 永磁同步电机转子位置检测
永磁同步电机转子位置检测




 本文介绍了一种用于确定永磁同步电机初始转子位置的方法,该方法通过施加特定电压向量来测量d轴电流,并利用傅立叶级数提高位置检测精度,从而实现电机的有效启动。
本文介绍了一种用于确定永磁同步电机初始转子位置的方法,该方法通过施加特定电压向量来测量d轴电流,并利用傅立叶级数提高位置检测精度,从而实现电机的有效启动。
4.1 永磁式同步馬達初始轉子位置檢出之簡介
永磁同步馬達在使用向量控制時必須控制其激磁電流id及轉矩電流iq,並將激
磁電流直接控制為零,便可使定子電流向量全部置於 q 軸上,如此可得到最大的
轉矩/定子電流比,然而永磁同步馬達的 d 軸與永久磁鐵之磁軸重疊,故量測轉軸
角度就可以得到磁軸位置以決定同步旋轉座標位置;因此在初始啟動時必須知道
磁軸位置才可以順利啟動馬達,初始磁軸位置的檢出方式有使用Hall sensor、絕對
型編碼器或是解角器,然而Hall sensor有時會有機構上的限制,絕對型編碼器或是
解角器則有成本上的壓力,而一般使用之增量型編碼器在斷電後無法得知磁軸位
置,因此提出初始轉子檢出之方法。
