



 本文介绍了InnoDB存储引擎中缓存池的管理机制,包括LRU算法的应用、Freelist的作用及Flushlist的工作原理。详细解释了如何通过调整参数防止热点数据被误刷,以及InnoDB如何处理压缩页。
本文介绍了InnoDB存储引擎中缓存池的管理机制,包括LRU算法的应用、Freelist的作用及Flushlist的工作原理。详细解释了如何通过调整参数防止热点数据被误刷,以及InnoDB如何处理压缩页。
关于 LRU_List ,Free_List,Flush_List的介绍:
LRU算法:(Latest Recent Used)最近最少使用
数据库的缓冲池通过LRU算法来进行管理。
即,最频繁使用的页在LRU列表的前端,最少使用的页在LRU列表的尾端。当缓冲不能存放新读取到的页时,首先释放LRU列表尾端的页。
InnoDB存储引擎中,缓冲池中页默认大小16KB,也通过LRU列表对缓冲池进行管理,并对传统的LRU算法做了优化。在LRU列表中加入了midpoint位置。
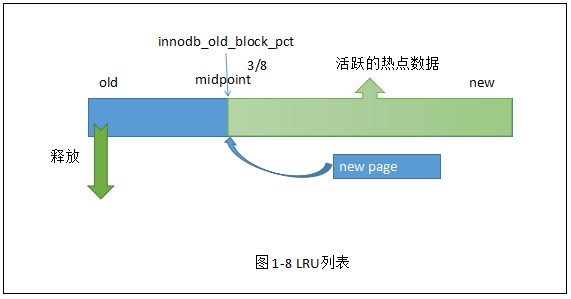
midpoint位置设置:innodb_old_block_pct 默认:37 也就是3/8位置
midpoint之前的称为:new列表,之后的称为:old列表。
问题 1:为什么不将读取的页放入到LRU列表的首部?
答:LRU列表,当不能存放新读取的页时,会释放尾部的页。若直接插入首部位置,某些SQL操作会使缓冲池中的页被刷新出去,尤其是读取大量的新页,直接插入首部,会使活跃的页逐渐被刷新出去。比如:索引或数据的全表扫描。这些页可能只在这次中用,但是活跃的页被刷新出去,下次读取该页,需要再次访问磁盘。
问题 2:解决类似全表扫描操作时,LRU列表中热点数据不被刷出
答:设置参数:innodb_old_block_time:表示页读取到mid位置后需要等待多久才会被加入到LRU列表的热端。
设置参数:innodb_old_block_pct :通过预估热点数据百分比。37-->20,降低mid位置,增加热点范围。
Free list:
LRU管理已经读取的页,数据库启动时,LRU列表是空的,没有页。此时的页都放在Free list。当需要从缓冲池中分页时,先查看Free list是否有空闲的页,若有,则从Free list中删除该页,放入到LRU列表。
若没有,则根据LRU算法,释放LRU列表尾端的页,将该内存分给新页。
page made young :当页从LRU列表的old部分加入到new部分时,此时的操作称为:page made young
page not made young:因为innodb_old_block_time设置,导致页没有从old部分移动到new部分的操作称为:page not made young。
如图:
mysql>SHOW ENGINE INNODB STATUS\G
---BUFFER POOL 3
Buffer pool size 204799 # *16KB
Buffer pool size, bytes 3355426816
Free buffers 1024
Database pages 193488
Old database pages 145096
Modified db pages 414
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 12977471, not young 326415366
Database pages :表示LRU列表中页的个数
Database pages + Free buffers <Buffer pool size
缓冲池中的页 可能分配给:自适应哈希索引,lock信息,insert buffer等页,这些页不需要LRU算法运行维护,因此不在LRU列表中。
缓冲池的运行状态:
1.
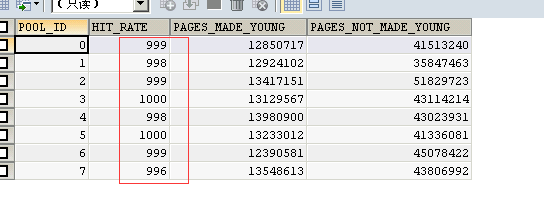
SELECT POOL_ID,HIT_RATE,PAGES_MADE_YOUNG,PAGES_NOT_MADE_YOUNG FROM `information_schema`.`INNODB_BUFFER_POOL_STATS`;
mysql>SHOW ENGINE INNODB STATUS\G
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 12977554, not young 326416098
0.00 youngs/s, 0.00 non-youngs/s
Pages read 3489114, created 521364, written 31146169
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 193491, unzip_LRU len: 0
I/O sum[1]:cur[0], unzip sum[0]:cur[0]
2.通过INNODB_BUFFER_PAGE_LRU表查看LRU中每个页的状态
LRU中对于页的处理:
InnoDB存储引擎1.0.x版本开始支持压缩页的功能,即将16KB的页压缩成:1KB,2KB,4KB,8KB.
页的大小发生变化,LRU的管理页变。
非16KB的页,用unzip_LRU列表进行管理。
mysql>SHOW ENGINE INNODB STATUS\G
LRU len: 193491, unzip_LRU len: 0
I/O sum[1]:cur[0], unzip sum[0]:cur[0]
---LRU len:所有的页,包括压缩页。
---LRU len = unzip_LRU len + 非压缩页
表页的压缩比例不同,unzip_LRU是怎么从缓冲池中分配内存的?
答:unzip_LRU也是有自己的分类的,根据1,2,4,8分类。
unzip_LRU列表对不同压缩页大小的页进行分别管理。其次通过伙伴算法进行内存的分配:以4KB为例
1)检查4KB的unzip_LRU列表,是否有可用的空闲页
2)若有,直接使用
3)否则,检查8KB的unzip_LRU列表
4)若能得到空闲页,将页分成2个4KB页,存放到4KB的unzip_LRU列表中。
5)若不能得到,从LRU列表中申请16KB的页,将页分成1个8KB,2个4KB,分别放在对应的unzip_LRU中。
Flush list
在LRU列表中的页被修改后,称该页为脏页(dirty page),即缓冲池中的页和磁盘上的页数据不一致。这时会通过checkpoint机制将脏页刷新回磁盘,而Flush list中的页即为脏页列表。
注:脏页既存在于LRU列表,也存在于Flush列表中。
LRU:用来管理缓冲池中页的可用性
Flush:用来管理将页刷新回磁盘。
mysql>SHOW ENGINE INNODB STATUS\G
---BUFFER POOL 3
Buffer pool size 204799 # *16KB
Buffer pool size, bytes 3355426816
Free buffers 1024
Database pages 193488
Old database pages 145096
Modified db pages 414 #显示脏页的数量
--ok

















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









