



1.把所有姓李的人都改成姓张的. update xingming set name='张'+substring(name,2,len(name)-1) where left(name,1)='李'
或者
update xingming set name='张'+substring(name,2,len(name)-1) where charindex('李',name)=1
注意不要写成这样:
update xingming set name=replace(name,'李','张')
如果有人叫'李小李',则会被无情地改为'张小张'.
2.
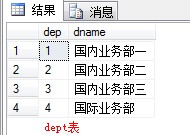
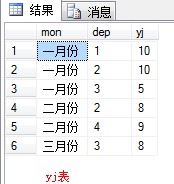
把这两个表的数据用以这种方式现实:
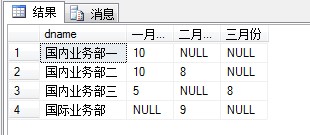
select dname,b.yj 一月份,c.yj 二月份,d.yj 三月份 from dept a left join yj b on a.dep=b.dep and b.mon='一月份' left join yj c on a.dep = c.dep and c.mon='二月份' left join yj d on a.dep = d.dep and d.mon='三月份'
3.
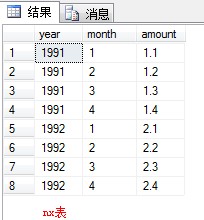 查询显示结果为:
查询显示结果为: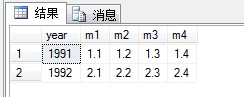
select a.year,a.m1,b.m2,c.m3,d.m4 from (select year,amount m1 from nx where month=1) a, (select year,amount m2 from nx where month=2) b, (select year,amount m3 from nx where month=3) c, (select year,amount m4 from nx where month=4) d where a.year=b.year and a.year=c.year and a.year=d.year
看查询结果分析语句应怎么写,不要在意显示结果的列名.列名可以是别名.
带Null值的,一定是有左外连接或者右外链接的.而且不用group by 因为不断拿左表当比对,右表不会多于左表,所以不会重复.
count(yilie) 和count同时被查询的列一定要在聚合函数中的.
replace可以嵌套. replace(列,要被替换内容,被替换成的内容)
一般大家都会写成这样:select * from Production.Document where DocumentSummary like'%bicycle%'了解这个函数以后,大家可以这样写:select * from Production.Document where charindex('bicycle',DocumentSummary)>0 这种方法比like'%%'的形式速度上要快很多.

















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