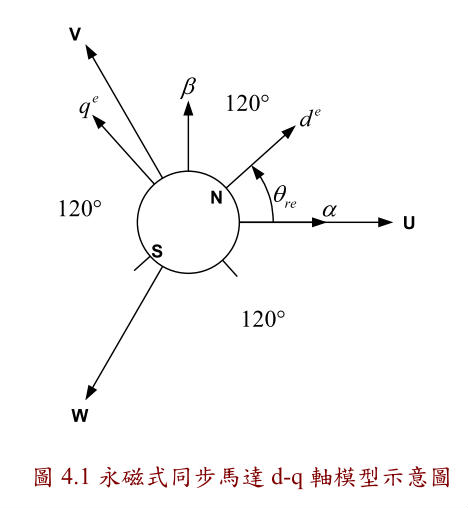
圖4.1為永磁同步馬達的d-q軸模型示意圖,α-β直角座標為定子靜子參考座
標, de - qe 為同步旋轉座標,其中 ed 是與永久磁石的N級磁軸重疊,
θre為轉子的位置。
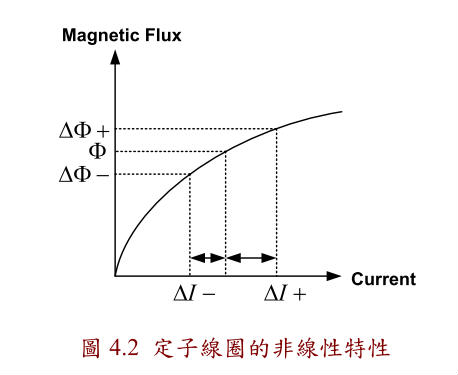
利用永磁馬達的定子因受永久磁鐵磁化而表現出的非線性特性[11](圖4.2)來
估測永久磁鐵的位置,在接近永久磁石磁軸的定子鐵心因為永磁會被強烈地磁
化,而不在磁軸位置上的定子鐵心就不會受到強烈的磁化,因為定子鐵心會有磁
飽和的現象,所以可以利用比較定子電流的絕對大小來檢測永久磁石N級的位置。
4.2 轉子位置檢出之方法
轉子位置檢出方法分成三個處理程序,第一個程序使用12個不同方向相同大
小的測試電壓向量依照編號(1→2→3→…→12)如圖4.3送到馬達的定子上,且每送
一個電壓向量維持 100 us,然後將變頻器關閉等待電流下降到零,量測d軸電流的
最大值,將12個電壓向量送完後在比對每個電壓向量d軸電流的最大值,比對出電
流最大的電壓向量位置即為最接近永久磁鐵N極的位置[11],[12](圖4.4)。
