




















The Unknow Word
| The First Column | The Second Column |
|---|---|
| thume |
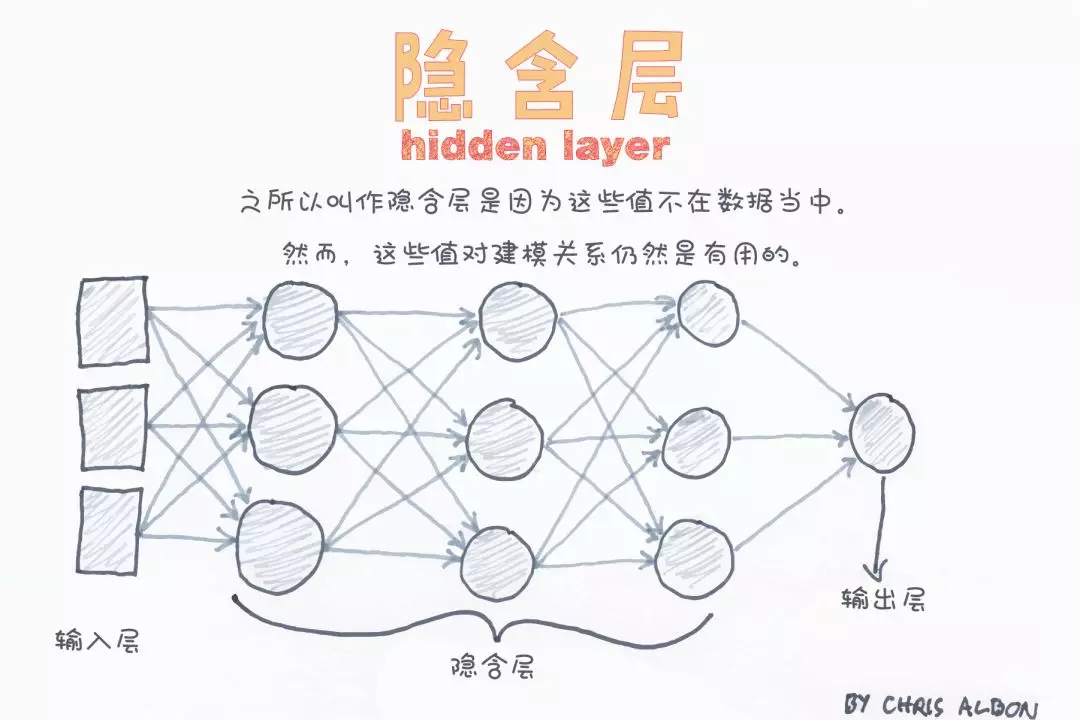
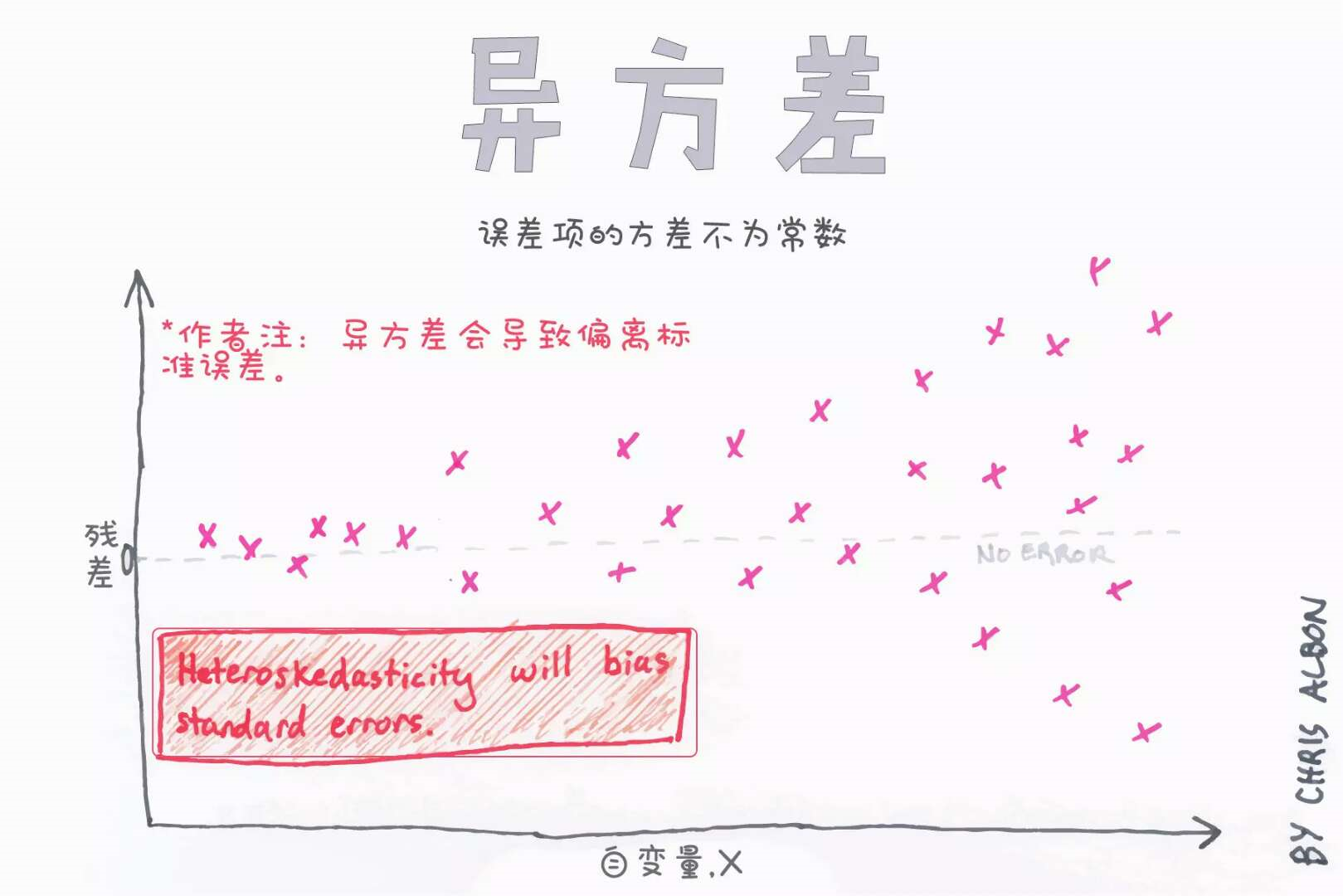
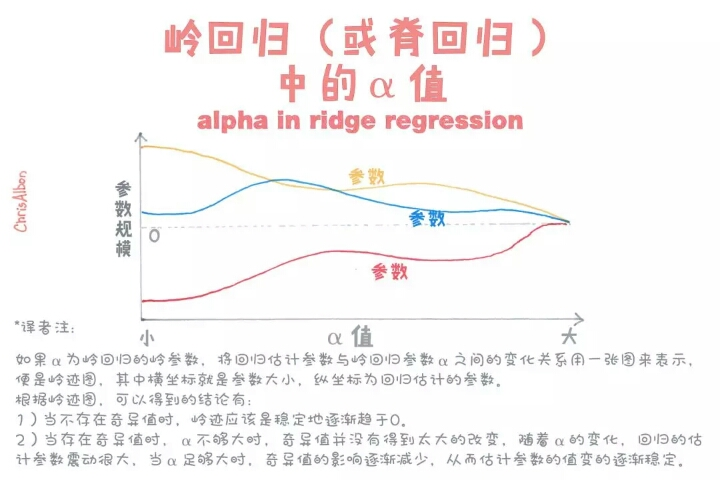
