






 本文介绍了一个Python程序,该程序能够从指定文件中读取文本内容,并统计每个单词出现的频率。程序通过去除标点符号和空格来确保统计准确性,并最终输出词频最高的前十名单词。
本文介绍了一个Python程序,该程序能够从指定文件中读取文本内容,并统计每个单词出现的频率。程序通过去除标点符号和空格来确保统计准确性,并最终输出词频最高的前十名单词。
- 2017*****7012
- 石运
- 码云地址:https://gitee.com/xgxdmx/word_frequency.git
- 程序分析:
- def process_file(file): # 读文件到缓冲区
try: # 打开文件
text = open(file)
except IOError as s:
print(s)
return None
try: # 读文件到缓冲区
buffer = text.read()
except:
print("Read File Error!")
return None
text.close()
return buffer
此函数负责打开读取文档并将文档存储到buffer里面,执行完毕后关闭文档 - def process_buffer(buffer):
if buffer:
word_freq = {}
# 下面添加处理缓冲区 buffer代码,统计每个单词的频率,存放在字典word_freq
for i in buffer.split():
individual_word = i.strip(punctuation + ' ')
if individual_word in word_freq:
word_freq[individual_word] += 1
else:
word_freq[individual_word] = 1
return word_freq
此函数负责将buffer内的数据进行切片,引用punctuation去掉符号空格,并用for循环进行统计,将统计数据存储在word_freq并返回值 - def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
print("词频统计:")
# 输出 Top 10 的单词
for item in range(len(sorted_word_freq[:10])):
i, count = sorted_word_freq[item]