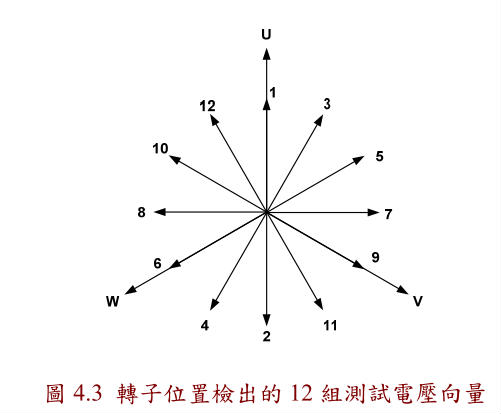
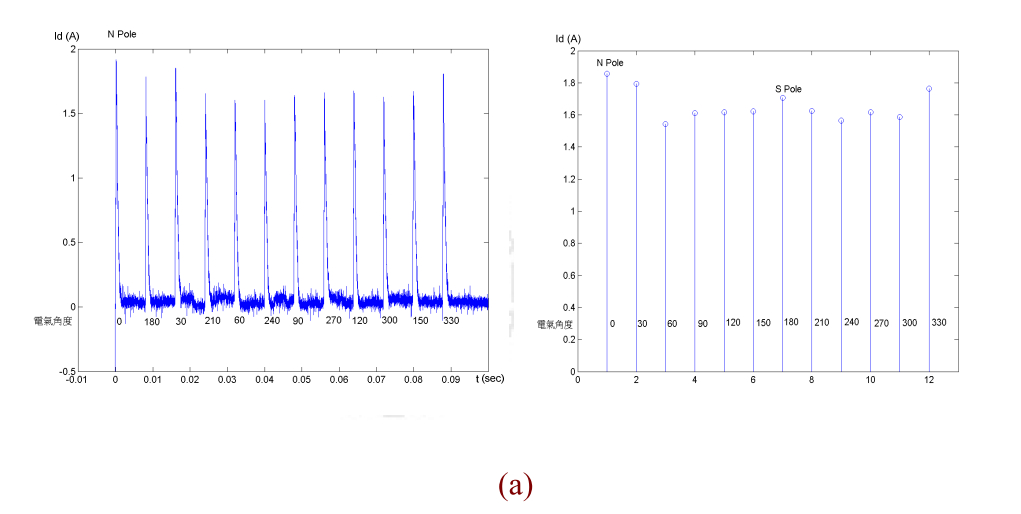
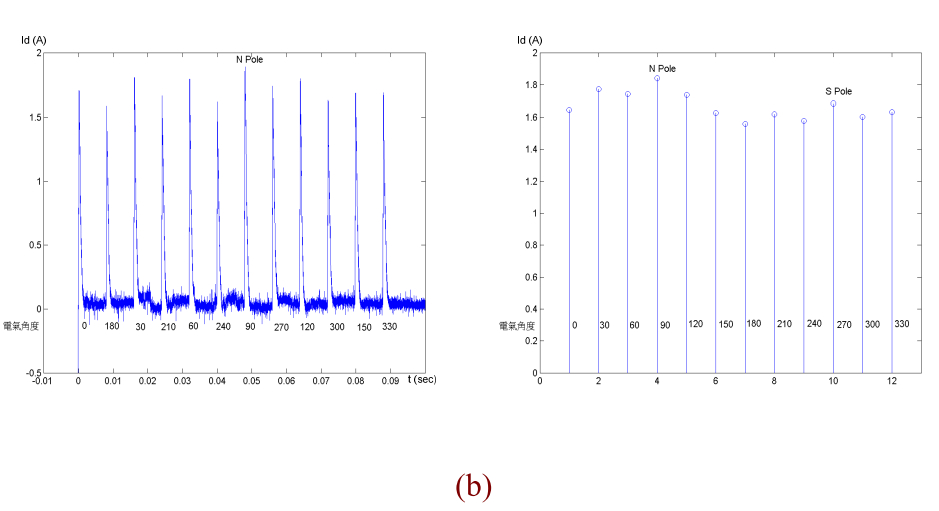
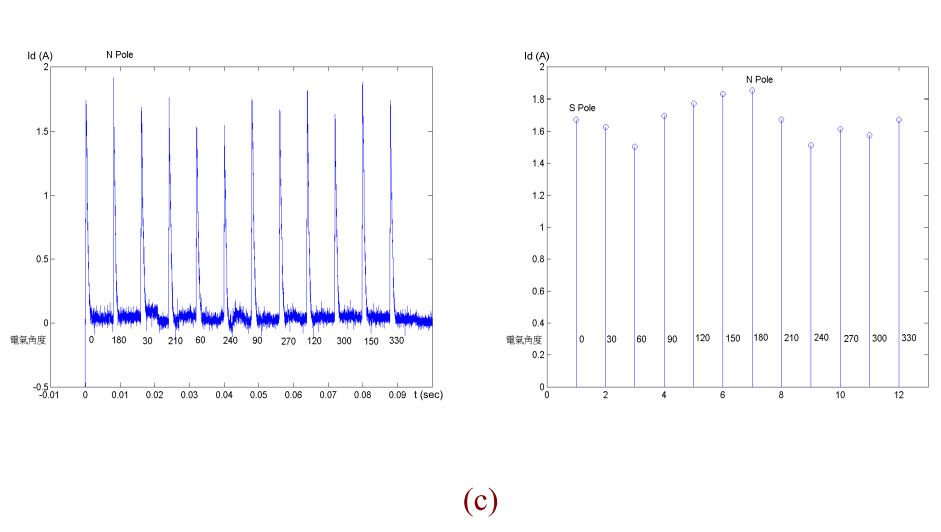
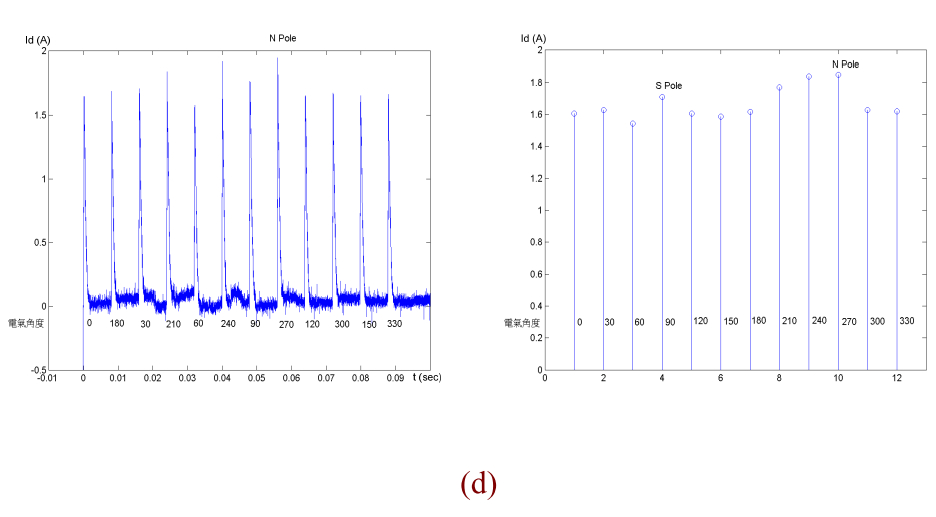
圖 4.4 12 組電壓向量之 d 軸電流量測結果,電壓向量為 250V,維持 100 us,關閉700 us
(a) N pole 在 0° (b) N pole 在 90° (c) N pole 在 180° (d) N pole 在 270°
第一個程序可以找出磁鐵的大約位置,解析度為30°電氣角,此時永磁馬達已
可以順利起動,圖4.5為實際量測之啟動暫態,在一樣的條件下我們發現馬達的啟
動電流會有所不一,其原因是因為由第一個程序找出的N極位置解析度較低,因此
為了使馬達有更好的轉矩/定子電流比;因此加入第二個程序以增加解析度。
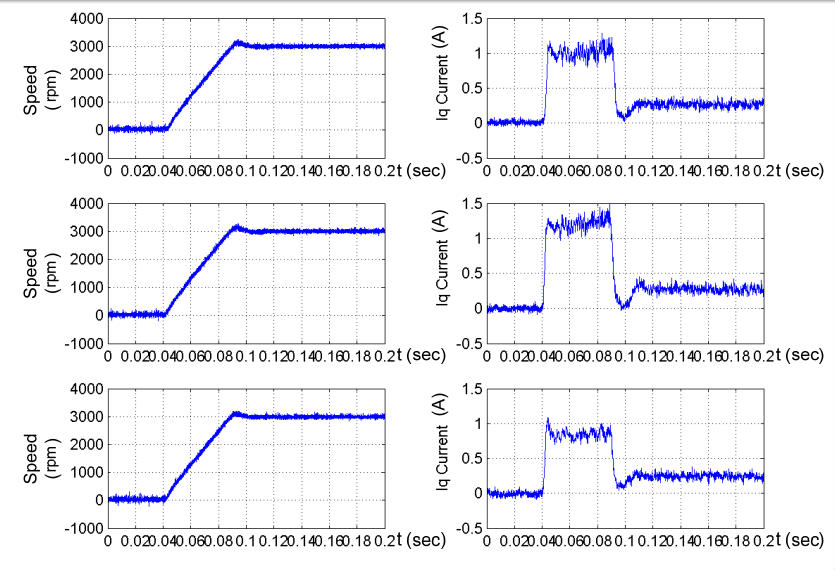
