author:"Jason lincoln" info={ 'stu1101':"TengLan Wu", 'stu102':"LongZe Luola", 'stu1103':"Xiaoze Maliya", } print(info) print(info['stu1101']) info["stu1101"]="武藤兰" info["stu1104"]="Cangjingkong" print(info) #del #del info['stu1101'] #print(info) print(info.get('stu1105')) #查 print('stu1103' in info) #info has_key('stu1103') py2.x 判断 b={ 'stu1101':'alex', 1:3, 2:5, } info.update(b) print(info) print(info.items()) #把字典转成列表 c=dict.fromkeys([6,7,8],"test") #初始化列表 print(c) c=dict.fromkeys([6,7,8],[1,{"name":"alex"},444]) print(c) c[7][1]='jack chen' print(c) for i in info: #字典转成列表 高效 print(i,info[i]) for k,v in info.items(): print(k,v)
多层嵌套:
# author:"Jason lincoln" av_catalog={ '欧美':{ 'www.youporn.com':['很多免费的,世界最大的','质量一般'], 'www.pornhub.com':['很多免费的,也很大','质量比youporn高点'], 'letmedothistoyou.com':['质量很高,真的很高','全部收费,屌丝请绕过 '], },"日韩": {'tokyo-hot':["质量不怎么样",'听说是收费的'] }, '大陆':{ '1024':['全部免费,真好,好人一生平安','服务器在国外,慢'] }, } av_catalog['大陆']['1024'][1]="可以在国内做镜像" av_catalog.setdefault("大陆",{'www.baidu,com':['呵呵']}) #找到key就替换,找不到就创建 print(av_catalog)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









