






 本文介绍如何通过SQL Server Profiler记录并分析慢查询,包括配置跟踪、分析日志文件及具体数据库优化方法,如执行计划分析和使用数据库引擎优化顾问。
本文介绍如何通过SQL Server Profiler记录并分析慢查询,包括配置跟踪、分析日志文件及具体数据库优化方法,如执行计划分析和使用数据库引擎优化顾问。
分三步:
记录慢查询的语句到日志文件
1、首先在SSMS,工具菜单下打开Profiler。
2、输入你用户名密码登陆。
3、常规,勾选保存到文件,选择一个文件路径,设置文件大小,这样可以分文件存储日志了
注意:在服务器本地,文件路径可以随便选择;跟踪远程服务器时这个路径设置需要使用\\ServerName\.......(应该是设置远程服务器能访问的本地一个共享路径,比较麻烦)
4、事件选择选择,选择以下两列即可,
Stored Procedures RPC:Completed
TSQL SQL:BatchCompleted
5、点击列筛选器,为Duration设置一个过滤值。本例子设置为3000(即3S)。
6、点击运行。开始信息的收集。
分析日志文件
远程分析时需要把日志文件*.trc拷贝到本地,打开SSMS连接本地数据库,使用如下语句查询:
SELECT a.TextData,a.StartTime,a.EndTime,Duration/1000000
FROM fn_trace_gettable('D:\QSWork\Sql跟踪文件\慢查询 - 1.trc', -1) a
注意:只有连接本地服务器,这个路径才可以使用绝对路径
数据库优化
1.在查询分析器里执行查看实际执行集合、IO和TIME占用情况
首先打开IO和TIME统计开关
SET STATISTICS TIME ON SET STATISTICS IO ON
打开后每次执行sql语句时在消息里就可以打出如下信息:
(1845345 行受影响)
表 'StockQuote'。扫描计数 1,逻辑读取 14025 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
为了保证每次都是从硬盘读取数据,所以要先清空缓存
--清空缓存 checkpoint DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHE
清空是否有效可以在先后两次执行sql的信息中看物理读取次数是否一样区分。
最后,在执行前选定“包括实际的执行计划”。执行结果:
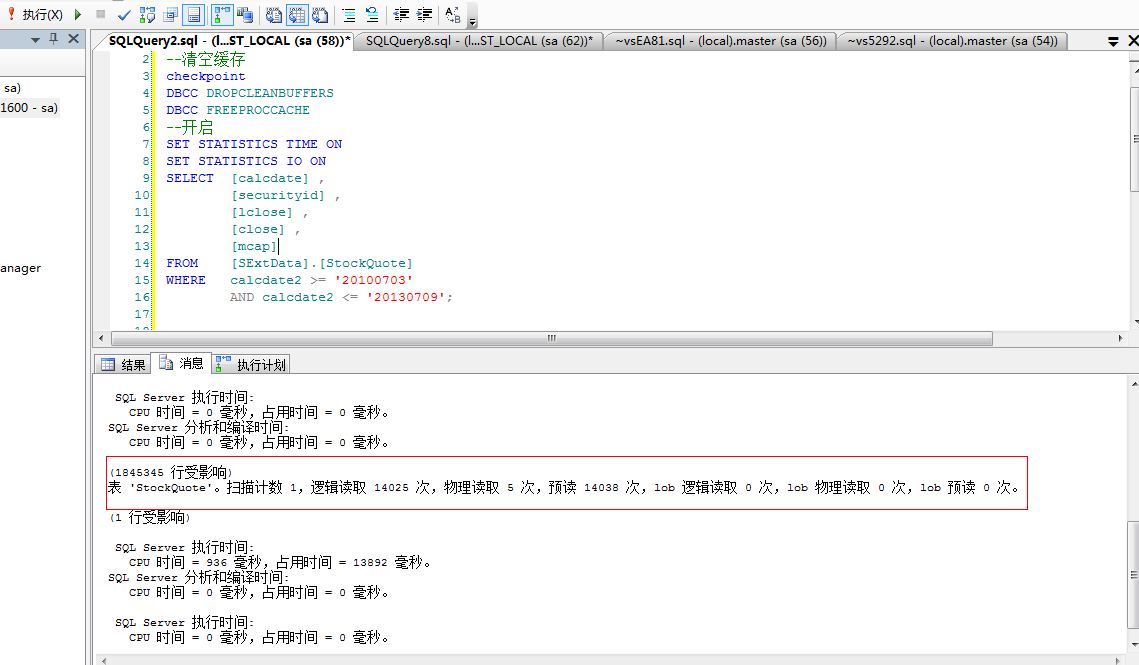
执行计划

