






 本文详细解释了数据库事务的四种隔离级别:Read Uncommitted、Read Committed、Repeatable Read 和 Serializable 的概念及其应用场景。通过实例说明了脏读、不可重复读和幻读等问题,并探讨了这些现象在实际开发中的影响。
本文详细解释了数据库事务的四种隔离级别:Read Uncommitted、Read Committed、Repeatable Read 和 Serializable 的概念及其应用场景。通过实例说明了脏读、不可重复读和幻读等问题,并探讨了这些现象在实际开发中的影响。
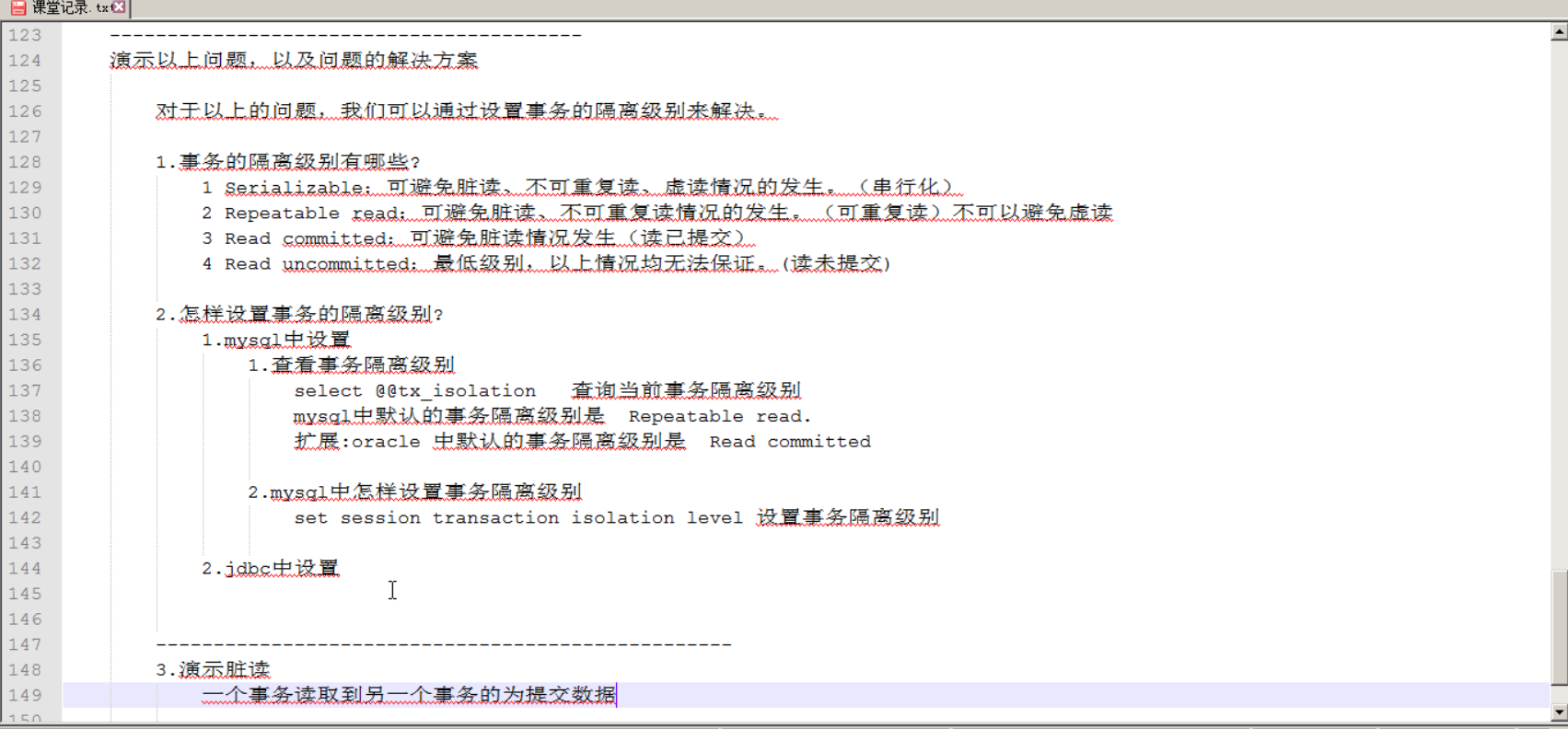
开两个cmd窗口,相当于两个事务。