print("{0:<10}{1:>5}".format(i, count))
此函数将统计好的数据进行排序并输出前十个数据 - if name == "main":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
buffer = process_file(dst)
word_freq = process_buffer(buffer)
output_result(word_freq)
在主函数启动后导入argparse包,并执行上述几个函数 - 性能分析结果及改进:
执行时间最长的代码:def process_buffer(buffer)
执行次数最多的代码:sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) - 程序运行命令、运行结果截图以及改进后的程序运行命令及结果截图
- 改进前:
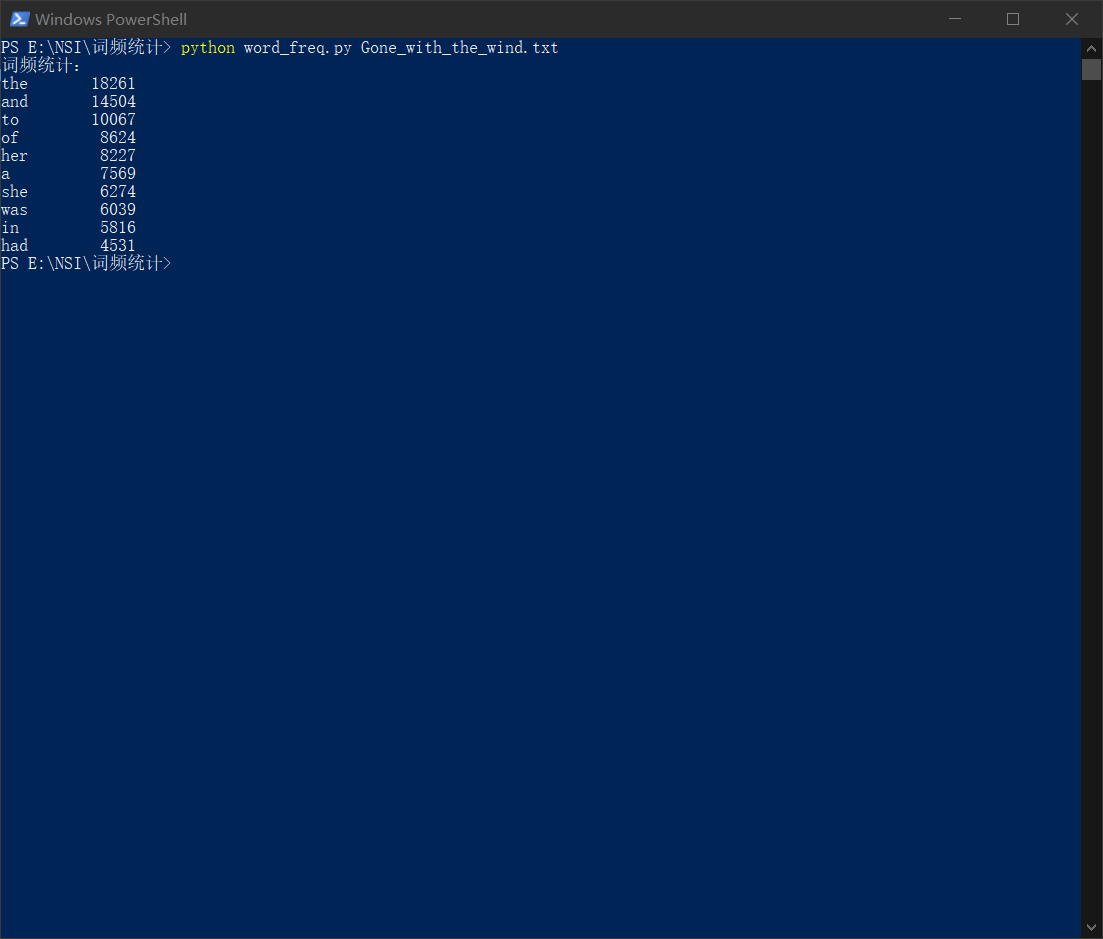
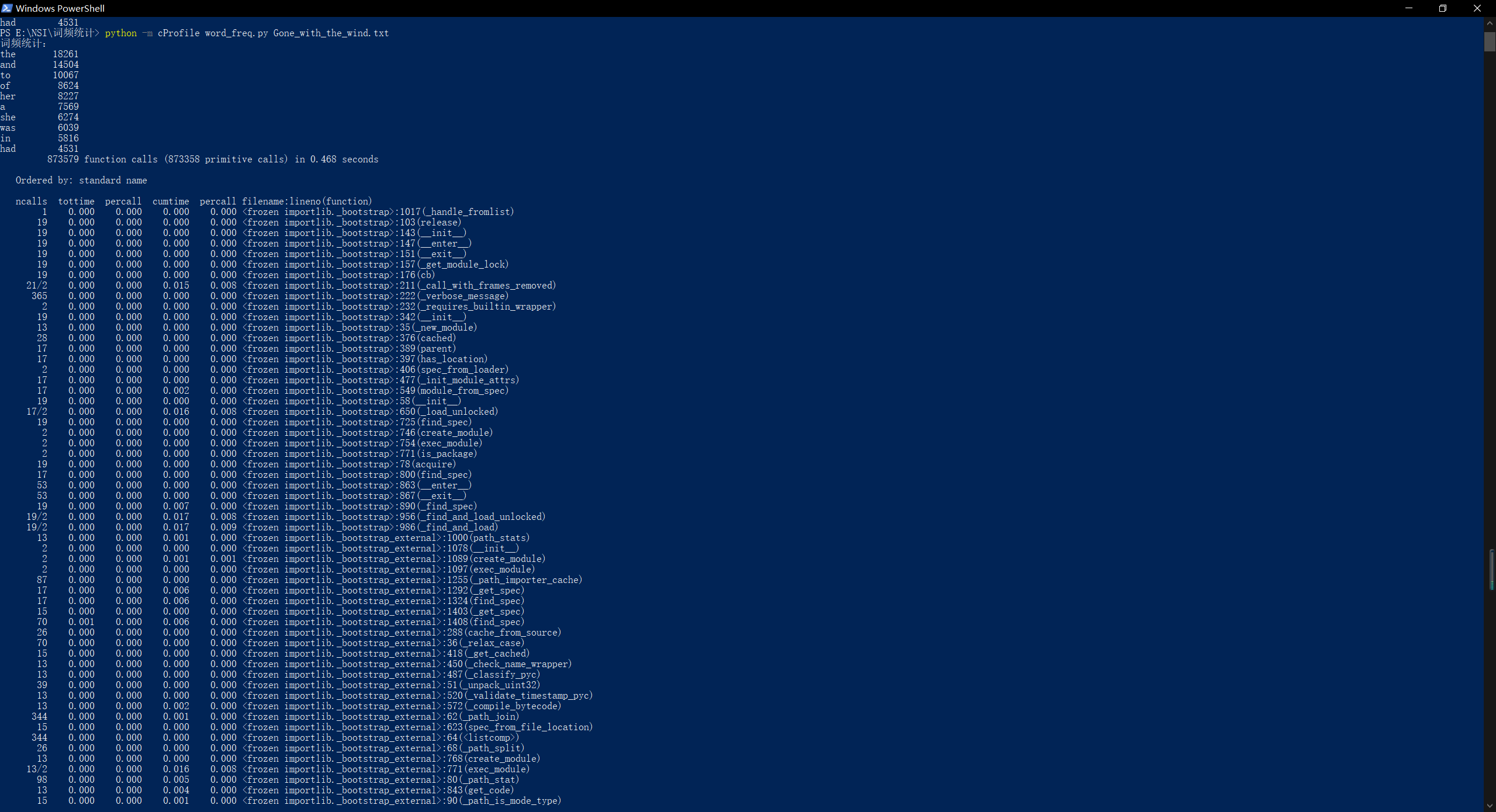
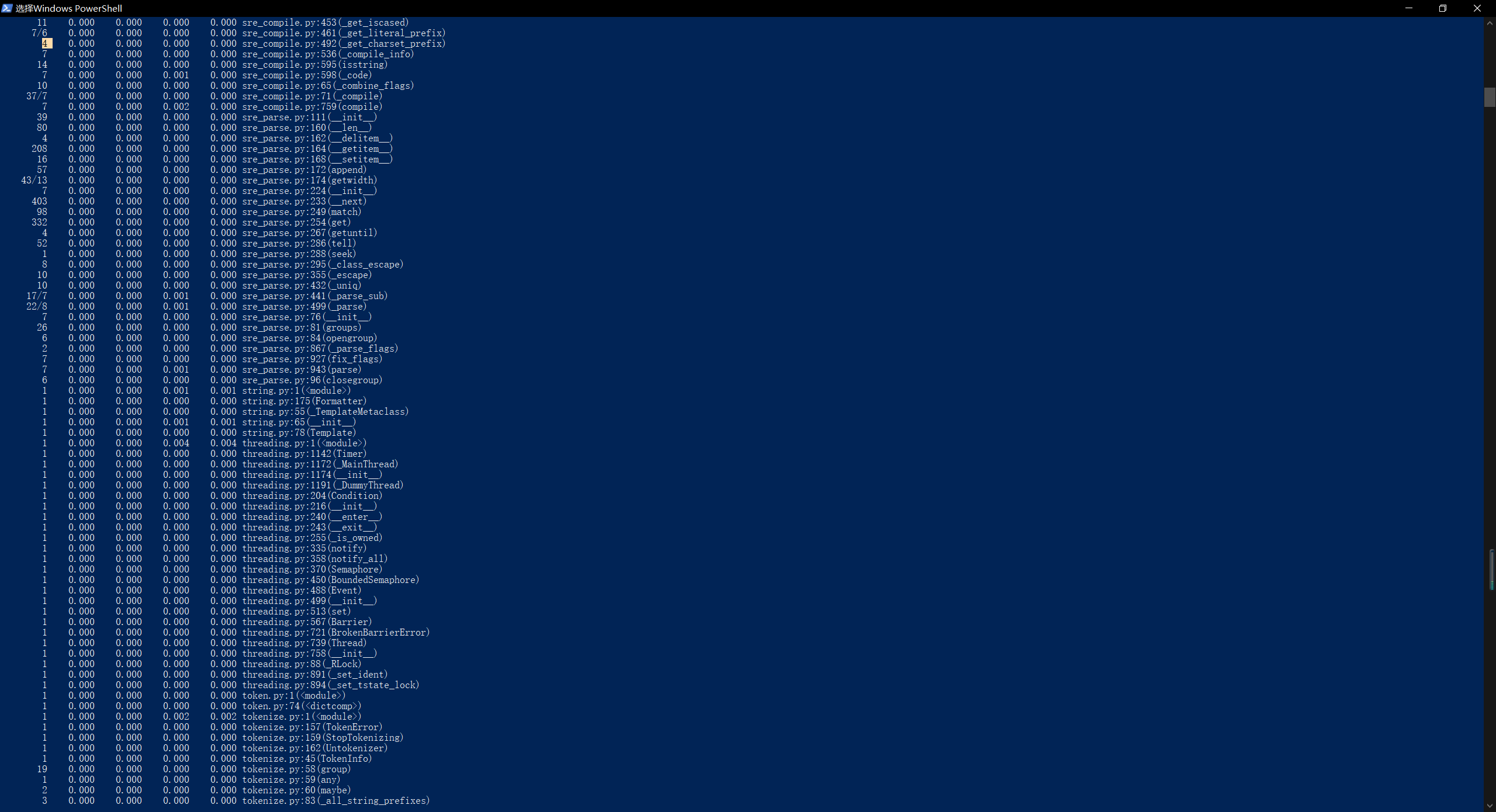