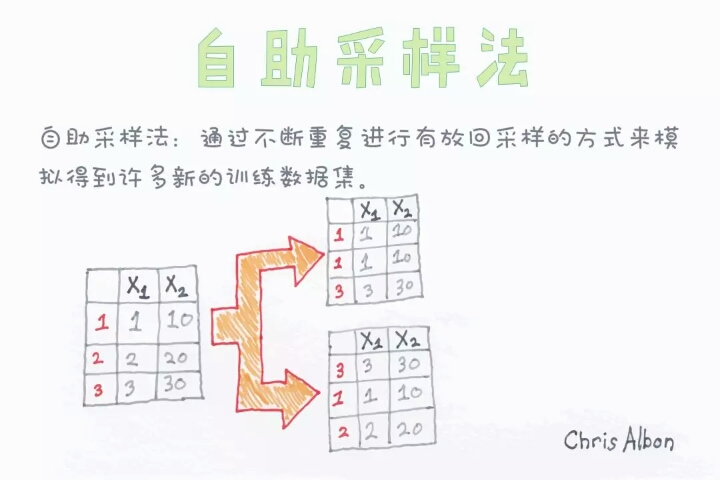
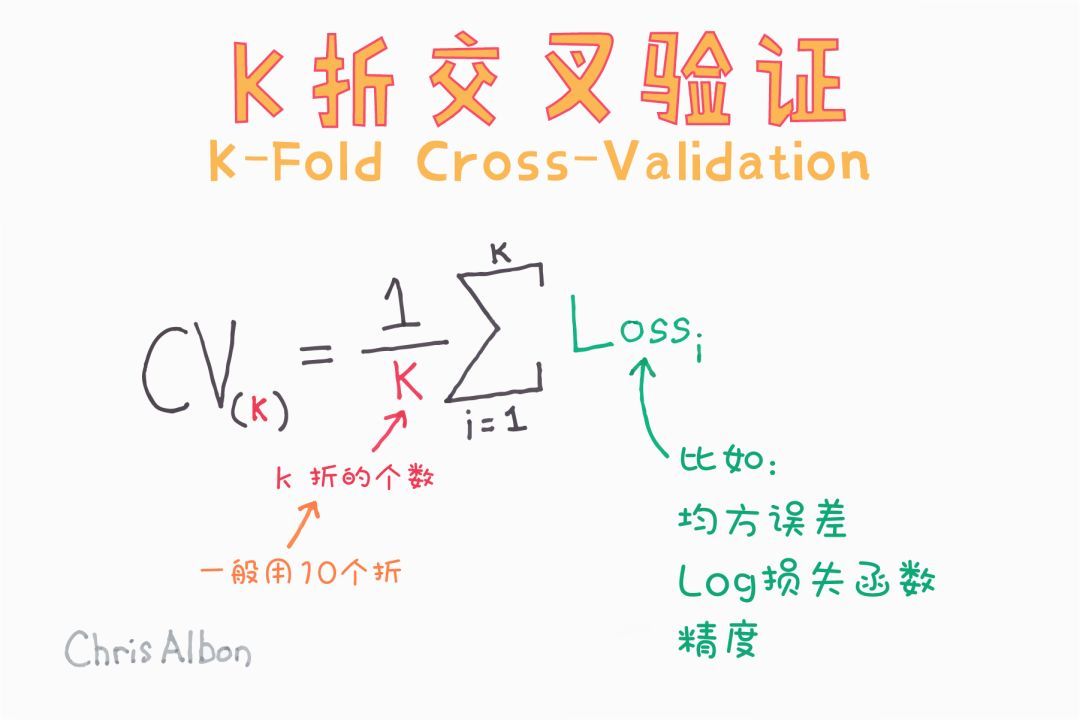
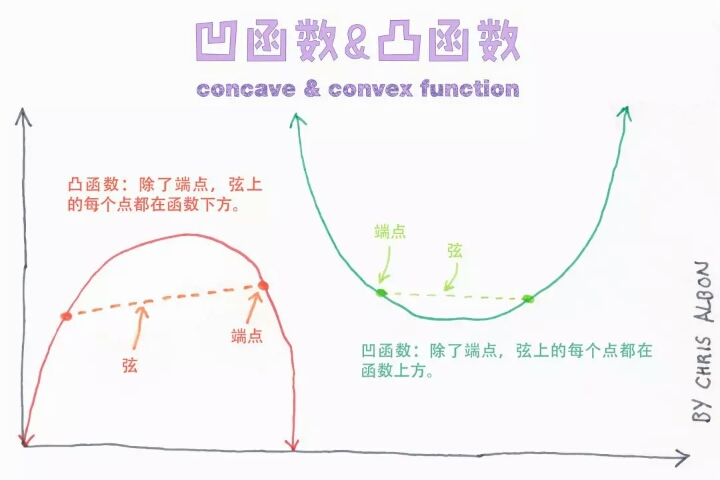
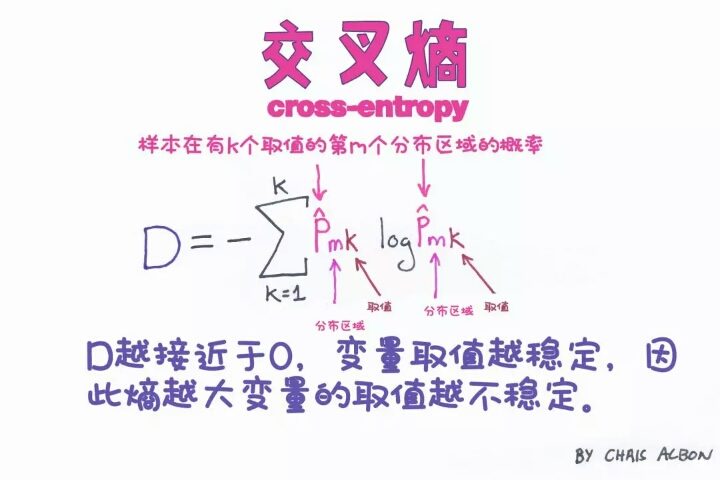
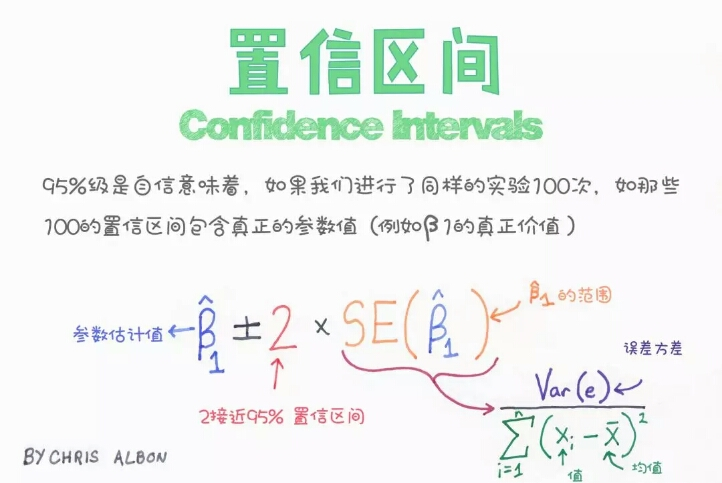
 本文深入探讨了机器学习中的关键概念和技术,包括隐藏层、异方差性、海森矩阵等数学基础,以及超参数调优、如何选择隐藏单元激活函数等实践技巧。此外还涉及了偏差-方差权衡、岭回归中的alpha参数、自助法等内容。
本文深入探讨了机器学习中的关键概念和技术,包括隐藏层、异方差性、海森矩阵等数学基础,以及超参数调优、如何选择隐藏单元激活函数等实践技巧。此外还涉及了偏差-方差权衡、岭回归中的alpha参数、自助法等内容。
| The First Column | The Second Column |
|---|---|
| thume |
转载于:https://www.cnblogs.com/hugeng007/p/9459682.html

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