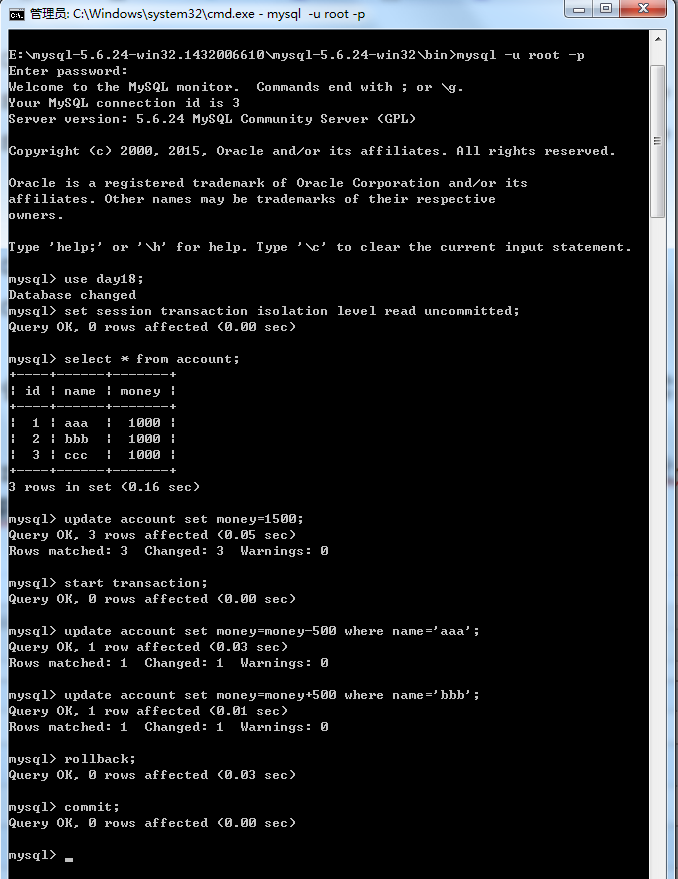
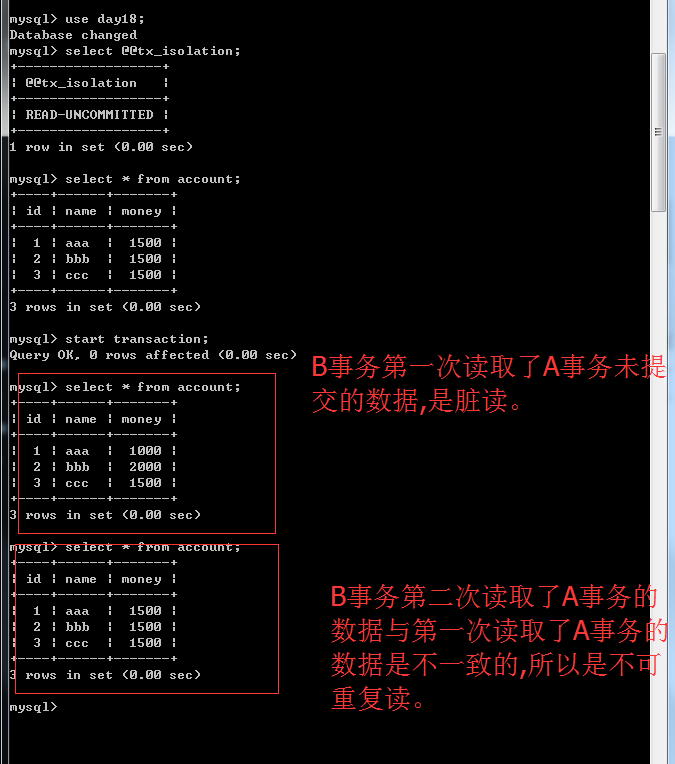
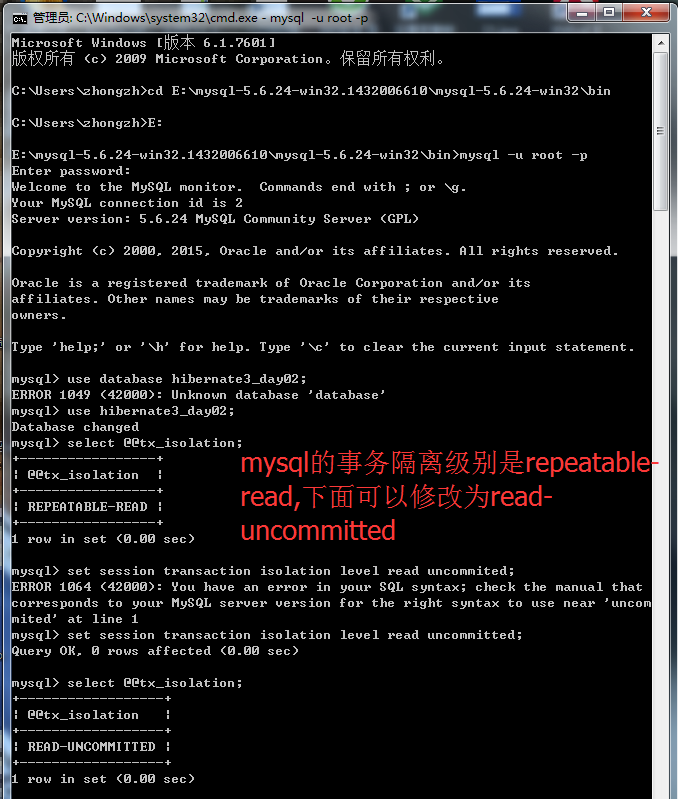
read-uncommitted这种级别是解决不了任何问题的,它什么情况都能出现。刚才演示了脏读,再演示就出现了不可重复读。
read-committed隔离级别能解决脏读问题。
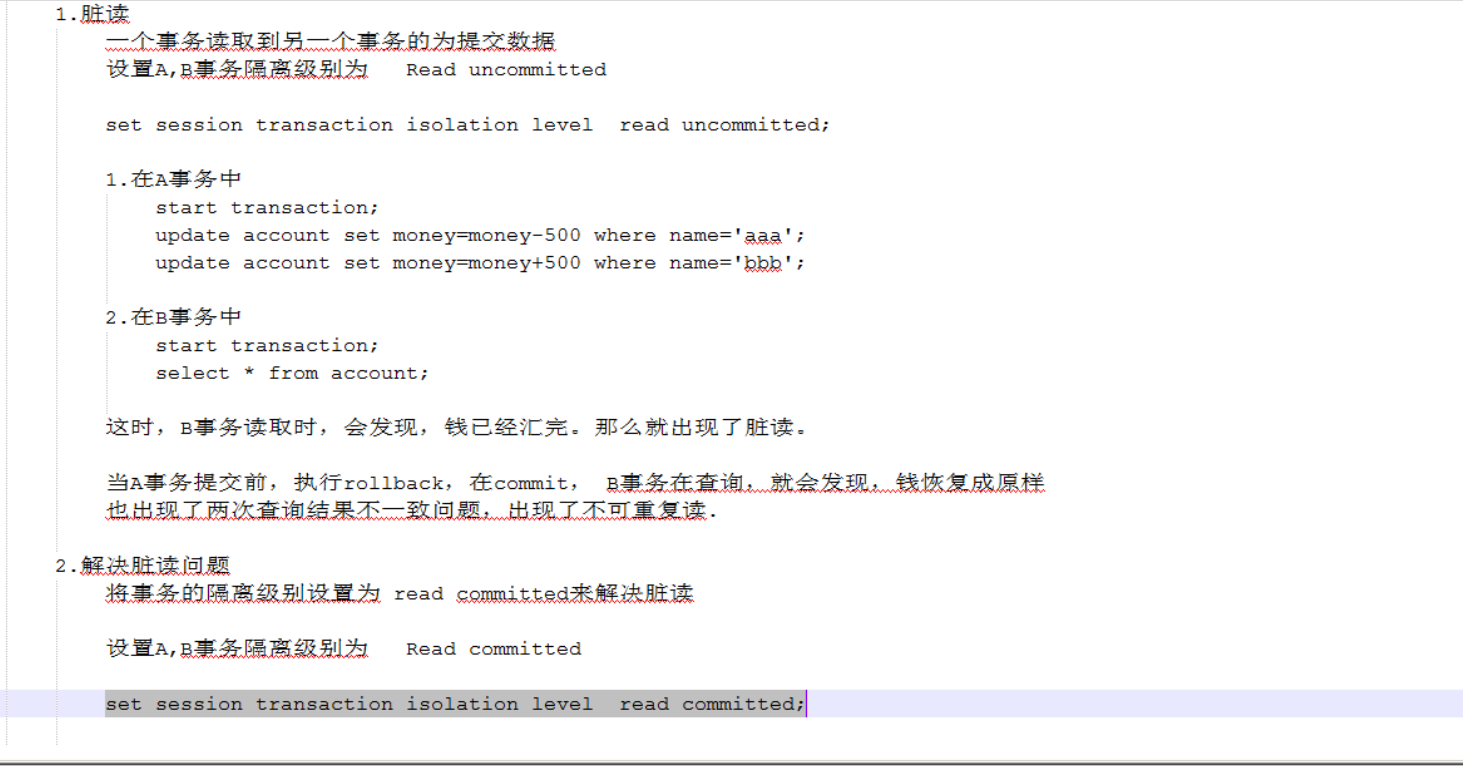
read-committed是解决了脏读的问题,但是还是出现了不可重复读的问题。


可能有的人会认为这没有问题,A事务提交commit之后我B事务读到没问题啊,这是正确的。这种情况在开发里面有时候是没有问题的有时候是有问题的。