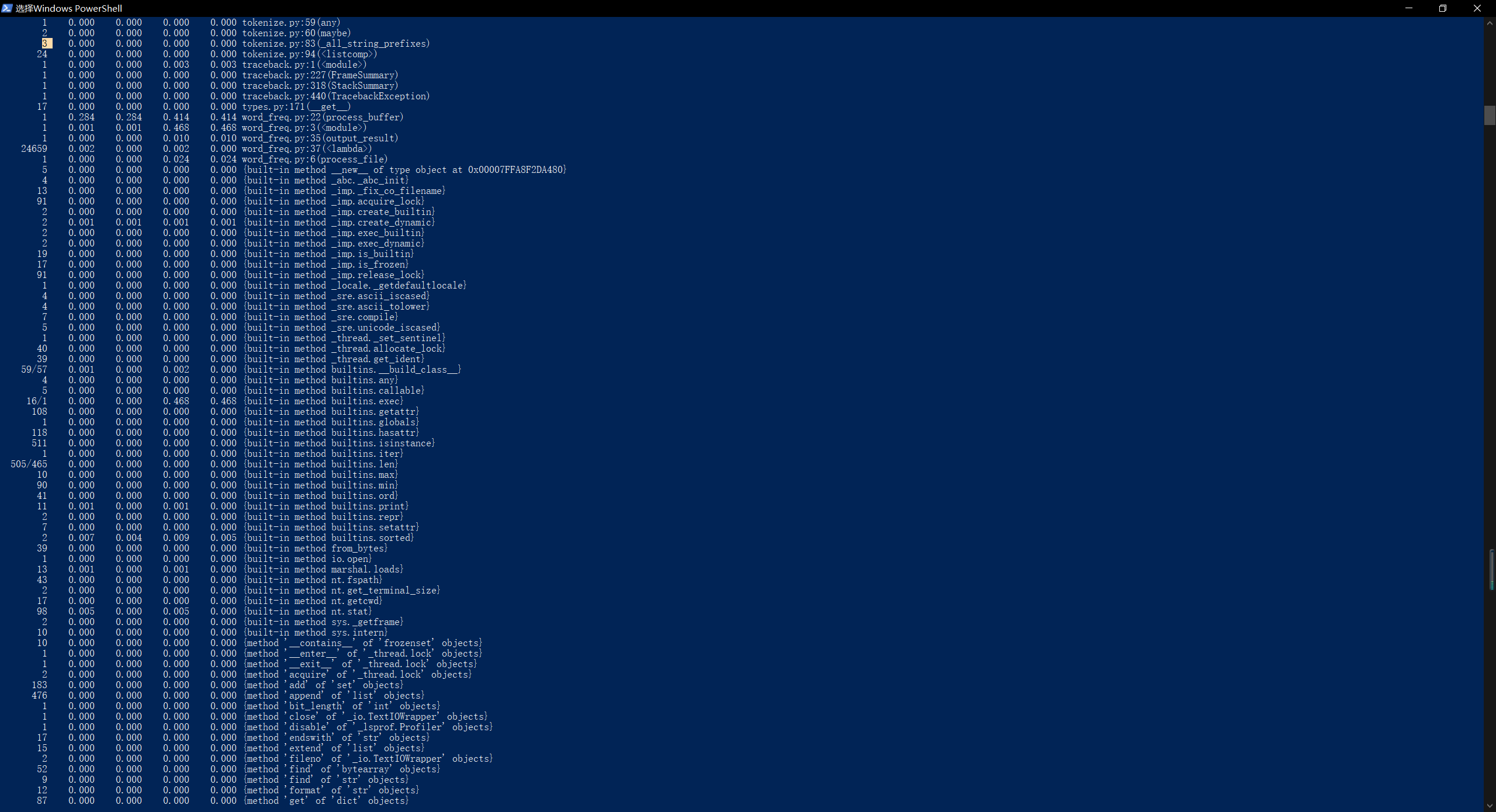
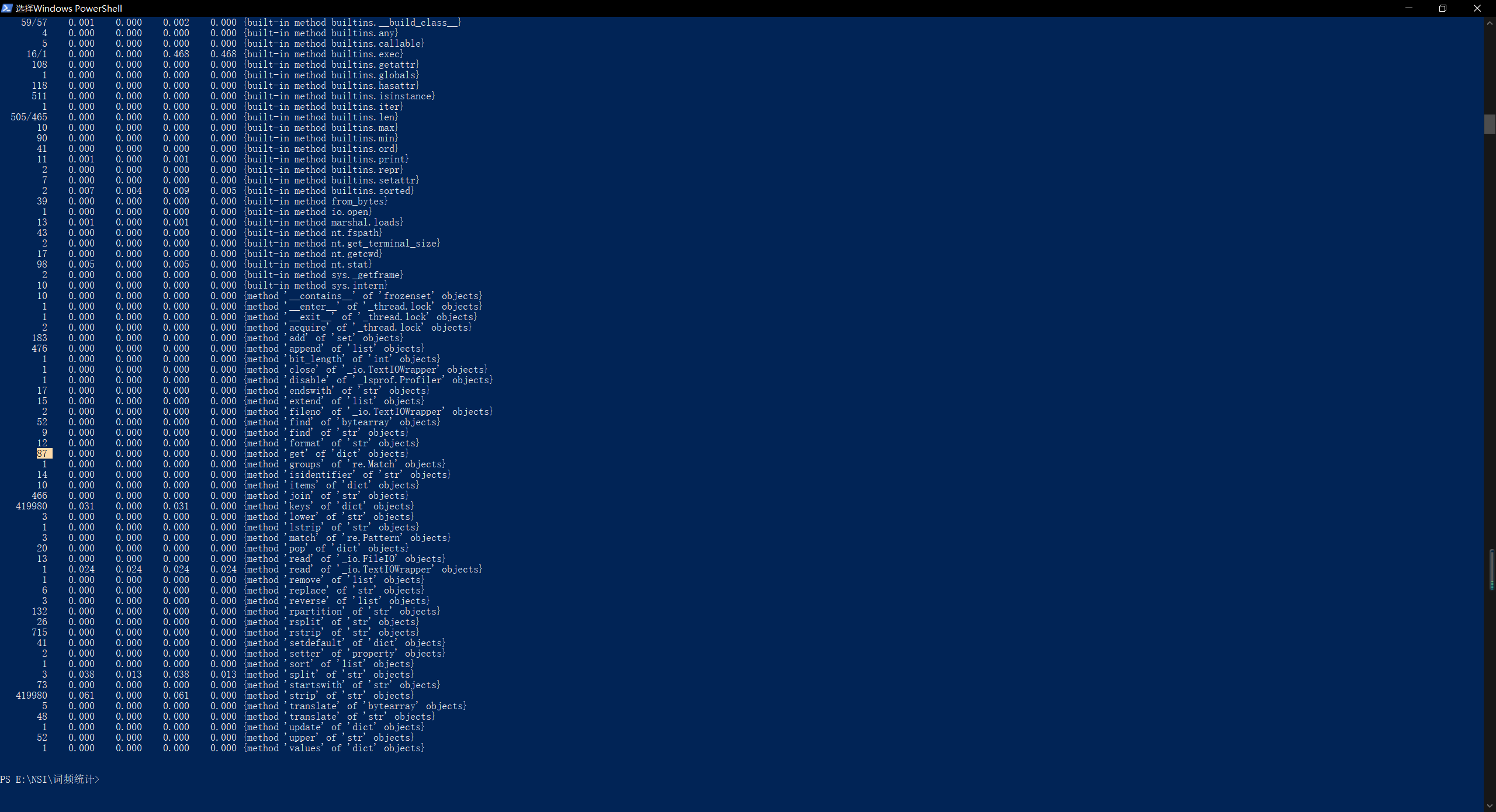
改进后: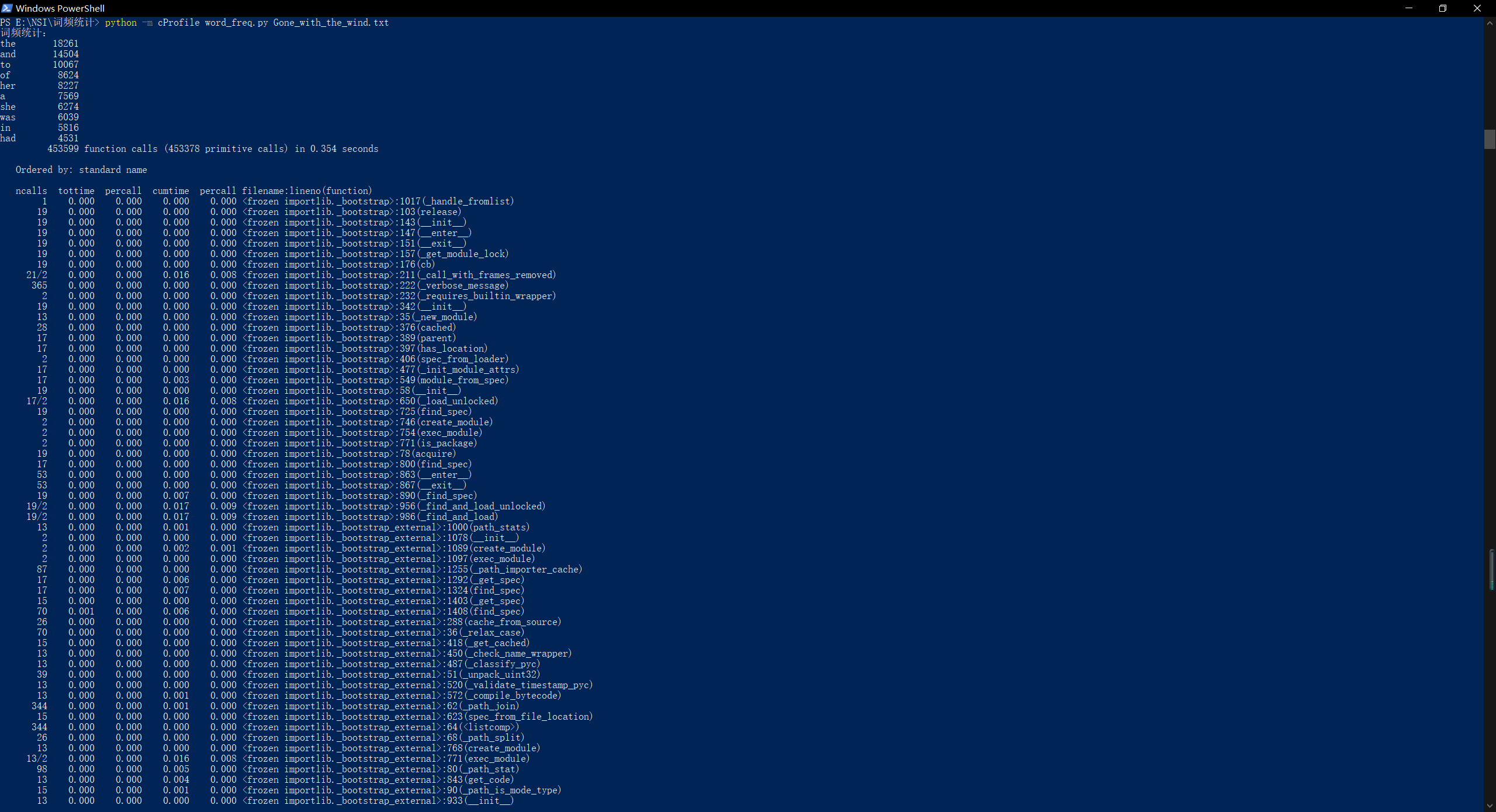
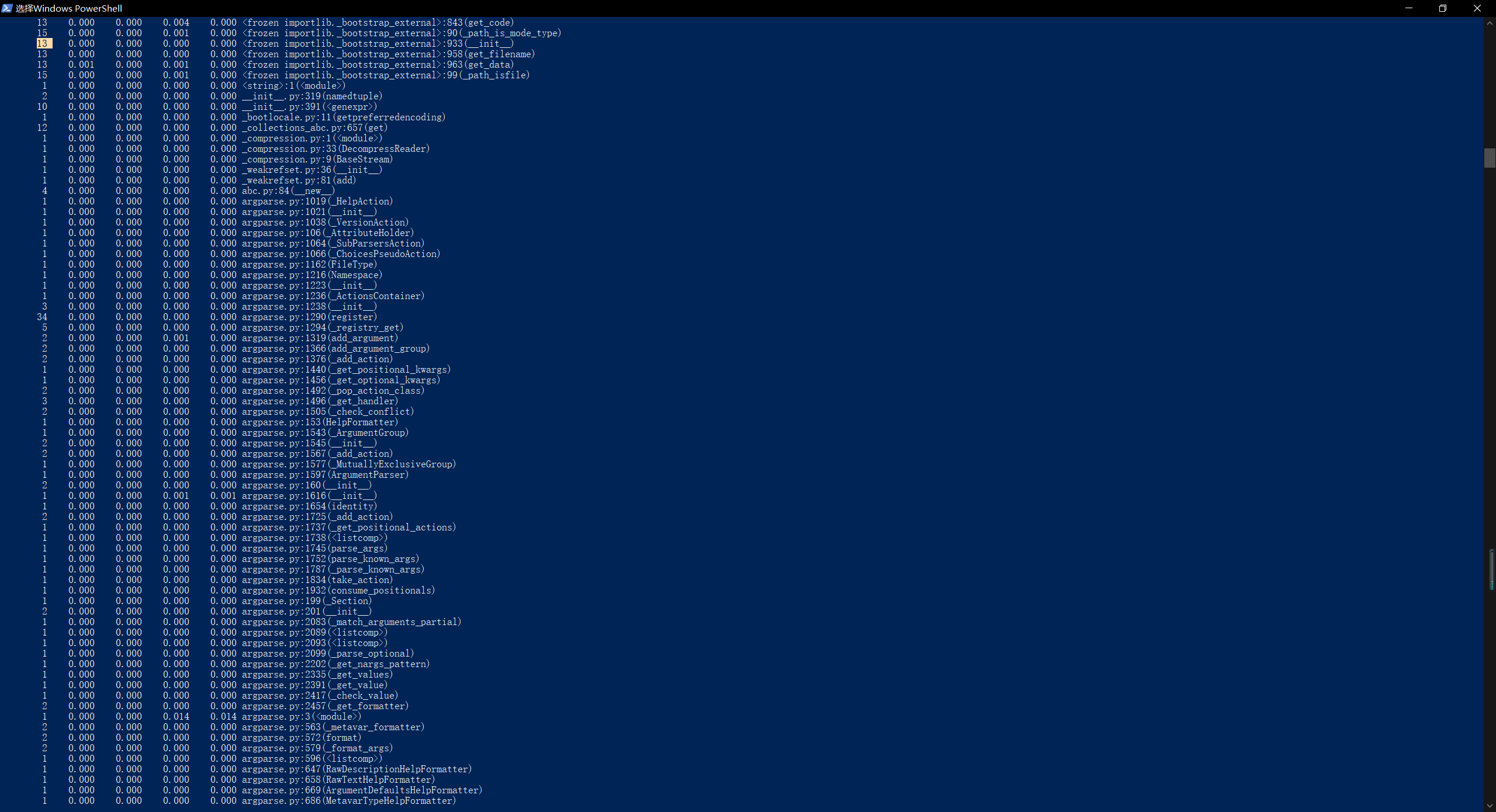
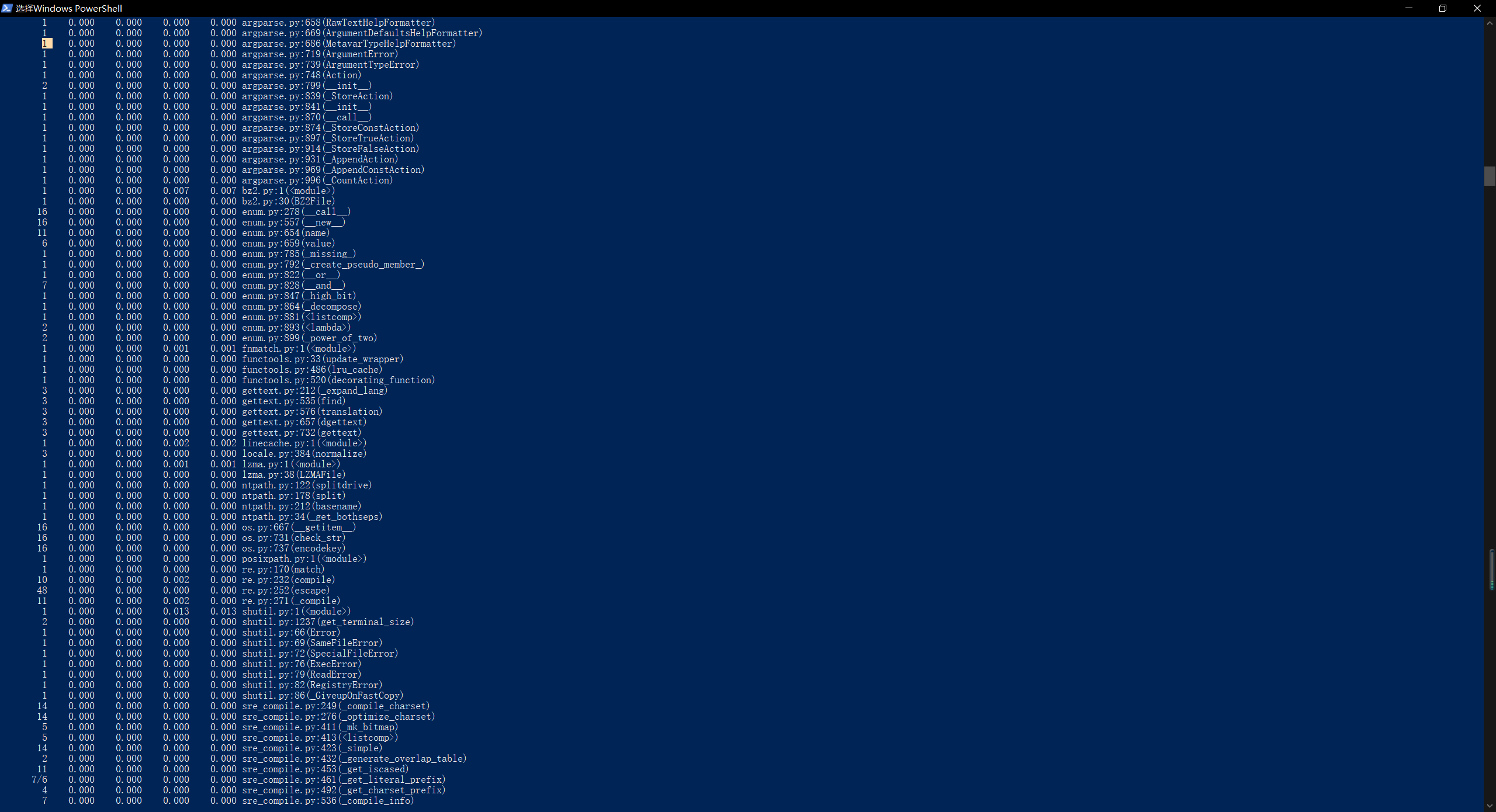
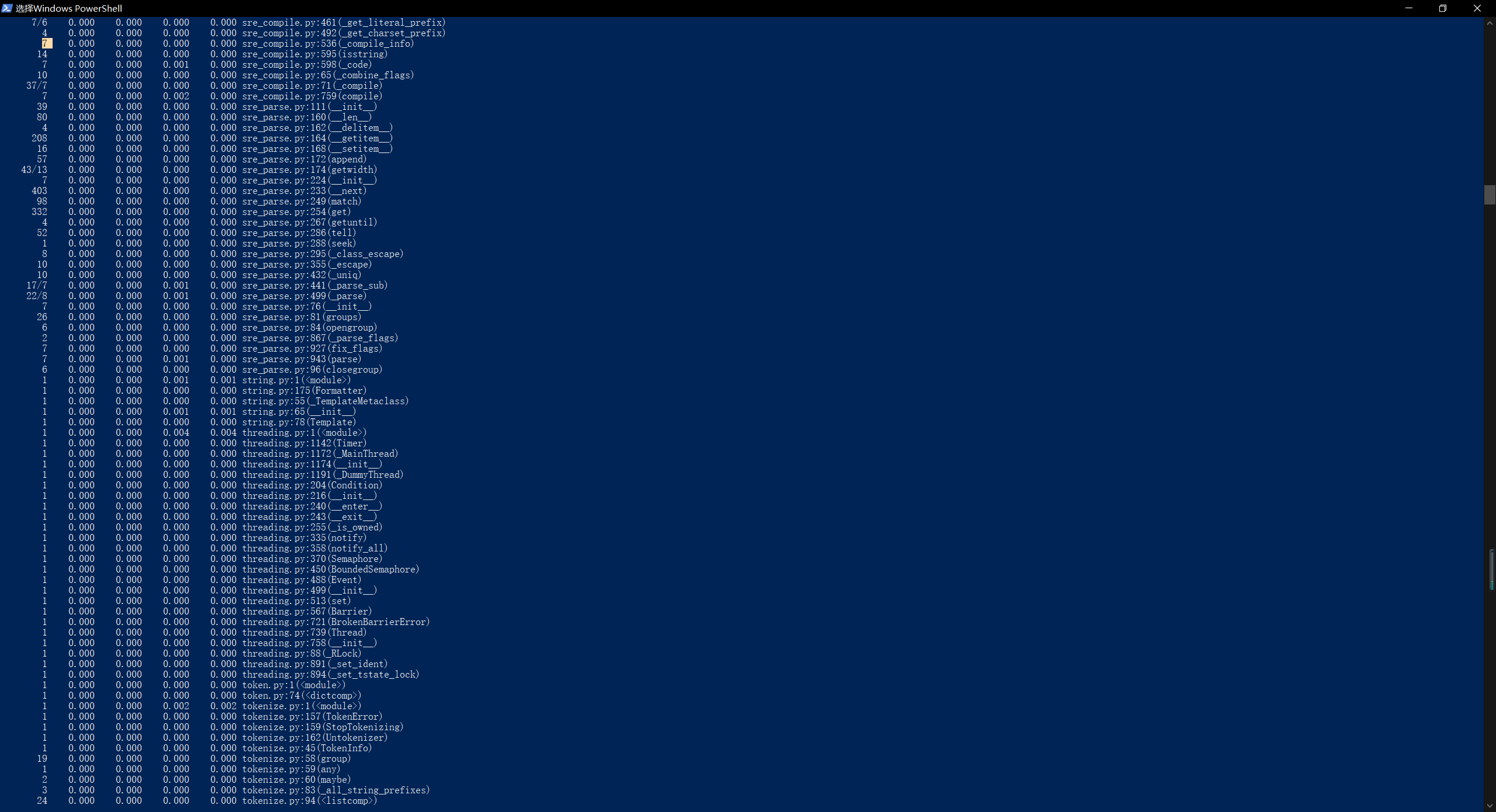