圖 4.5 實際量測驅動器送電後馬達啟動暫態,馬達為空載,0.05 秒加速至 3000rpm
第二個程序的方法係利用每次收集d軸電流的最大值其大小變化隨著永磁N極
的位置成週期性的變化,因此可以利用傅立葉級數,經由不同振幅及頻率的正弦
(sin)與餘弦(cos)所組合的函數可以擬合出沒有資料的資料點,以改善解析度的問題。
圖4.6為將d軸電流的12點資料點經由傅立葉級數擬合後的樣子,接下來只要尋
找最大值即可得知永磁N極的位置。
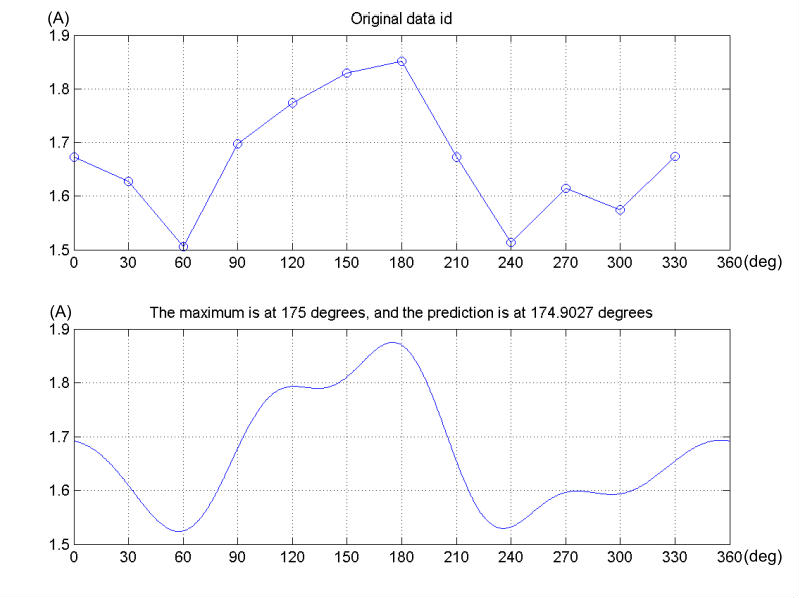
圖 4.6 經由傅立葉級數擬合之曲線,上為原始資料,下為擬合後之曲線
4.3 實驗結果
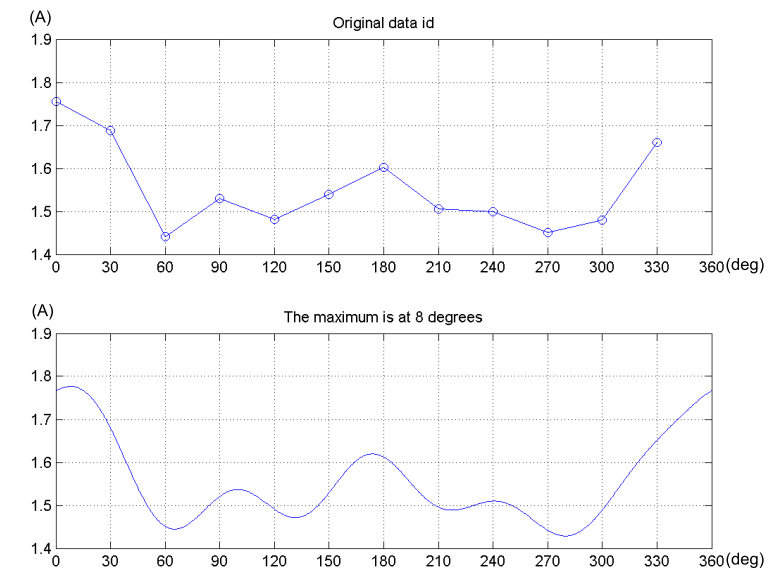
圖 4.7 估測轉子為 8°的量測結果
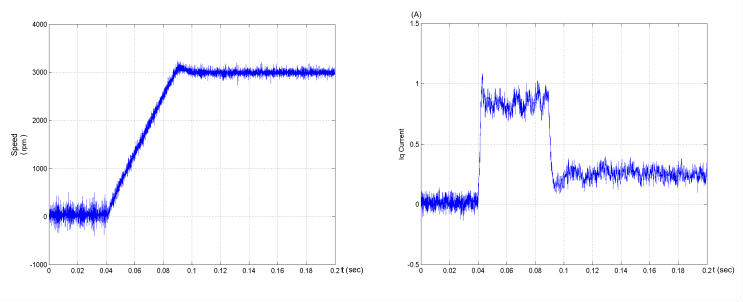
圖 4.8 估測轉子為 8°的啟動暫態,馬達為空載,0.05 秒加速至 3000rpm
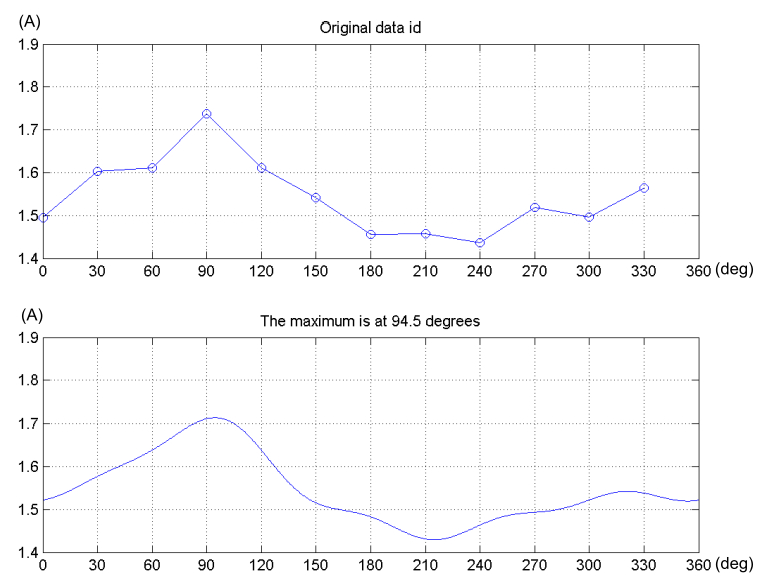