如果我现在要做报表,现在查询的数据要做成报表导出来,导成文件,例如说我做的是一个交通管理系统,我要统计这个月发生了多少起车祸,那就有问题了,第一次查八起车祸,第二次查十八起车祸,两次读取的结果不一样,因为你读取了别人提交的数据。问题是这个报表以哪个为准,第一次八起,第二次十八起,没准你第三次查又变了。不确定哪个数据为准。开发里面有时候会影响,因为你不知道用哪个数据。但是有些情况是我只是想看一下我也不想导成报表之类的,只是看一下那就无所谓了。但是有些情况就必须要求第一次和第二次查是一致的。所以不可重复读在某些情况是必须考虑的。
oralce的事务隔离级别是read-committed。不是说不可重复读是很严重的错误,至少人家oracle是允许这样的操作的,但是在某些情况下是不允许的。
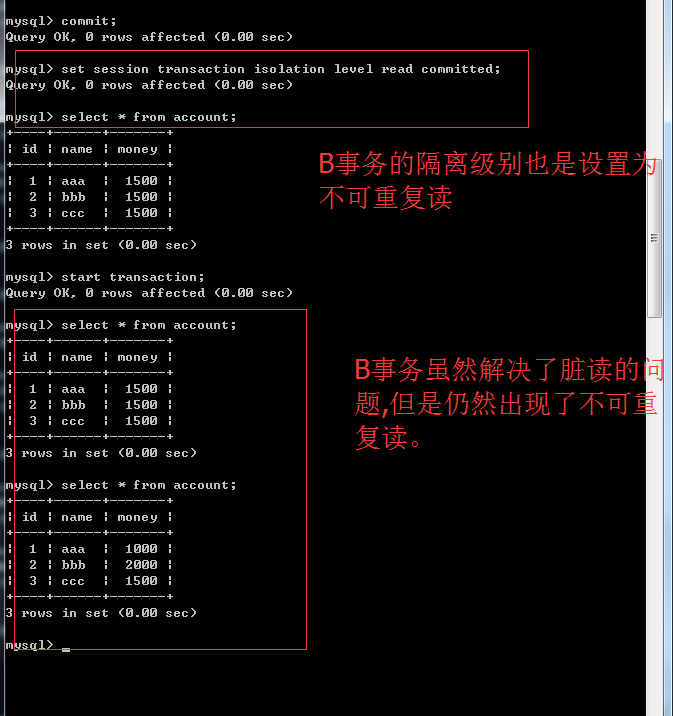
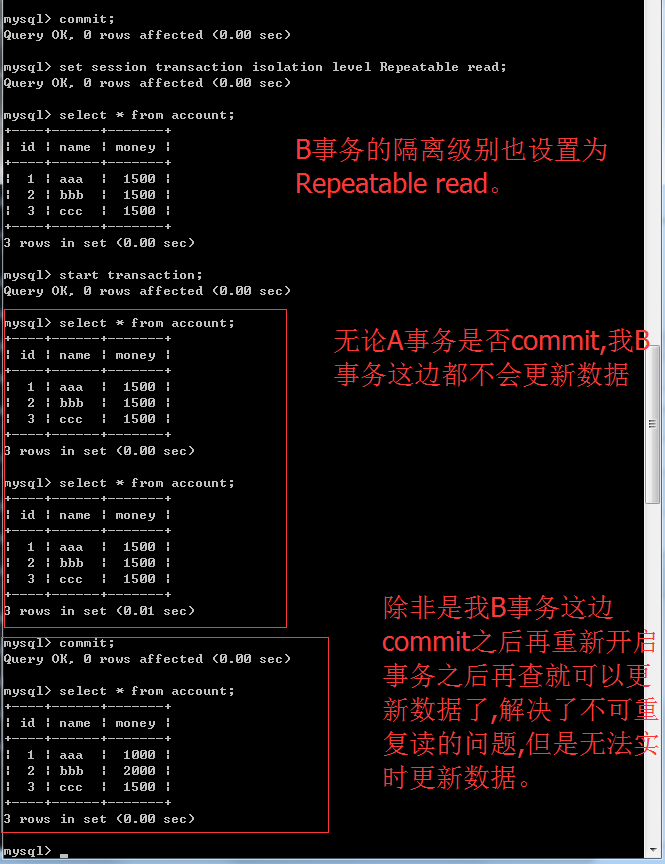
不可重复读就是一个事务读取了另外一个事务提交的数据。如果现在我的数据库的事务隔离级别是Repeatable read,那么在我的事务过程中,当A事务提交了数据,B事务这边也是不更新的,保证了我每次查询都是一样的。那么在这样的数据库隔离级别下,B事务怎么能读取A事务提交的数据呢?很简单,B事务commit之后再开启事务再读取就可以了。那么这种操作就能够保证在我的这个事务过程我的数据是OK的。但是Repeatable read是不能够实时更新数据。但是这种方案在开发中有的情况下是用的到的,就好像刚才说的做报表每次查询都不一样那不就废了吗?应该每次查都一样才能做报表。