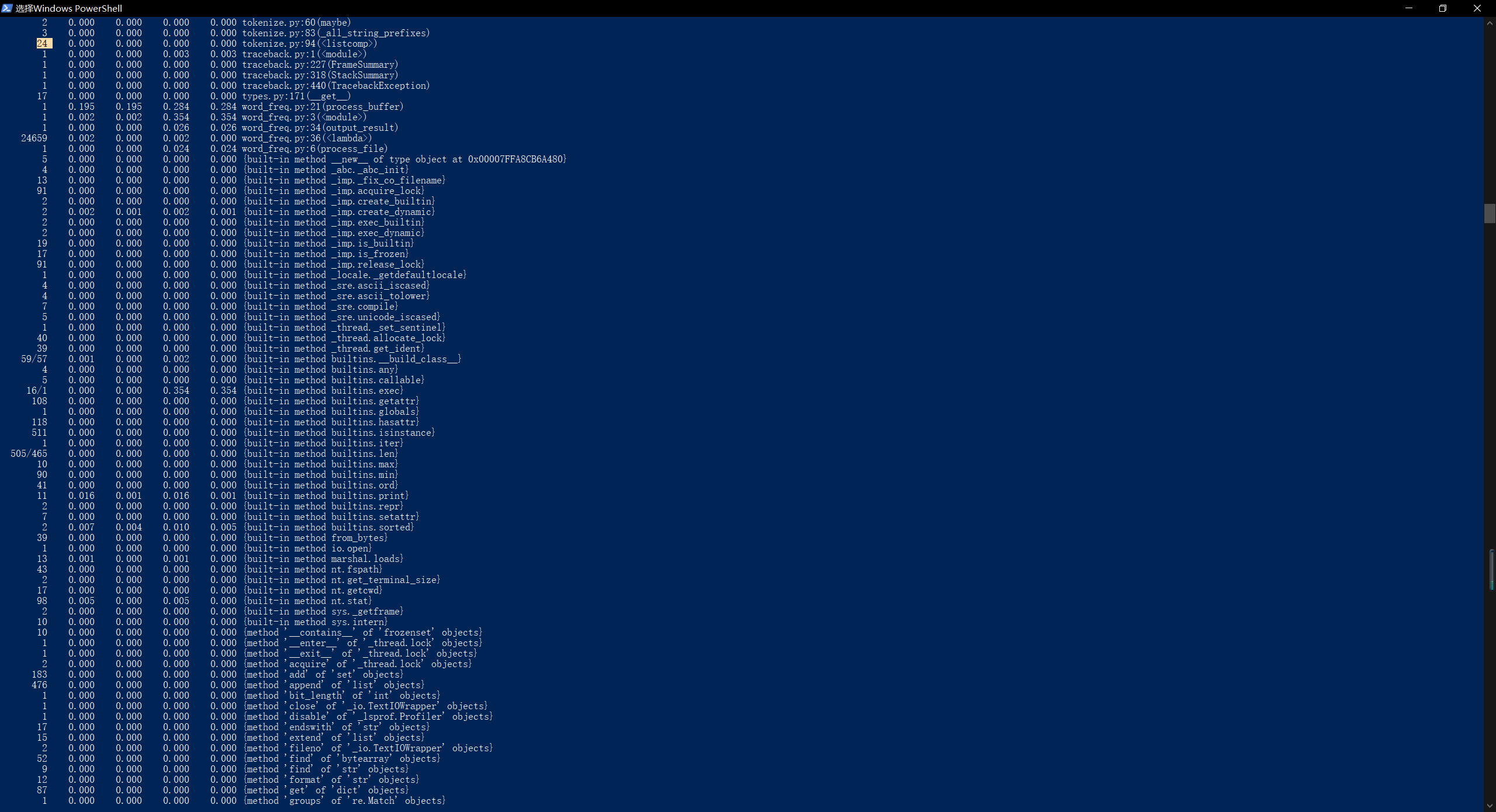
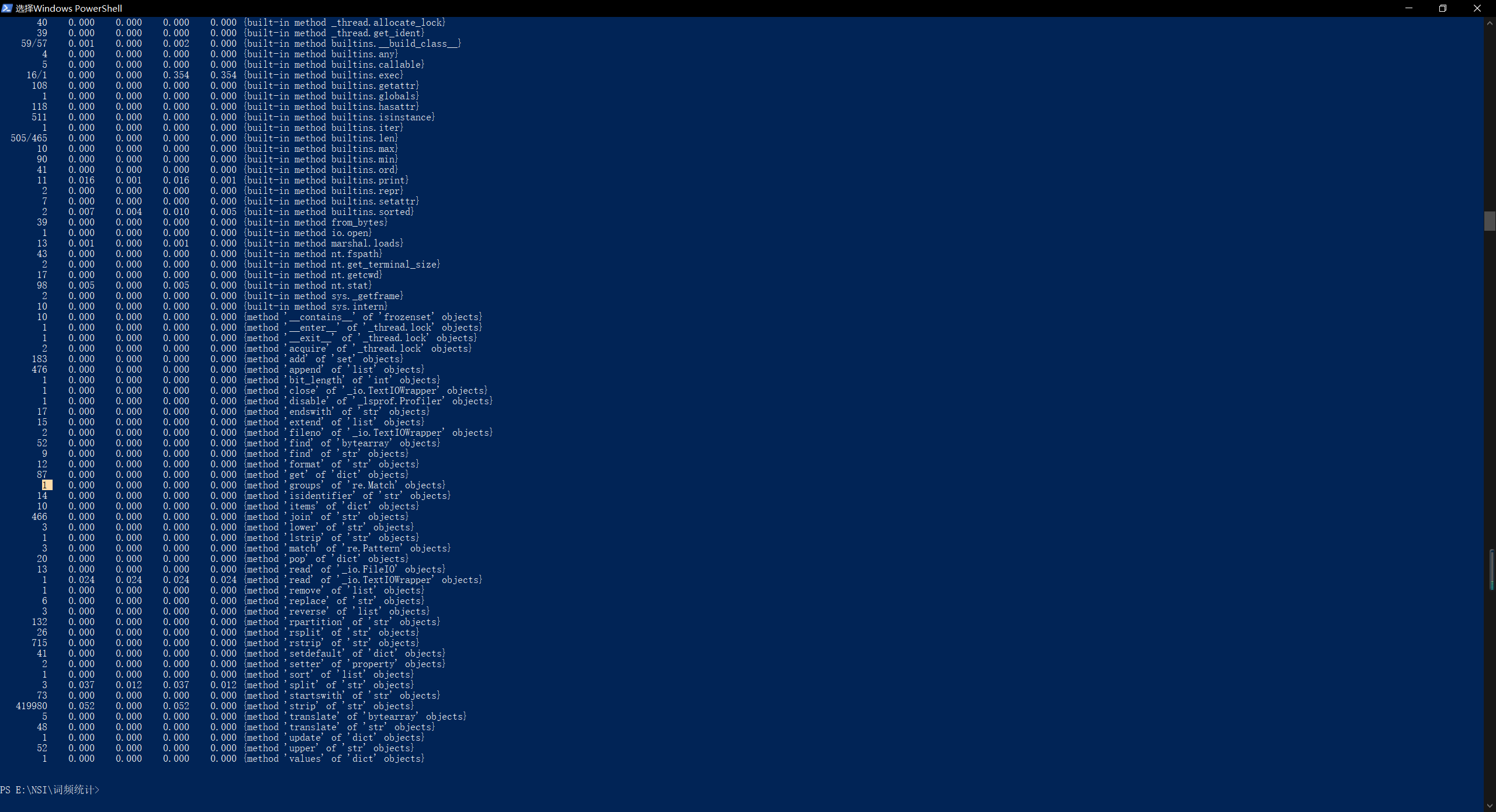
- 总结与反思
此程序让我熟悉了如何进行性能分析以及git分支管理,同时也掌握了python中的文件读取、文字切片等功能
转载于:https://www.cnblogs.com/xgxdmx/p/10644978.html

















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