圖 4.9 估測轉子為 94.5°的量測結果
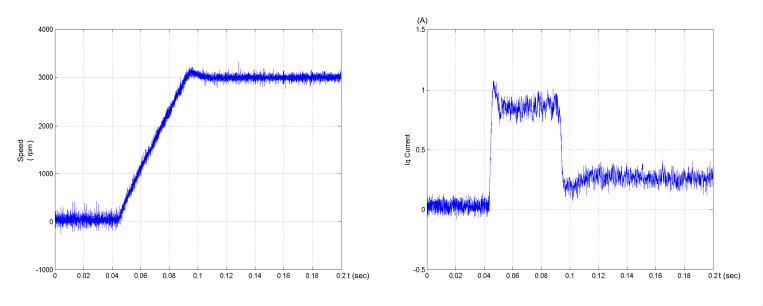
圖 4.10 估測轉子為 94.5°的啟動暫態,馬達為空載,0.05 秒加速至 3000rpm
圖 4.11 估測轉子為 177°的量測結果
圖 4.12 估測轉子為 177°的啟動暫態,馬達為空載,0.05 秒加速至 3000rpm
圖 4.13 估測轉子為 299°的量測結果
圖 4.14 估測轉子為 299°的啟動暫態,馬達為空載,0.05 秒加速至 3000rpm
圖 4.15 估測轉子為 358.5°的量測結果
圖 4.14 估測轉子為 299°的啟動暫態,馬達為空載,0.05 秒加速至 3000rpm
由以上實驗結果,可以發現在不同角度,馬達都可以快速啟動,且藉由觀察
啟動電流發現,其電流比沒有做傅立葉級數擬合穩定許多,不會忽大忽小,其解
析度的確比較好,可獲得較好的轉矩/定子電流比。
永磁同步馬達之初始轉子位置估測與向控制器之研製 傅家興

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