虚读和幻读演示也是麻烦的事情,因为它是强调insert。这次读和上次读的条数不一样。它是在一定概率下会出现的。
如果事务隔离级别为串行化(Serializable)它会锁表。意思是我的事务操作过程中谁也玩不了,得等到我玩完了你再玩。只有A事务commit之后B事务才能查到。但是这种操作性能很垃圾。但是那种数据要求非常严格必须得准确你就得用这种数据库事务隔离级别。



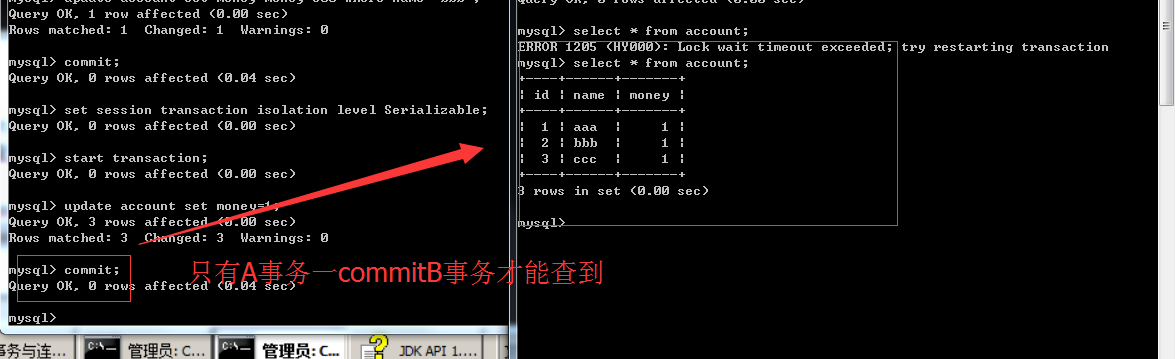
你连表操作的功能权限都没有,但是性能相当垃圾。

















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









