



 本文介绍如何在Windows环境下正确安装和使用PySpark 2.3,避免使用可能存在问题的2.4版本。文章提供了Py4J作为Python与Java间桥梁的详细资源链接,包括访问Java集合和数组的方法。同时,推荐使用OpenJDK 11以确保环境兼容性和稳定性。
本文介绍如何在Windows环境下正确安装和使用PySpark 2.3,避免使用可能存在问题的2.4版本。文章提供了Py4J作为Python与Java间桥梁的详细资源链接,包括访问Java集合和数组的方法。同时,推荐使用OpenJDK 11以确保环境兼容性和稳定性。
注意pysparlk2.4在windows上可能有问题,请用2.3
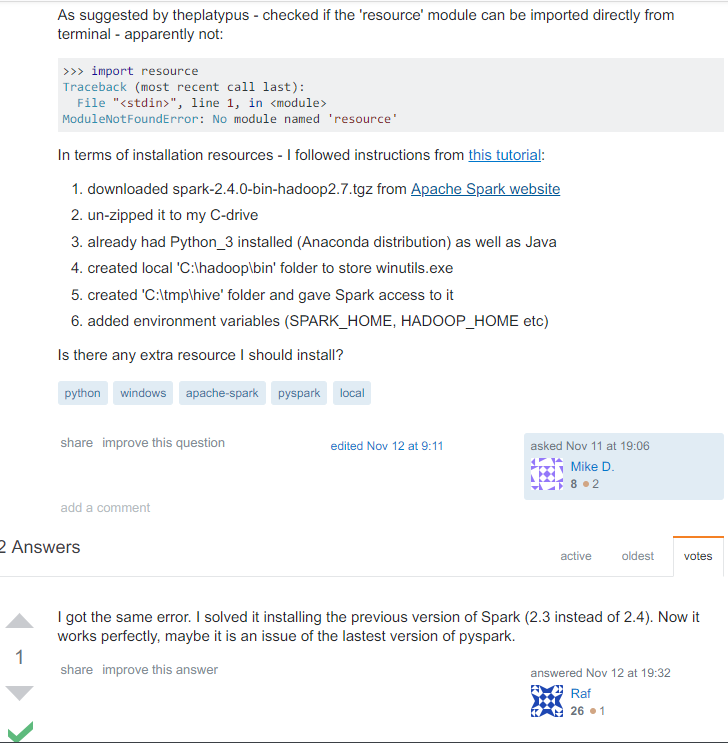
py4j python 和 java 沟通的桥梁
https://www.py4j.org/advanced_topics.html#accessing-java-collections-and-arrays-from-python
https://www.jianshu.com/p/013fe44422c9?from=timeline&isappinstalled=0
https://raufer.github.io/2018/02/08/custom-spark-models-with-python-wrappers/
openjdk
http://jdk.java.net/11/

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