根据执行情况优化 sql语句,发现索引、外键设计存在的问题
2.使用“数据库引擎优化顾问”执行sql得出性能优化建议
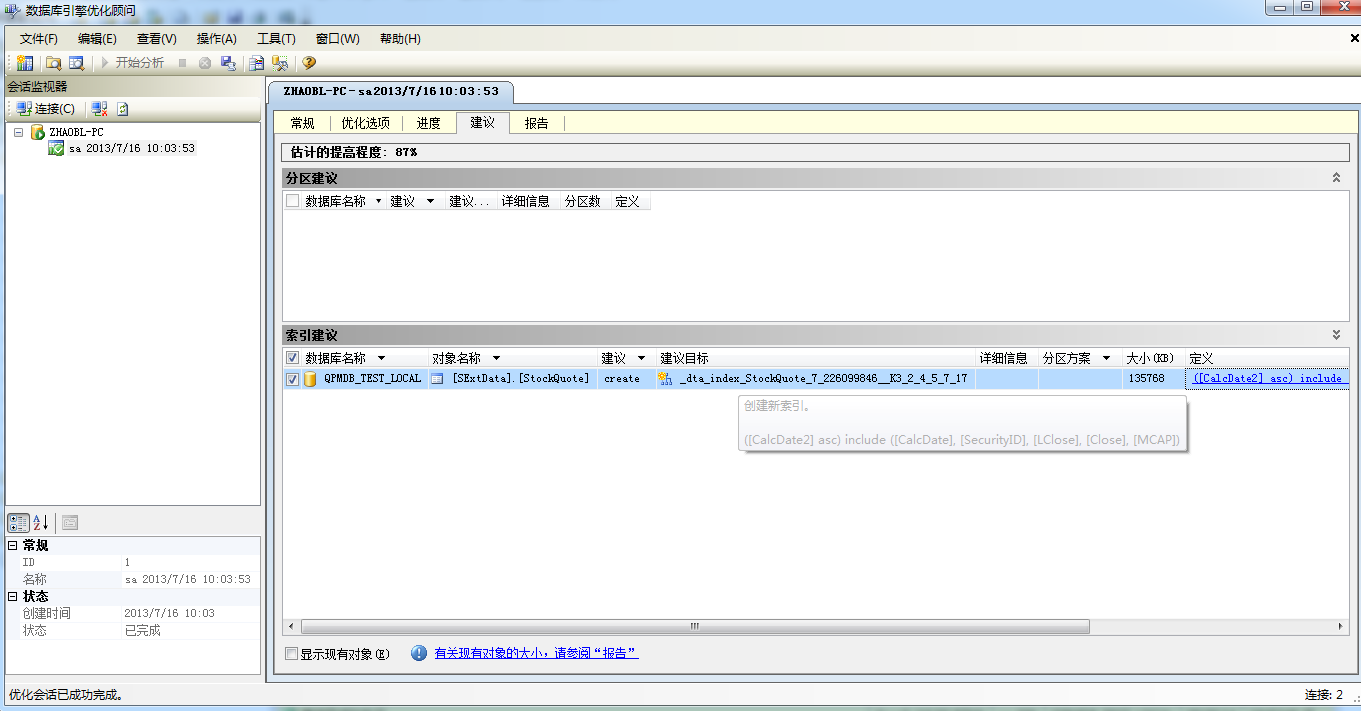
结论:有时候捕获到的sql执行时间过长可能是数据库的并发访问,或者前后执行的语句中存在资源竞用,这就得从业务逻辑上去查找一下原因。只有每次执行都比较耗时的,且调用比较频繁的语句才需要特别优化。
参考链接:
1.[MS Sql Server术语解释]预读,逻辑读,物理读
2.SQL Server datetime数据类型设计、优化误区

















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









